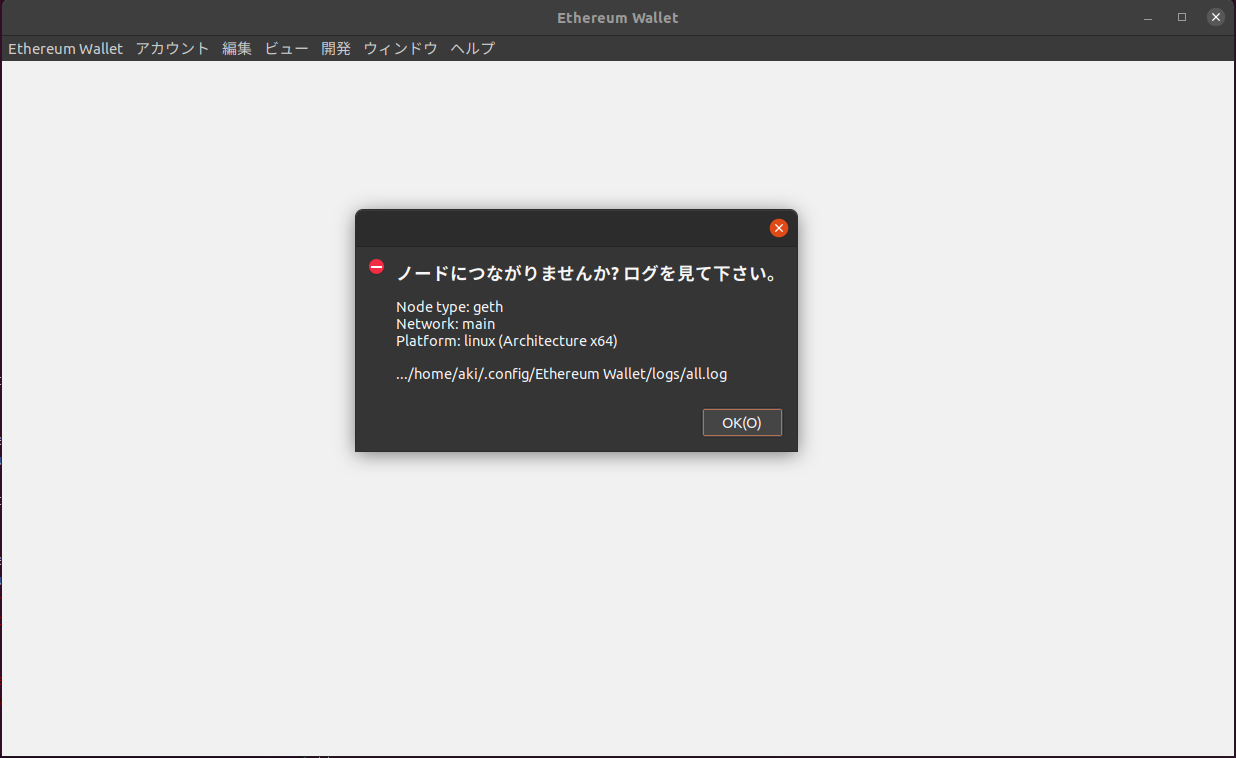
[2021-06-27T07:52:02.042] [ERROR] EthereumNode - Failed to connect to node Error: Unable to connect to socket: timeout at Timeout.setTimeout [as _onTimeout] (/home/aki/ダウンロード/wallet/resources/app.asar/modules/sockets/base.js:93:27) at ontimeout (timers.js:469:11) at tryOnTimeout (timers.js:304:5) at Timer.listOnTimeout (timers.js:264:5)
Unlock account 0xf4572ec53ab834afa1bd93a2cb32f070fda1c06c Passphrase: GoError: Error: account unlock with HTTP access is forbidden at web3.js:6357:37(47) at native at <eval>:1:24(6)
(途中略) INFO [06-23|06:42:21.095] Writing custom genesis block INFO [06-23|06:42:21.095] Persisted trie from memory database nodes=0 size=0.00B time="3.706µs" gcnodes=0 gcsize=0.00B gctime=0s livenodes=1 livesize=0.00B INFO [06-23|06:42:21.096] Successfully wrote genesis state database=chaindata hash=76d747..1a5e65 INFO [06-23|06:42:21.096] Allocated cache and file handles database=/home/aki/eth_net/geth/lightchaindata cache=16.00MiB handles=16 INFO [06-23|06:42:21.112] Writing custom genesis block INFO [06-23|06:42:21.112] Persisted trie from memory database nodes=0 size=0.00B time="2.441µs" gcnodes=0 gcsize=0.00B gctime=0s livenodes=1 livesize=0.00B INFO [06-23|06:42:21.113] Successfully wrote genesis state database=lightchaindata hash=76d747..1a5e65
最後にSuccessfully wrote genesis stateというログが表示されていれば、初期化処理は正常終了しています。
Open wallet (password: 'coz'): wallet open neo-privnet.wallet Test smart contract: sc build_run /smart-contracts/wake_up_neo.py True False False 07 05 main
Privatenet useragent '/Neo:2.10.2/', nonce: 1923845013 [I 210618 22:55:07 Settings:331] Created 'Chains' directory at /root/.neopython/Chains [I 210618 22:55:07 LevelDBBlockchain:112] Created Blockchain DB at /root/.neopython/Chains/privnet [I 210618 22:55:07 NotificationDB:73] Created Notification DB At /root/.neopython/Chains/privnet_notif NEO cli. Type 'help' to get started