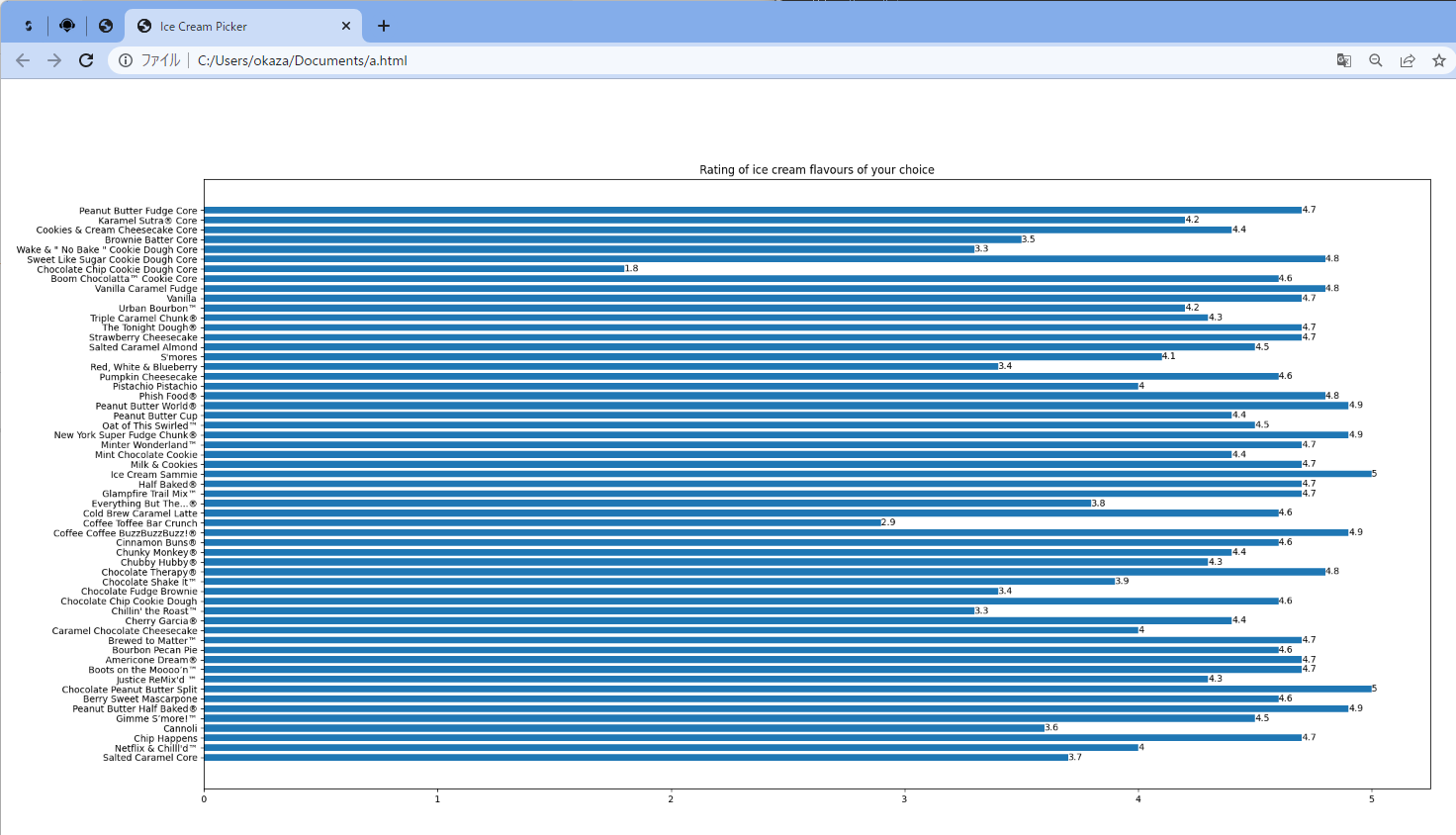
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| import heapq
def astar(edges, nodes, goal):
dist = [float('inf')] * len(nodes)
dist[0] = 0
q = []
heapq. heappush( q, [0, [0]])
while len(q) > 0:
_, u = heapq.heappop(q)
last = u[-1]
if last == goal:
return u
for i in edges[last]:
if dist[i[0]] > dist[last] + i[1]:
dist[i[0]] = dist[last] + i[1]
heapq.heappush(q, [dist[last] + i[1] + nodes[i[0]], u + [i[0]]])
return []
nodes = [ 10, 14, 10, 10, 9, 9, 5, 0, 9, 8, 6, 4, 7, 3 ]
edges = [ [[4, 1], [5, 1]],
[[2, 12], [3, 4], [4, 15]],
[[1, 12], [9, 2], [11, 6]],
[[1, 4], [5, 3], [8, 3]],
[[1, 15], [0, 1], [6, 6]],
[[0, 1], [3, 3], [6, 4]],
[[4, 6], [5, 4], [10, 1]],
[[11, 4], [13, 5]],
[[3, 3], [9, 1], [10, 5]],
[[2, 2], [8, 1], [12, 1]],
[[6, 1], [8, 5], [13, 3]],
[[2, 6], [7, 4], [12, 5]],
[[9, 1], [11, 5], [13, 6]],
[[7, 5], [10, 3], [12, 6]] ]
print('解:', astar( edges, nodes, 7))
|