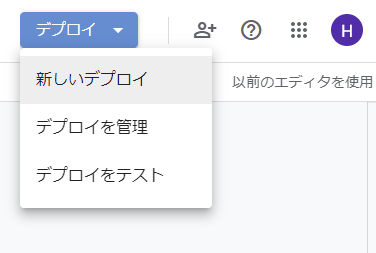
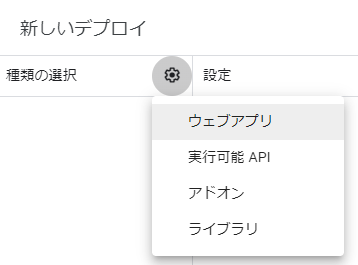
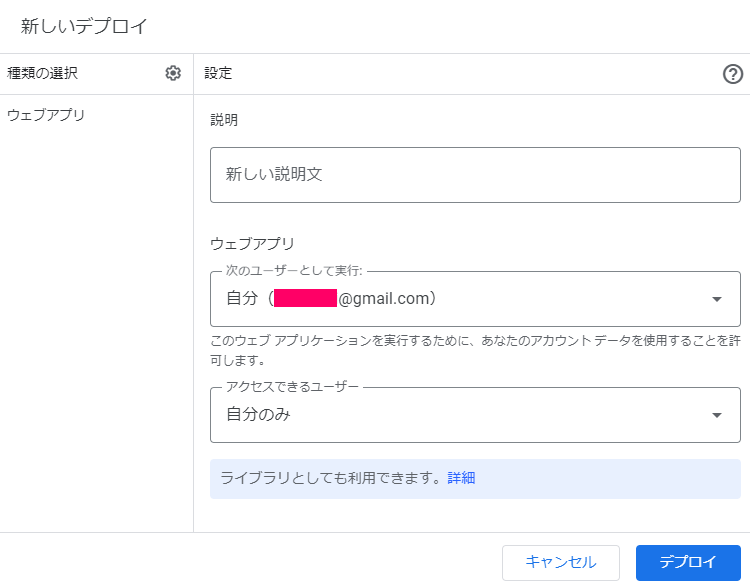
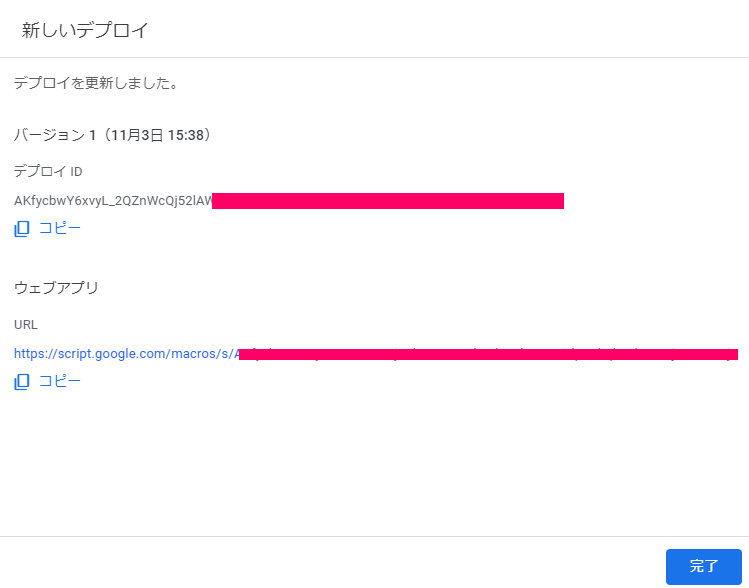
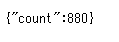Traceback (most recent call last): File "test.py", line 11, in <module> func() File "C:\Util\anaconda3\lib\site-packages\wrapt_timeout_decorator\wrapt_timeout_decorator.py", line 123, in wrapper return wrapped_with_timeout(wrap_helper) File "C:\Util\anaconda3\lib\site-packages\wrapt_timeout_decorator\wrapt_timeout_decorator.py", line 131, in wrapped_with_timeout return wrapped_with_timeout_process(wrap_helper) File "C:\Util\anaconda3\lib\site-packages\wrapt_timeout_decorator\wrapt_timeout_decorator.py", line 145, in wrapped_with_timeout_process return timeout_wrapper() File "C:\Util\anaconda3\lib\site-packages\wrapt_timeout_decorator\wrap_function_multiprocess.py", line 43, in __call__ self.cancel() File "C:\Util\anaconda3\lib\site-packages\wrapt_timeout_decorator\wrap_function_multiprocess.py", line 51, in cancel raise_exception(self.wrap_helper.timeout_exception, self.wrap_helper.exception_message) File "C:\Util\anaconda3\lib\site-packages\wrapt_timeout_decorator\wrap_helper.py", line 178, in raise_exception raise exception(exception_message) TimeoutError: Function func timed out after 30.0 seconds
function main() { var thds = GmailApp.getInboxThreads(); for (var i = 0; i < thds.length; i++) { var thd = thds[i]; var msgs = thd.getMessages(); for (var j = 0; j < msgs.length; j++) { var msg = msgs[j]; var from = msg.getFrom(); // 送信元 var to = msg.getTo(); // 送信先 var date = msg.getDate(); // 日付 var subject = msg.getSubject(); // 件名 var body = msg.getBody(); // 本文 Logger.log(from + " : " + to + " : " + date+ " : " + subject); } }
function main() { var id="********************************************"; // スプレッドシートID var spreadsheet = SpreadsheetApp.openById(id) // スプレッドシートを取得 var sheet = spreadsheet.getSheetByName("シート1") // シートを取得
function doGet(e){ // 未読件数を取得 var cnt = GmailApp.getInboxUnreadCount(); return createJson({count: cnt}); }
// JavaScriptオブジェクトをJSONに変換 function createJson(data){ var json_str = JSON.stringify(data); var mime_type = ContentService.MimeType.JSON; var json = ContentService.createTextOutput(json_str).setMimeType(mime_type); return json; }