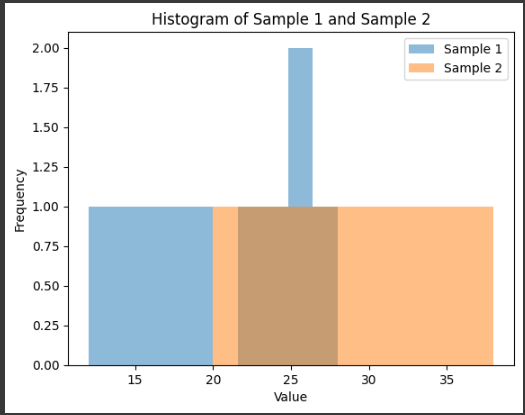
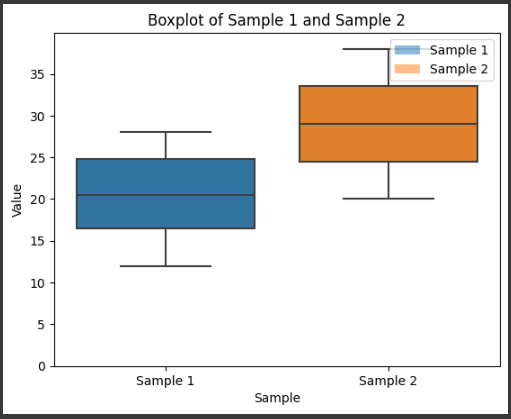
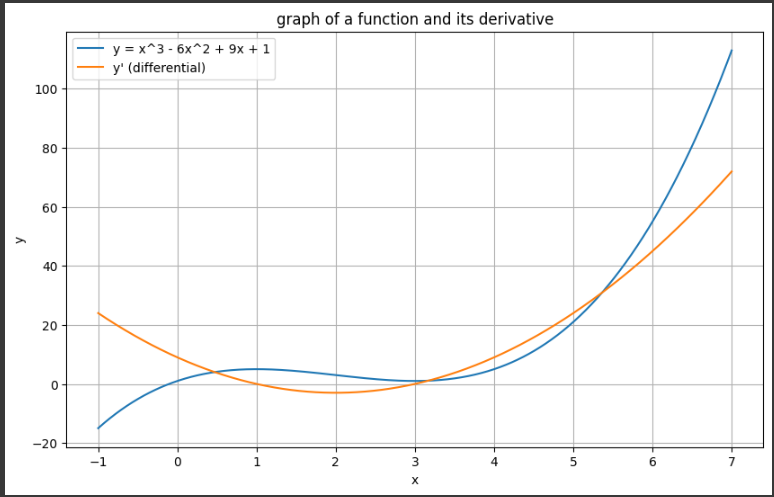
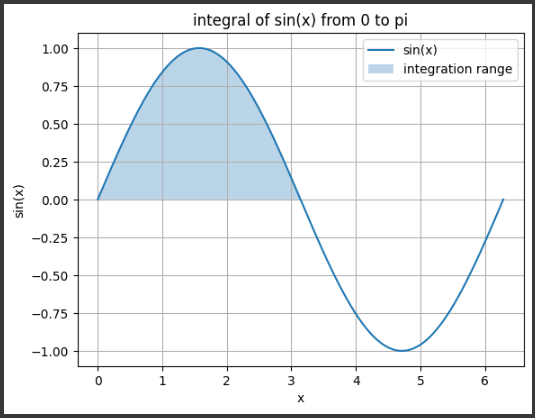
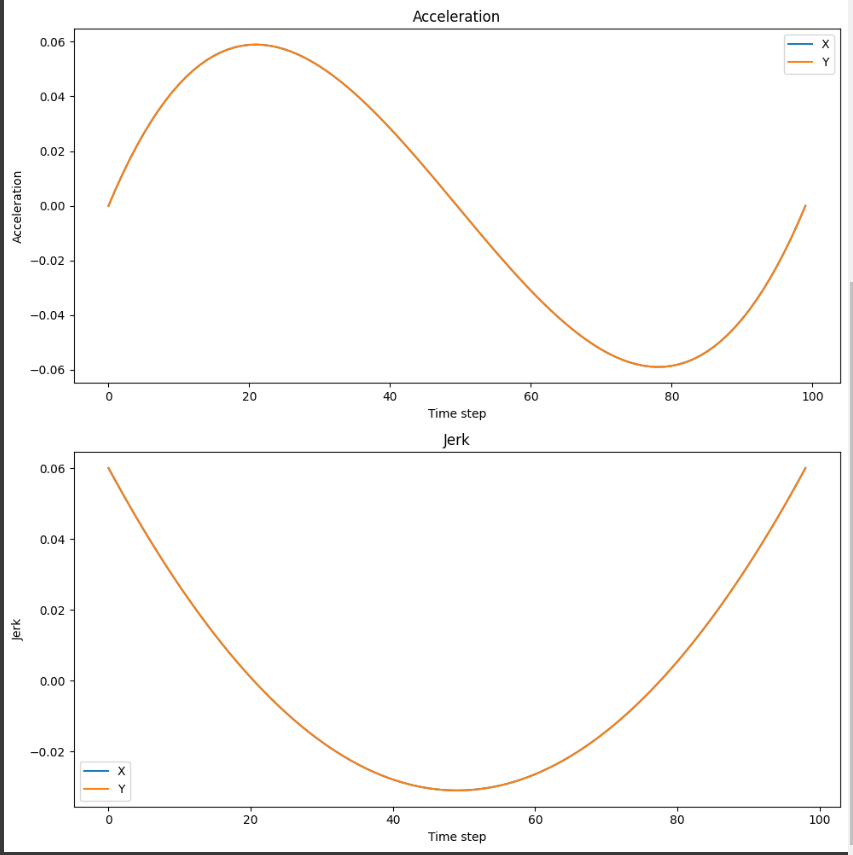
defplot_function_and_derivative(): x_values = np.linspace(-1, 7, 1000) y_values = [func(x) for x in x_values] dy_values = [derivative_func(x) for x in x_values]
plt.figure(figsize=(10, 6)) plt.plot(x_values, y_values, label='y = x^3 - 6x^2 + 9x + 1') plt.plot(x_values, dy_values, label="y' (differential)") plt.xlabel('x') plt.ylabel('y') plt.legend() plt.title('graph of a function and its derivative') plt.grid() plt.show()
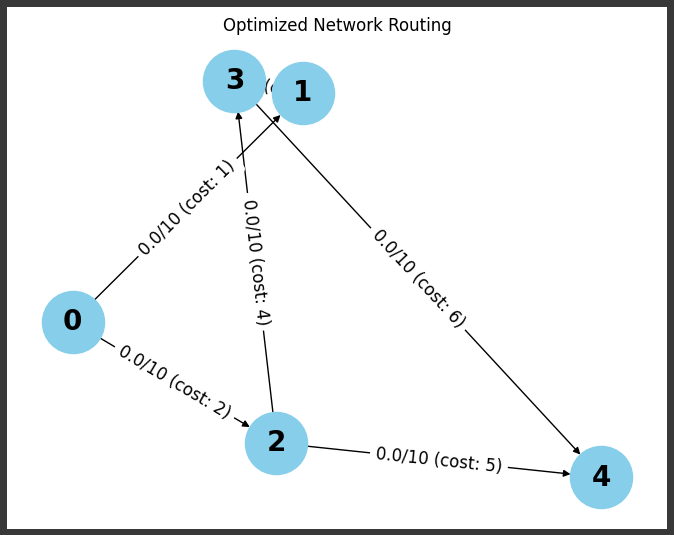
import networkx as nx import matplotlib.pyplot as plt
# グラフを作成 G = nx.DiGraph() G.add_nodes_from(range(nodes)) for i, edge inenumerate(edges): G.add_edge(edge[0], edge[1], capacity=capacities[i], cost=costs[i], flow=flow.value[i])
# グラフを描画 pos = nx.spring_layout(G, seed=42) nx.draw(G, pos, with_labels=True, node_color="skyblue", node_size=2000, font_size=20, font_weight="bold") edge_labels = {(u, v): f"{d['flow']:.1f}/{d['capacity']} (cost: {d['cost']})"for u, v, d in G.edges(data=True)} nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels, font_size=12)