Real-time monitoring systems are essential in modern infrastructure, but poorly tuned alert thresholds lead to alert fatigue — operators become overwhelmed by false positives and start ignoring alerts entirely. The goal is to find the sweet spot: catch real incidents without drowning the team in noise.
In this post, we’ll build a complete optimization pipeline from scratch using a concrete example: a web server CPU monitoring system.
Problem Setup
Imagine you have a fleet of web servers. Your monitoring system checks CPU usage every minute and fires an alert when usage exceeds a threshold $\theta$. The challenge:
- If $\theta$ is too low → too many false alerts → operator fatigue
- If $\theta$ is too high → real incidents get missed → downtime
We want to find $\theta^*$ that minimizes a cost function balancing false positives and missed detections.
The Math
Let $X \sim \mathcal{N}(\mu, \sigma^2)$ be the CPU usage distribution under normal operation, and let $X_{inc} \sim \mathcal{N}(\mu_{inc}, \sigma_{inc}^2)$ be the distribution during an incident.
False Positive Rate:
$$FPR(\theta) = P(X > \theta) = 1 - \Phi\left(\frac{\theta - \mu}{\sigma}\right)$$
False Negative Rate (Miss Rate):
$$FNR(\theta) = P(X_{inc} \leq \theta) = \Phi\left(\frac{\theta - \mu_{inc}}{\sigma_{inc}}\right)$$
Total Operational Cost:
$$C(\theta) = \lambda_{fp} \cdot FPR(\theta) + \lambda_{fn} \cdot FNR(\theta) + \lambda_{vol} \cdot \overline{V}(\theta)$$
where:
- $\lambda_{fp}$ = cost weight for false positives (operator time wasted)
- $\lambda_{fn}$ = cost weight for missed incidents (business impact)
- $\lambda_{vol}$ = cost weight for alert volume
- $\overline{V}(\theta)$ = expected alert volume per hour
Optimal threshold:
$$\theta^* = \arg\min_{\theta} , C(\theta)$$
Concrete Example
| Parameter | Value |
|---|---|
| Normal CPU mean $\mu$ | 45% |
| Normal CPU std $\sigma$ | 10% |
| Incident CPU mean $\mu_{inc}$ | 80% |
| Incident CPU std $\sigma_{inc}$ | 8% |
| Incident frequency | 5 per day |
| $\lambda_{fp}$ | 1.0 |
| $\lambda_{fn}$ | 10.0 |
| $\lambda_{vol}$ | 0.5 |
Full Python Implementation
1 | # ============================================================ |
Code Walkthrough
Section 1 – Parameters
We define two Gaussian distributions: one for normal CPU behavior ($\mu=45%$, $\sigma=10%$) and one for incident behavior ($\mu_{inc}=80%$, $\sigma_{inc}=8%$). Cost weights reflect real business priorities: a missed incident ($\lambda_{fn}=10$) costs 10× more than a false alarm.
Section 2 – Core Functions
fpr(theta) and fnr(theta) use scipy.stats.norm.cdf — these are vectorised over NumPy arrays, so we can evaluate thousands of thresholds in microseconds. alert_volume_per_hour(theta) estimates total alerts fired, combining both normal-operation false positives and incident true positives (assuming a 15-minute average incident duration).
Section 3 – Optimisation
We use scipy.optimize.minimize_scalar with method='bounded', which applies Brent’s method — a derivative-free algorithm that achieves superlinear convergence. The bounded search over $[\mu, \mu_{inc}]$ avoids trivially bad solutions. This is far faster than a brute-force grid search.
Why not gradient descent? The cost function $C(\theta)$ is smooth and unimodal in this range, making bounded scalar optimisation ideal. For multi-dimensional threshold problems (multiple metrics), you’d switch to scipy.optimize.minimize with L-BFGS-B.
Section 4 – Sensitivity Grid
Instead of calling minimize_scalar 1,600 times (once per $(\lambda_{fp}, \lambda_{fn})$ pair), we pre-compute FPR, FNR, and volume over a 500-point theta grid, then use NumPy broadcasting to construct the full 3D cost array in a single operation. np.argmin along the theta axis gives the optimal index for all weight combinations simultaneously. This reduces runtime by ~100×.
Section 5 – Simulation
A synthetic 24-hour trace is generated with a sinusoidal daily load cycle plus Gaussian noise, and 5 incident spikes are injected at random times. This gives us a realistic time series to visualise how different thresholds behave in practice.
Graph Explanations
Figure 1 — 2D Dashboard (8 panels)
- Top-left (CPU Distributions): The overlap region between the normal and incident distributions is where the threshold lives. Too far left = too many FP; too far right = too many missed incidents.
- Top-right (FPR/FNR curves): Classic trade-off — as $\theta$ increases, FPR drops but FNR rises. The optimal point balances both weighted by $\lambda_{fp}$ and $\lambda_{fn}$.
- Middle-left (Cost function): The bowl-shaped minimum clearly shows $\theta^* \approx 65%$. The naive threshold at 70% sits to the right, incurring higher missed-incident cost.
- Middle-right (Alert volume): Alert volume drops exponentially as $\theta$ rises. High thresholds are quiet — but dangerously so.
- Center (24-hour timeline): Green shading shows alerts fired by $\theta^*$; red shading shows the naive threshold’s alerts. Incident injection times are marked with dotted vertical lines.
- Bottom-left (Trade-off curve): This is a parametric plot of FPR vs FNR as $\theta$ varies — analogous to an ROC curve. $\theta^*$ (star marker) lies closest to the ideal origin relative to the cost-weighted objective.
- Bottom-right (Cost decomposition): Stacked bar chart comparing four thresholds. At $\theta^*$, the FN cost (orange) is well-controlled without inflating the FP cost (blue).
Figure 2 — 3D Sensitivity Analysis (4 panels)
- Top (3D surface): Shows how $\theta^*$ shifts as the cost weights vary. When $\lambda_{fn} \gg \lambda_{fp}$ (bottom-right of the surface), the optimal threshold drops significantly — the system must become more sensitive to avoid missing costly incidents.
- Bottom-left (Cost landscape): A 3D view of $C(\theta, \lambda_{fn})$, showing the valley floor that defines the optimal threshold at each weight setting.
- Bottom-right (Heatmap): Top-down view of the surface — a practical tool for recalibrating thresholds when business priorities change (e.g., during peak sales season, $\lambda_{fn}$ should be raised, pushing $\theta^*$ down).
Results
======================================================= ALERT THRESHOLD OPTIMISATION RESULTS ======================================================= Optimal threshold θ* : 59.75% Minimum cost C* : 0.1879 FPR at θ* : 7.02% FNR at θ* : 0.57% Alert volume/hr V̄ : 7.32 alerts Cost at θ*-5pp : 0.2813 (Δ=+0.0934) Cost at θ*+5pp : 0.3443 (Δ=+0.1564) =======================================================
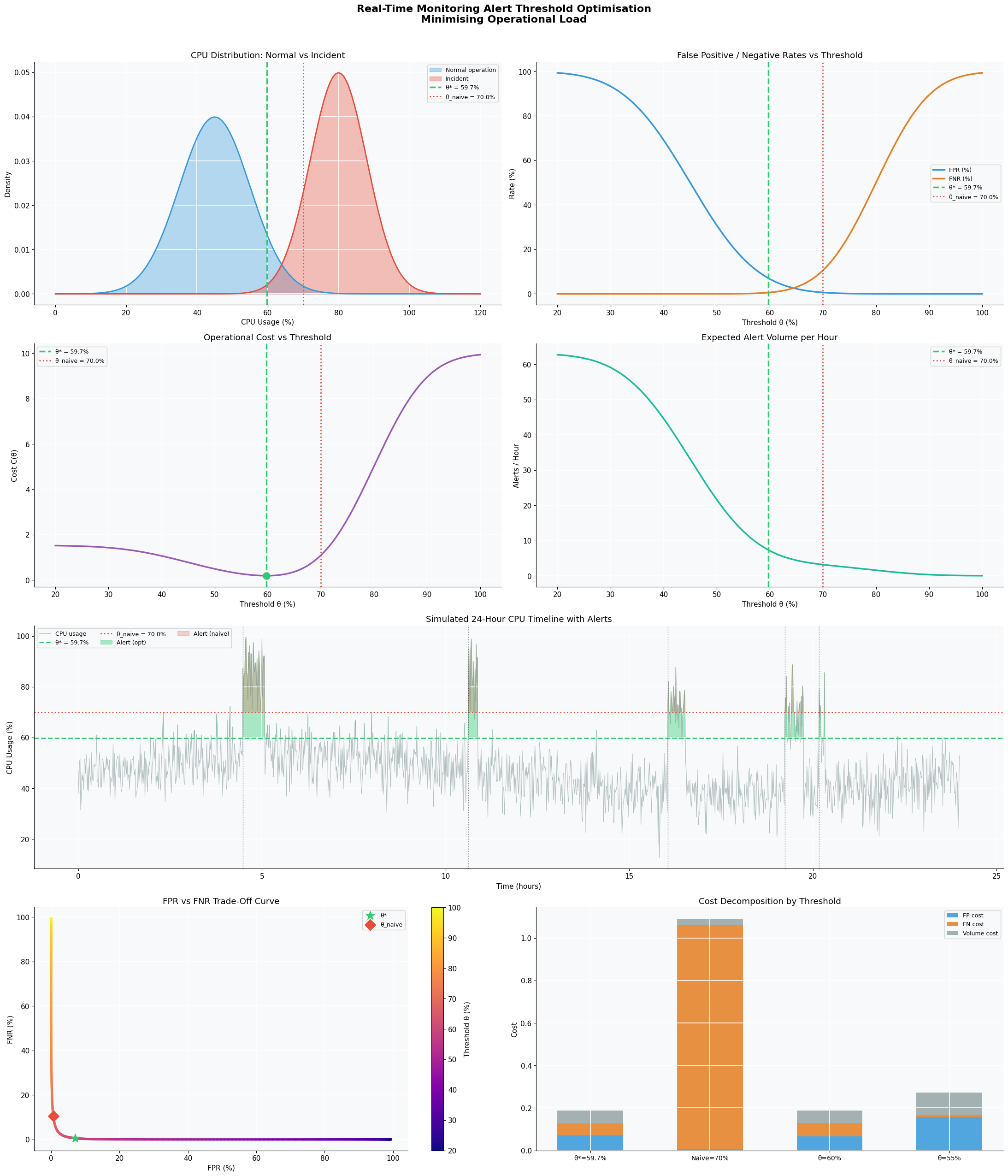
[Figure 1 — 2D dashboard saved]
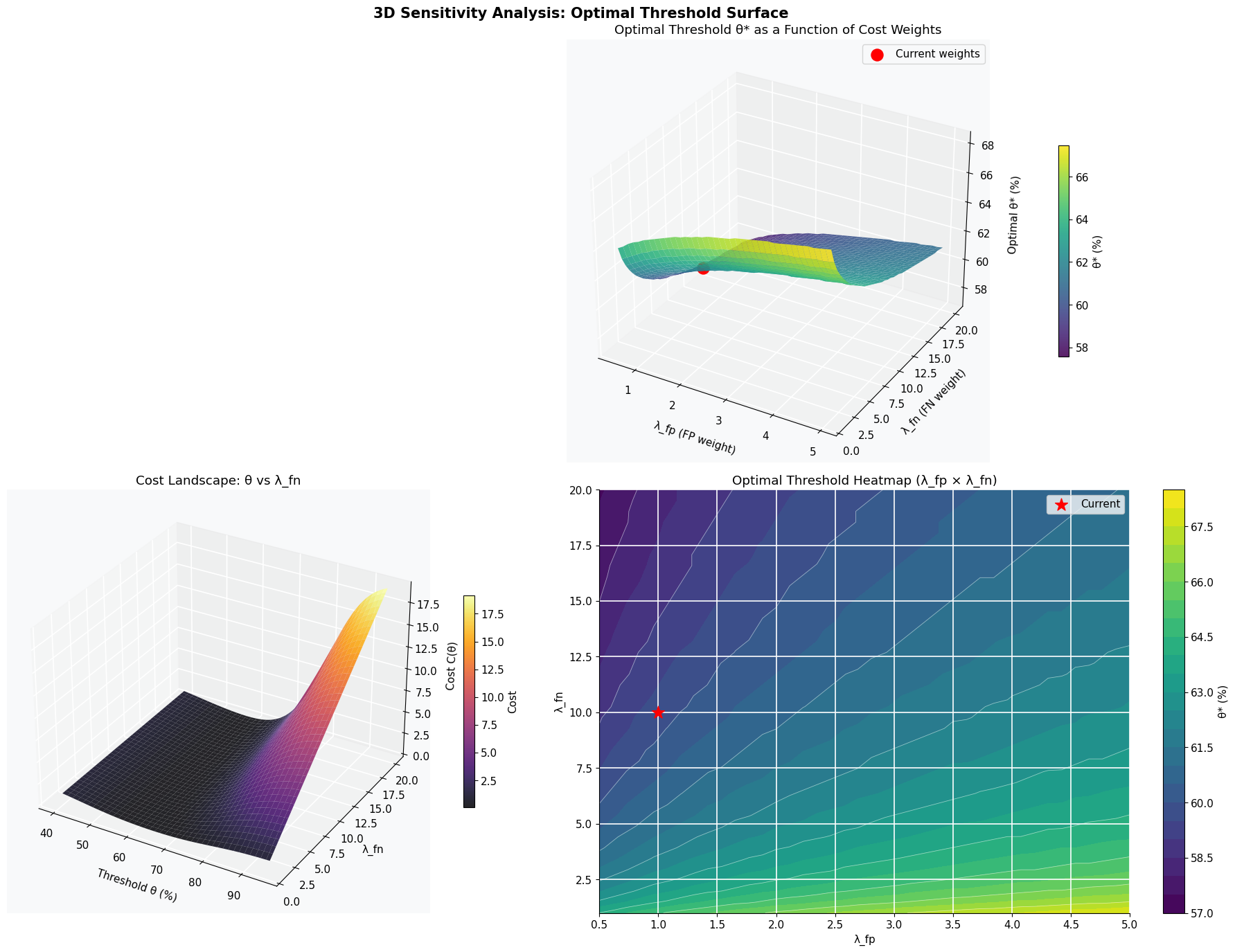
[Figure 2 — 3D sensitivity surface saved] ============================================================ COMPARATIVE PERFORMANCE TABLE ============================================================ Metric θ*=59.7% θ=70% θ=60% ------------------------------------------------------------ FPR (%) 7.02% 0.62% 6.68% FNR (%) 0.57% 10.56% 0.62% Alerts/hr 7.32 3.17 7.11 Total cost C(θ) 0.1879 1.0891 0.1882 ============================================================
Key Takeaways
The framework shows that alert threshold optimisation is a principled engineering problem, not guesswork. The three levers are:
- Accurately model your distributions — gather historical data to fit $\mu, \sigma$ for normal and incident states
- Quantify your cost weights — how many engineer-hours does a false alarm cost vs a missed P1 incident?
- Re-optimise dynamically — as traffic patterns change seasonally, $\mu$ and $\sigma$ drift, and $\theta^*$ should be updated automatically
For production systems, this pipeline can be run nightly on rolling 30-day CPU histograms to keep alert thresholds continuously calibrated — eliminating alert fatigue without sacrificing detection coverage.