振動する弦
振動する弦の問題をScipyを使用して解いてみましょう。
問題の設定:
- 長さLの均一な弦があり、一端を固定してもう一端を自由に振動させます。
- 弦の初期の形状と初速度分布が与えられ、時間とともに弦の振動が発展します。
以下はPythonコードで問題を解いて、グラフで表示する例です。
1 | import numpy as np |
このコードは、弦の振動方程式を数値的に解き、弦の振動が時間とともにどのように発展するかを示すグラフを生成します。
初期条件を与えることで、振動パターンが明確に視覚化されます。
Scipyを使用してこのような物理的な問題を解くことができます。
ソースコード解説
以下にソースコードの詳細な説明を提供します。
1. numpyとmatplotlibから必要なモジュールをインポートします。
また、物理的な問題を数値的に解くためにscipy.integrateからsolve_ivpをインポートします。
2. パラメータを設定します。
Lは弦の長さ(メートル)を示します。Tensionは弦の張力(N)を示します。Densityは弦の線密度(kg/m)を示します。cは波速度を計算するために張力と線密度から計算されます。
3. initial_condition関数は、弦の初期条件を設定します。
特定の範囲(0.2から0.4まで)で正弦波の初期変位を持ち、それ以外の位置では初期変位がゼロです。
4. 弦の振動を数値的に解くための準備を行います。
x_spanは空間座標xの範囲を示します。x_valuesはx座標の値を1000点に離散化します。initial_stateはx_valuesの各点における初期変位を計算します。
5. string_wave関数は、時間と状態(弦の変位)を受け取り、時間に対する弦の変位の微分を計算します。
これは弦の振動を記述する偏微分方程式の数値解法です。
6. solve_ivp関数を使用して弦の振動を数値的に解きます。
時間範囲は0から2.0秒までで、400の時間ステップに分割されます。
7. 結果を可視化するためのグラフを作成します。
- ループを使用して時間の異なるスナップショットをプロットし、弦の変位を表示します。
- グラフのタイトル、軸ラベル、凡例、グリッドを設定し、最終的にグラフを表示します。
このコードは、振動する弦の数値的なシミュレーションを行い、振動の進化を時間に沿って可視化するものです。
弦の初期条件や物理的なパラメータを変更することで、さまざまな振動パターンを観察できます。
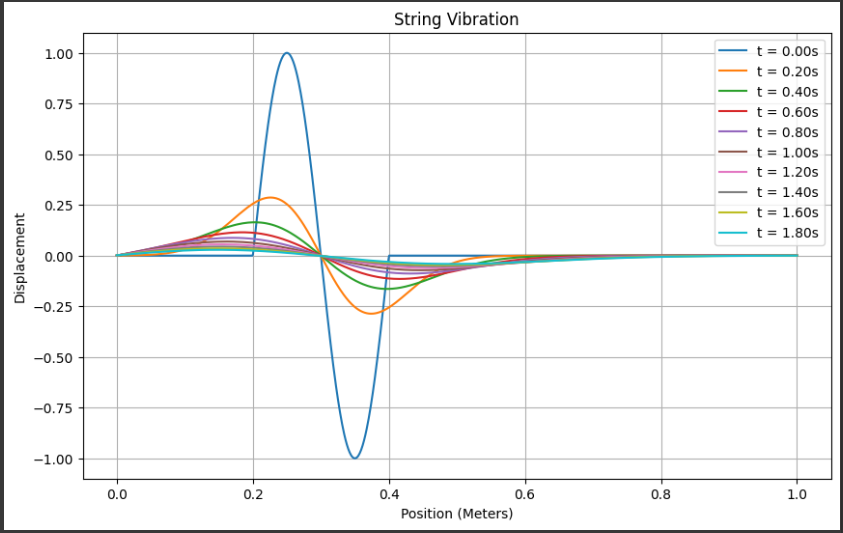
グラフ解析
生成された弦の振動グラフは、時間に対する変位(弦の形状)を示しています。
以下にグラフの詳細な説明を提供します。
x軸(位置):
グラフの横軸は、弦の長さを0から1メートル(または他の単位)にわたって示しています。
これは弦の位置を表します。y軸(変位):
グラフの縦軸は、弦の各位置での変位を示しています。
変位は振幅として解釈でき、正の値は弦が上に、負の値は弦が下に振動していることを示します。カーブ:
各カーブは異なる時間(t)での弦の形状を表しています。
t = 0から始まり、時間が経過するにつれて弦の振動が進化しています。
異なる時間点での弦の形状が示されており、これにより弦が振動し続ける様子が視覚化されています。初期条件:
初期条件は、弦の形状を決定します。
この例では、弦の一部が時間0で振動を開始しています。
具体的には、0.2から0.4までの範囲で弦が正弦波のように振動しています。
このグラフは、時間と空間における物理的な現象、つまり弦の振動を捉えたものです。
時間とともに振動がどのように変化し、初期条件に基づいて振動パターンが形成されるかを可視化しています。
振動の速さ、振幅、および周波数は、弦の特性に基づいて変化します。
グラフは、時間と空間の関係を理解するのに役立ちます。