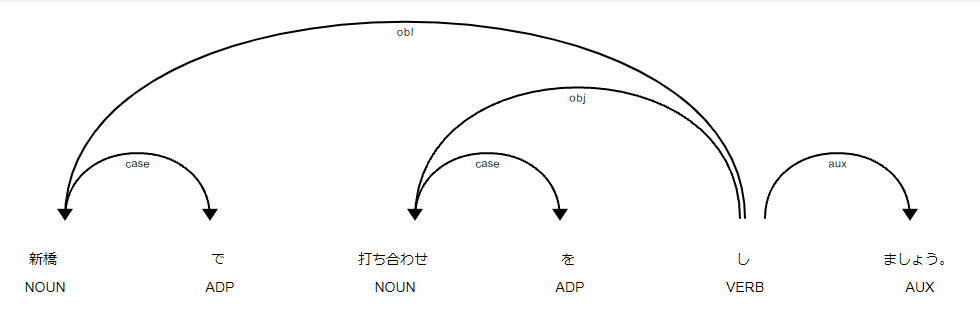
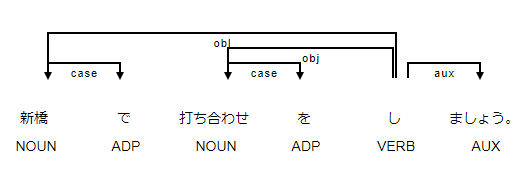
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
| 10/06/2021 11:45:03 - WARNING - __main__ - Process rank: -1, device: cuda:0, n_gpu: 1distributed training: False, 16-bits training: False
10/06/2021 11:45:03 - INFO - __main__ - Training/evaluation parameters Seq2SeqTrainingArguments(output_dir='output/', overwrite_output_dir=False, do_train=True, do_eval=True, do_predict=False, evaluation_strategy=<IntervalStrategy.NO: 'no'>, prediction_loss_only=False, per_device_train_batch_size=2, per_device_eval_batch_size=2, per_gpu_train_batch_size=None, per_gpu_eval_batch_size=None, gradient_accumulation_steps=1, eval_accumulation_steps=None, learning_rate=5e-05, weight_decay=0.0, adam_beta1=0.9, adam_beta2=0.999, adam_epsilon=1e-08, max_grad_norm=1.0, num_train_epochs=10.0, max_steps=-1, lr_scheduler_type=<SchedulerType.LINEAR: 'linear'>, warmup_ratio=0.0, warmup_steps=0, logging_dir='runs/Oct06_11-45-03_2d9fb230d52a', logging_strategy=<IntervalStrategy.STEPS: 'steps'>, logging_first_step=False, logging_steps=100, save_strategy=<IntervalStrategy.STEPS: 'steps'>, save_steps=5000, save_total_limit=3, no_cuda=False, seed=42, fp16=False, fp16_opt_level='O1', fp16_backend='auto', fp16_full_eval=False, local_rank=-1, tpu_num_cores=None, tpu_metrics_debug=False, debug=False, dataloader_drop_last=False, eval_steps=100, dataloader_num_workers=0, past_index=-1, run_name='output/', disable_tqdm=False, remove_unused_columns=True, label_names=None, load_best_model_at_end=False, metric_for_best_model=None, greater_is_better=None, ignore_data_skip=False, sharded_ddp=[], deepspeed=None, label_smoothing_factor=0.0, adafactor=False, group_by_length=False, report_to=['tensorboard'], ddp_find_unused_parameters=None, dataloader_pin_memory=True, skip_memory_metrics=False, sortish_sampler=False, predict_with_generate=True)
Using custom data configuration default
Reusing dataset csv (/root/.cache/huggingface/datasets/csv/default-2359a64c962f9aac/0.0.0/2960f95a26e85d40ca41a230ac88787f715ee3003edaacb8b1f0891e9f04dda2)
loading configuration file https://huggingface.co/sonoisa/t5-base-japanese/resolve/main/config.json from cache at /root/.cache/huggingface/transformers/fb3cd498b86ea48d9c5290222d7a1b96e0acb4daa6d35a7fcb00168d59c356ee.82b38ae98529e44bc2af82ee82527f78e94856e2fb65b0ec6faecbb49d8ab639
Model config T5Config {
"_name_or_path": "/content/drive/MyDrive/T5_models/oscar_cc100_wikipedia_ja",
"architectures": [
"T5Model"
],
"bos_token_id": 0,
"d_ff": 3072,
"d_kv": 64,
"d_model": 768,
"decoder_start_token_id": 0,
"dropout_rate": 0.1,
"eos_token_id": 1,
"eos_token_ids": [
1
],
"feed_forward_proj": "relu",
"initializer_factor": 1.0,
"is_encoder_decoder": true,
"layer_norm_epsilon": 1e-06,
"max_length": 512,
"model_type": "t5",
"n_positions": 512,
"num_beams": 4,
"num_decoder_layers": 12,
"num_heads": 12,
"num_layers": 12,
"pad_token_id": 0,
"relative_attention_num_buckets": 32,
"transformers_version": "4.4.2",
"use_cache": true,
"vocab_size": 32128
}
loading configuration file https://huggingface.co/sonoisa/t5-base-japanese/resolve/main/config.json from cache at /root/.cache/huggingface/transformers/fb3cd498b86ea48d9c5290222d7a1b96e0acb4daa6d35a7fcb00168d59c356ee.82b38ae98529e44bc2af82ee82527f78e94856e2fb65b0ec6faecbb49d8ab639
Model config T5Config {
"_name_or_path": "/content/drive/MyDrive/T5_models/oscar_cc100_wikipedia_ja",
"architectures": [
"T5Model"
],
"bos_token_id": 0,
"d_ff": 3072,
"d_kv": 64,
"d_model": 768,
"decoder_start_token_id": 0,
"dropout_rate": 0.1,
"eos_token_id": 1,
"eos_token_ids": [
1
],
"feed_forward_proj": "relu",
"initializer_factor": 1.0,
"is_encoder_decoder": true,
"layer_norm_epsilon": 1e-06,
"max_length": 512,
"model_type": "t5",
"n_positions": 512,
"num_beams": 4,
"num_decoder_layers": 12,
"num_heads": 12,
"num_layers": 12,
"pad_token_id": 0,
"relative_attention_num_buckets": 32,
"transformers_version": "4.4.2",
"use_cache": true,
"vocab_size": 32128
}
loading file https://huggingface.co/sonoisa/t5-base-japanese/resolve/main/spiece.model from cache at /root/.cache/huggingface/transformers/a455eff173d5e851553673177dcb6876d5fcd0d39a4bdd7e9a75c50dfb2ab158.82c0f9a9b4ec152c1ca13afe226abd56b618ec9f9d395dc56fd3ad6ca14b4dcc
loading file https://huggingface.co/sonoisa/t5-base-japanese/resolve/main/added_tokens.json from cache at None
loading file https://huggingface.co/sonoisa/t5-base-japanese/resolve/main/special_tokens_map.json from cache at /root/.cache/huggingface/transformers/559eb952d008bbb60787ea4b89849e5a377f35e163651805b072f2fb1f4b28b9.c94798918c92ded6aeef2d2f0e666d2cc4145eca1aa6e1336fde07f2e13e2f46
loading file https://huggingface.co/sonoisa/t5-base-japanese/resolve/main/tokenizer_config.json from cache at /root/.cache/huggingface/transformers/175dd55a5be280f74e003b3b5efa1de2080efdc795da6dc013dd001d661fcb50.6de37cb3d7dbffde3a51667c5706471d3c6b2a3ff968f108c1429163c5860a5d
loading file https://huggingface.co/sonoisa/t5-base-japanese/resolve/main/tokenizer.json from cache at None
loading weights file https://huggingface.co/sonoisa/t5-base-japanese/resolve/main/pytorch_model.bin from cache at /root/.cache/huggingface/transformers/e6cfe18cc2661a1900624126a7fd3af005a942d9079fd828c4333b0f46617f58.f3773e9948a37df8ff8b19de7bdc64bbcc9fd2225fcdc41ed5a4a2be8a86f383
All model checkpoint weights were used when initializing T5ForConditionalGeneration.
All the weights of T5ForConditionalGeneration were initialized from the model checkpoint at sonoisa/t5-base-japanese.
If your task is similar to the task the model of the checkpoint was trained on, you can already use T5ForConditionalGeneration for predictions without further training.
Loading cached processed dataset at /root/.cache/huggingface/datasets/csv/default-2359a64c962f9aac/0.0.0/2960f95a26e85d40ca41a230ac88787f715ee3003edaacb8b1f0891e9f04dda2/cache-1b9264874e882057.arrow
Loading cached processed dataset at /root/.cache/huggingface/datasets/csv/default-2359a64c962f9aac/0.0.0/2960f95a26e85d40ca41a230ac88787f715ee3003edaacb8b1f0891e9f04dda2/cache-31c3668d81aead05.arrow
***** Running training *****
Num examples = 477
Num Epochs = 10
Instantaneous batch size per device = 2
Total train batch size (w. parallel, distributed & accumulation) = 2
Gradient Accumulation steps = 1
Total optimization steps = 2390
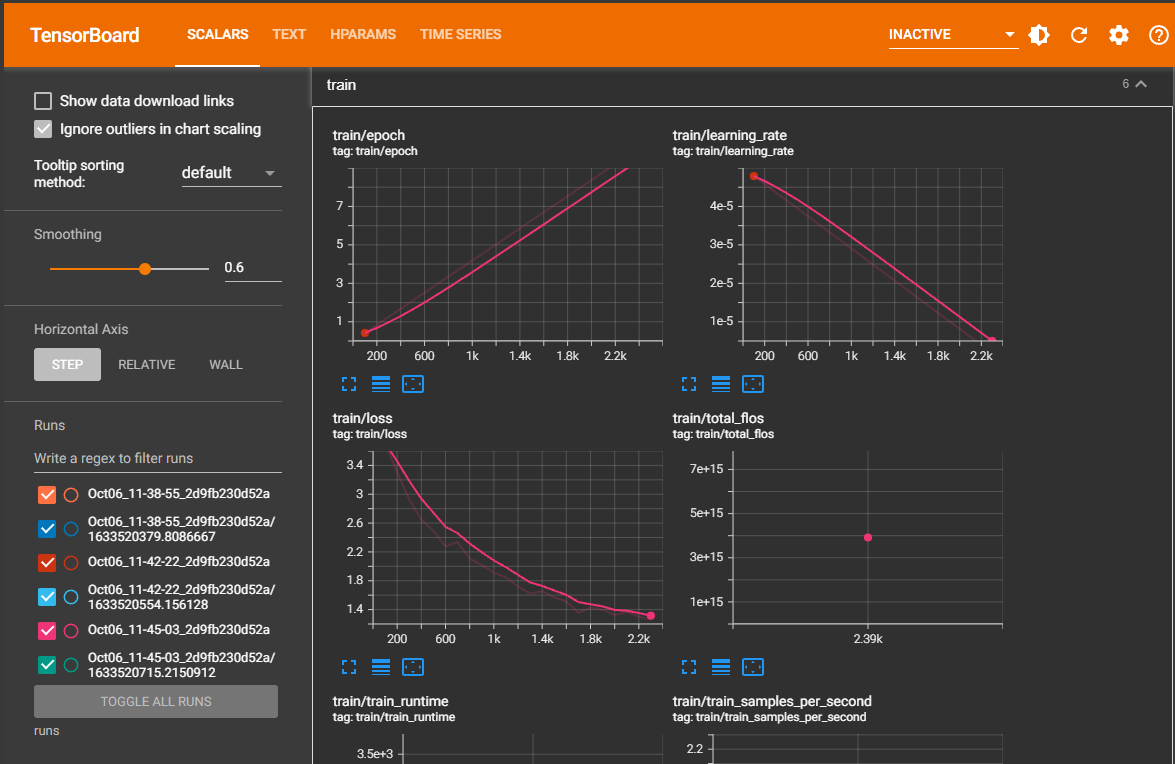
{'loss': 3.7109, 'learning_rate': 4.7907949790794984e-05, 'epoch': 0.42}
{'loss': 3.3028, 'learning_rate': 4.581589958158996e-05, 'epoch': 0.84}
{'loss': 2.9266, 'learning_rate': 4.372384937238494e-05, 'epoch': 1.26}
{'loss': 2.6457, 'learning_rate': 4.1631799163179915e-05, 'epoch': 1.67}
{'loss': 2.4916, 'learning_rate': 3.95397489539749e-05, 'epoch': 2.09}
{'loss': 2.2776, 'learning_rate': 3.744769874476988e-05, 'epoch': 2.51}
{'loss': 2.3356, 'learning_rate': 3.5355648535564854e-05, 'epoch': 2.93}
{'loss': 2.1054, 'learning_rate': 3.3263598326359835e-05, 'epoch': 3.35}
{'loss': 2.0186, 'learning_rate': 3.117154811715482e-05, 'epoch': 3.77}
{'loss': 1.9114, 'learning_rate': 2.9079497907949792e-05, 'epoch': 4.18}
{'loss': 1.8481, 'learning_rate': 2.6987447698744773e-05, 'epoch': 4.6}
{'loss': 1.7216, 'learning_rate': 2.489539748953975e-05, 'epoch': 5.02}
{'loss': 1.6217, 'learning_rate': 2.280334728033473e-05, 'epoch': 5.44}
{'loss': 1.6558, 'learning_rate': 2.0711297071129708e-05, 'epoch': 5.86}
{'loss': 1.5691, 'learning_rate': 1.8619246861924686e-05, 'epoch': 6.28}
{'loss': 1.5122, 'learning_rate': 1.6527196652719665e-05, 'epoch': 6.69}
{'loss': 1.3568, 'learning_rate': 1.4435146443514645e-05, 'epoch': 7.11}
{'loss': 1.4267, 'learning_rate': 1.2343096234309625e-05, 'epoch': 7.53}
{'loss': 1.3995, 'learning_rate': 1.0251046025104603e-05, 'epoch': 7.95}
{'loss': 1.3224, 'learning_rate': 8.158995815899583e-06, 'epoch': 8.37}
{'loss': 1.3677, 'learning_rate': 6.066945606694561e-06, 'epoch': 8.79}
{'loss': 1.3022, 'learning_rate': 3.97489539748954e-06, 'epoch': 9.21}
{'loss': 1.2621, 'learning_rate': 1.882845188284519e-06, 'epoch': 9.62}
100% 2390/2390 [33:01<00:00, 1.25it/s]
Training completed. Do not forget to share your model on huggingface.co/models =)
{'train_runtime': 1981.4145, 'train_samples_per_second': 1.206, 'epoch': 10.0}
100% 2390/2390 [33:01<00:00, 1.21it/s]
Saving model checkpoint to output/
Configuration saved in output/config.json
Model weights saved in output/pytorch_model.bin
tokenizer config file saved in output/tokenizer_config.json
Special tokens file saved in output/special_tokens_map.json
Copy vocab file to output/spiece.model
***** train metrics *****
epoch = 10.0
init_mem_cpu_alloc_delta = 1MB
init_mem_cpu_peaked_delta = 0MB
init_mem_gpu_alloc_delta = 850MB
init_mem_gpu_peaked_delta = 0MB
train_mem_cpu_alloc_delta = 0MB
train_mem_cpu_peaked_delta = 0MB
train_mem_gpu_alloc_delta = 2575MB
train_mem_gpu_peaked_delta = 5616MB
train_runtime = 1981.4145
train_samples = 477
train_samples_per_second = 1.206
10/06/2021 12:18:20 - INFO - __main__ - *** Evaluate ***
***** Running Evaluation *****
Num examples = 120
Batch size = 2
/usr/local/lib/python3.7/dist-packages/torch/_tensor.py:575: UserWarning: floor_divide is deprecated, and will be removed in a future version of pytorch. It currently rounds toward 0 (like the 'trunc' function NOT 'floor'). This results in incorrect rounding for negative values.
To keep the current behavior, use torch.div(a, b, rounding_mode='trunc'), or for actual floor division, use torch.div(a, b, rounding_mode='floor'). (Triggered internally at /pytorch/aten/src/ATen/native/BinaryOps.cpp:467.)
return torch.floor_divide(self, other)
100% 60/60 [01:37<00:00, 1.62s/it]
***** eval metrics *****
epoch = 10.0
eval_gen_len = 16.7333
eval_loss = 2.6638
eval_mem_cpu_alloc_delta = 2MB
eval_mem_cpu_peaked_delta = 0MB
eval_mem_gpu_alloc_delta = 0MB
eval_mem_gpu_peaked_delta = 1227MB
eval_rouge1 = 10.1667
eval_rouge2 = 6.3889
eval_rougeL = 10.2778
eval_rougeLsum = 10.5278
eval_runtime = 98.9901
eval_samples = 120
eval_samples_per_second = 1.212
CPU times: user 18 s, sys: 2.62 s, total: 20.7 s
Wall time: 35min 1s
|