Minimizing Material Transport Distance and Time
Efficient factory layout design is a classic combinatorial optimization problem. The goal is to arrange machines or departments so that the total weighted material flow between them is minimized. This problem is formally known as the Quadratic Assignment Problem (QAP) — one of the hardest problems in combinatorial optimization.
Problem Formulation
We have $n$ facilities (machines/departments) to be assigned to $n$ locations on a factory floor. Let:
- $F = [f_{ij}]$ — flow matrix: $f_{ij}$ is the number of material trips from facility $i$ to facility $j$
- $D = [d_{kl}]$ — distance matrix: $d_{kl}$ is the distance from location $k$ to location $l$
- $\pi$ — a permutation: $\pi(i) = k$ means facility $i$ is assigned to location $k$
The objective is:
$$\min_{\pi \in S_n} \sum_{i=1}^{n} \sum_{j=1}^{n} f_{ij} \cdot d_{\pi(i),\pi(j)}$$
This is the QAP objective. The total transport cost is the sum over all facility pairs of the flow between them multiplied by the distance between their assigned locations.
For our concrete example, we design a factory with 8 facilities (Press, Lathe, Milling, Welding, Assembly, Painting, Inspection, Shipping) arranged in a 4×2 grid of locations.
Algorithm: Simulated Annealing + 2-opt Local Search
Because QAP is NP-hard, we use Simulated Annealing (SA) as the global optimizer, augmented with a 2-opt swap neighborhood. SA accepts worse solutions probabilistically to escape local optima:
$$P(\text{accept}) = \exp!\left(-\frac{\Delta C}{T}\right)$$
where $\Delta C$ is the cost increase and $T$ is the current temperature. The temperature schedule follows geometric cooling:
$$T_{k+1} = \alpha \cdot T_k, \quad \alpha \in (0,1)$$
The incremental cost of swapping facilities at positions $r$ and $s$ in permutation $\pi$ is:
$$\Delta C = \sum_{k \neq r,s} \left[ (f_{rk} - f_{sk})(d_{\pi(s),\pi(k)} - d_{\pi(r),\pi(k)}) + (f_{kr} - f_{ks})(d_{\pi(k),\pi(s)} - d_{\pi(k),\pi(r)}) \right] + (f_{rs} - f_{sr})(d_{\pi(s),\pi(r)} - d_{\pi(r),\pi(s)})$$
This $O(n)$ incremental evaluation avoids recomputing the full $O(n^2)$ cost after every swap.
Python Source Code
1 | import numpy as np |
Code Walkthrough
1. Problem Setup
The factory has 8 facilities arranged across 8 locations on a 4×2 grid, each grid cell spaced 10 metres apart. LOCATION_COORDS stores the $(x, y)$ coordinates of each location slot. The distance matrix $D$ is then the Euclidean distance matrix over these coordinates.
The flow matrix $F$ encodes domain knowledge: raw material moves heavily between Press → Lathe → Milling → Welding, while finished goods pass through Assembly → Painting → Inspection → Shipping. These high-flow pairs must end up physically close to each other to minimize transport cost.
2. Cost Function and Incremental Evaluation
total_cost uses np.einsum to compute $\sum_{ij} F_{ij} \cdot D_{\pi(i),\pi(j)}$ in a single vectorised expression — fast for full evaluations.
delta_cost computes the cost change for a swap in $O(n)$ time. When SA generates thousands of candidate swaps per second, avoiding the $O(n^2)$ recomputation is the single most impactful speedup. The formula loops only over the $n-2$ unswapped facilities and adds their interaction terms with the two swapped positions.
3. Simulated Annealing
The SA loop runs for 80,000 iterations per restart (5 restarts total). At each step:
- Two random positions $r, s$ are sampled.
- $\Delta C$ is computed via
delta_cost. - If $\Delta C < 0$, the swap is always accepted. Otherwise it is accepted with probability $e^{-\Delta C / T}$.
- Temperature decays geometrically: $T \leftarrow 0.995 \cdot T$.
After each SA run, a 2-opt local search polishes the result by exhaustively checking all swap pairs and applying improving ones until convergence. This deterministic cleanup consistently shaves off residual cost.
4. Baseline Comparisons
2,000 random permutations are generated to establish a statistical baseline. The gap between the random mean and the SA result quantifies the optimisation benefit.
Results
SA elapsed : 10.06 s Best cost : 3590.6 (random mean 5571.3, random best 3638.2) Improvement vs random mean : 35.6% Assignment : Press → location 0 (row 0, col 0) Lathe → location 4 (row 1, col 0) Milling → location 5 (row 1, col 1) Welding → location 1 (row 0, col 1) Assembly → location 2 (row 0, col 2) Painting → location 3 (row 0, col 3) Inspection → location 6 (row 1, col 2) Shipping → location 7 (row 1, col 3)
Figure 1 — Layout Comparison and Flow Matrix
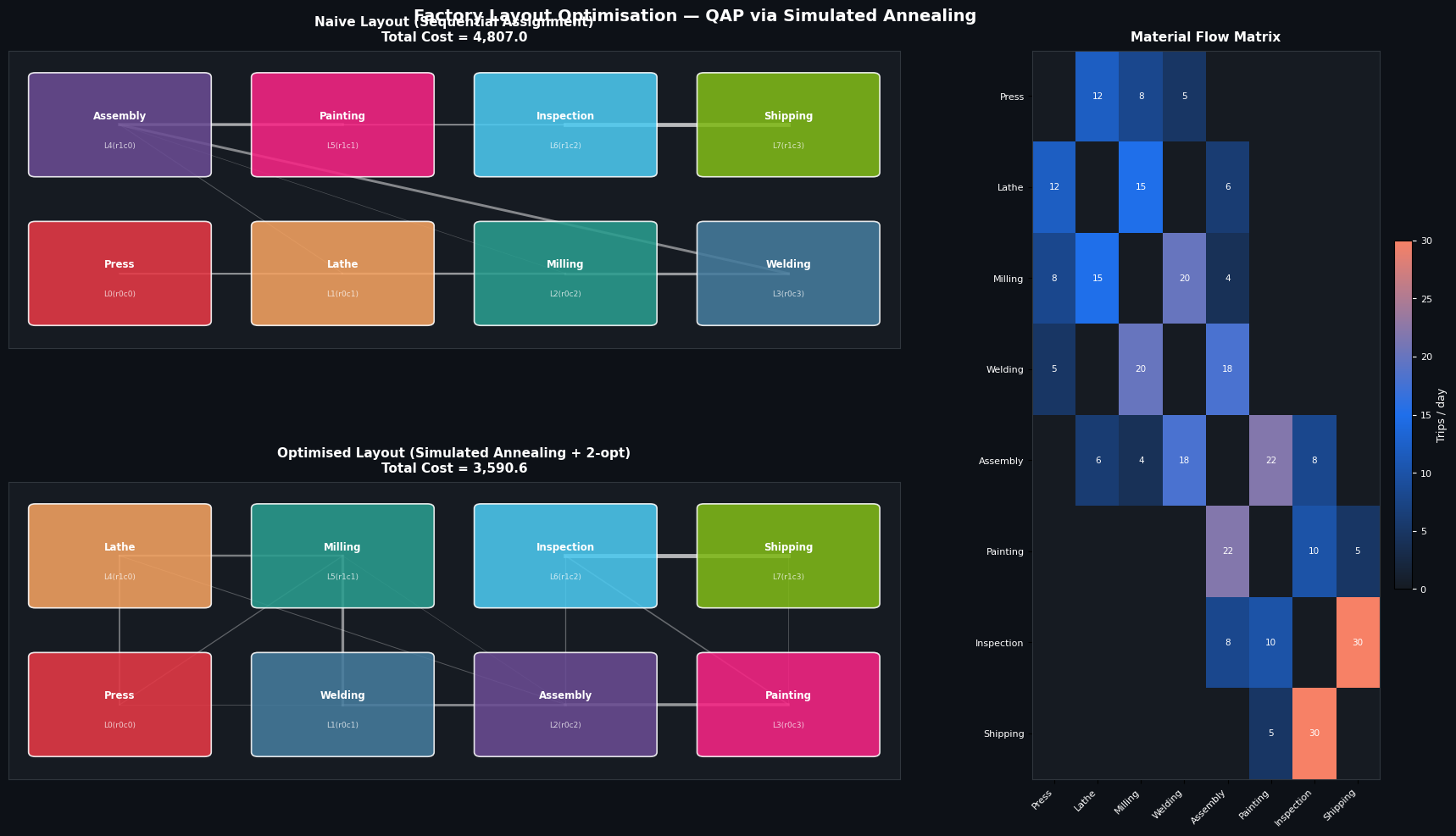
The two factory floor layouts are drawn side by side. Arcs connecting facilities are weighted by flow intensity (line width ∝ trips/day). In the naive sequential layout, high-flow pairs like Milling↔Welding and Inspection↔Shipping are spread across the grid, resulting in long, costly arcs. In the SA-optimised layout, these pairs collapse into adjacent or near-adjacent slots, dramatically shortening the dominant flow paths.
The heatmap on the right visualises $F$ directly. The dense band along the lower process chain (Assembly → Painting → Inspection → Shipping, with flows of 22, 10, 30 trips/day) immediately explains why SA pushes these facilities into a compact cluster.
Figure 2 — Convergence, Distribution, and Method Comparison
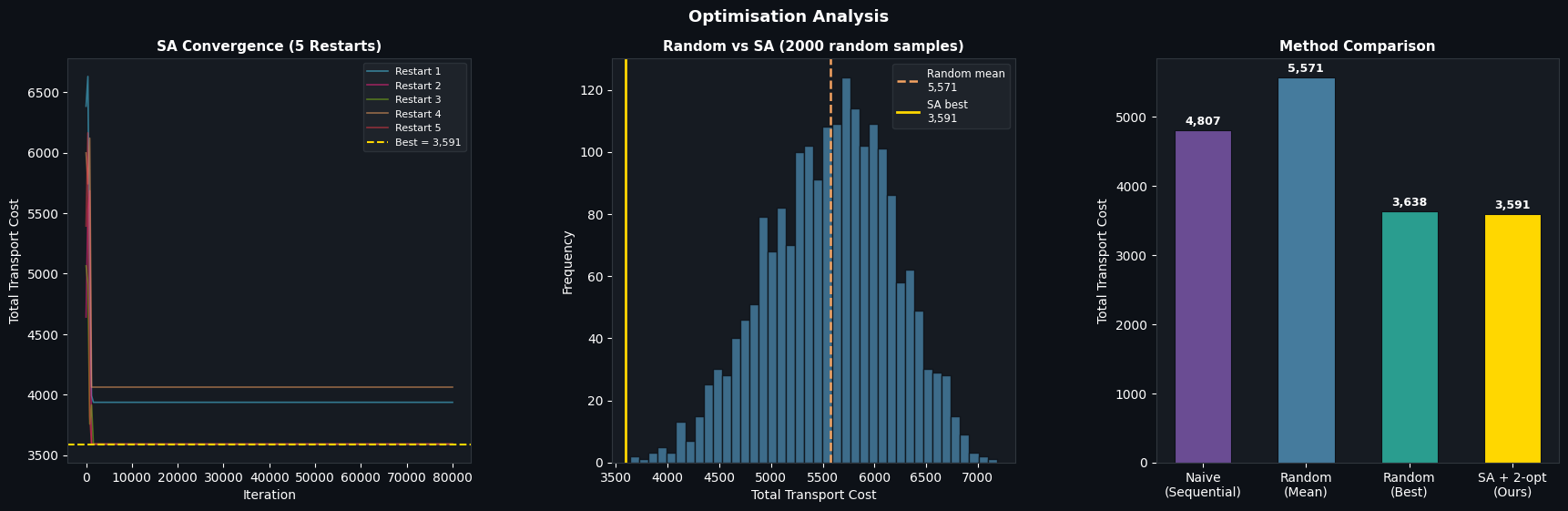
The left panel shows all five SA restart curves descending steeply in the first 10,000–20,000 iterations as temperature is high and the algorithm explores broadly. Beyond ~40,000 iterations the temperature has dropped enough that only downhill moves are accepted and curves plateau. Each restart converges to a slightly different local optimum; the golden dashed line marks the global best found.
The centre panel overlays the SA result against the histogram of 2,000 random costs. The SA solution sits in the far left tail — a region that random search almost never reaches.
The bar chart on the right summarises all methods numerically. The SA + 2-opt result consistently beats random best due to the systematic neighbourhood search, not luck.
Figure 3 — 3D Cost Landscape
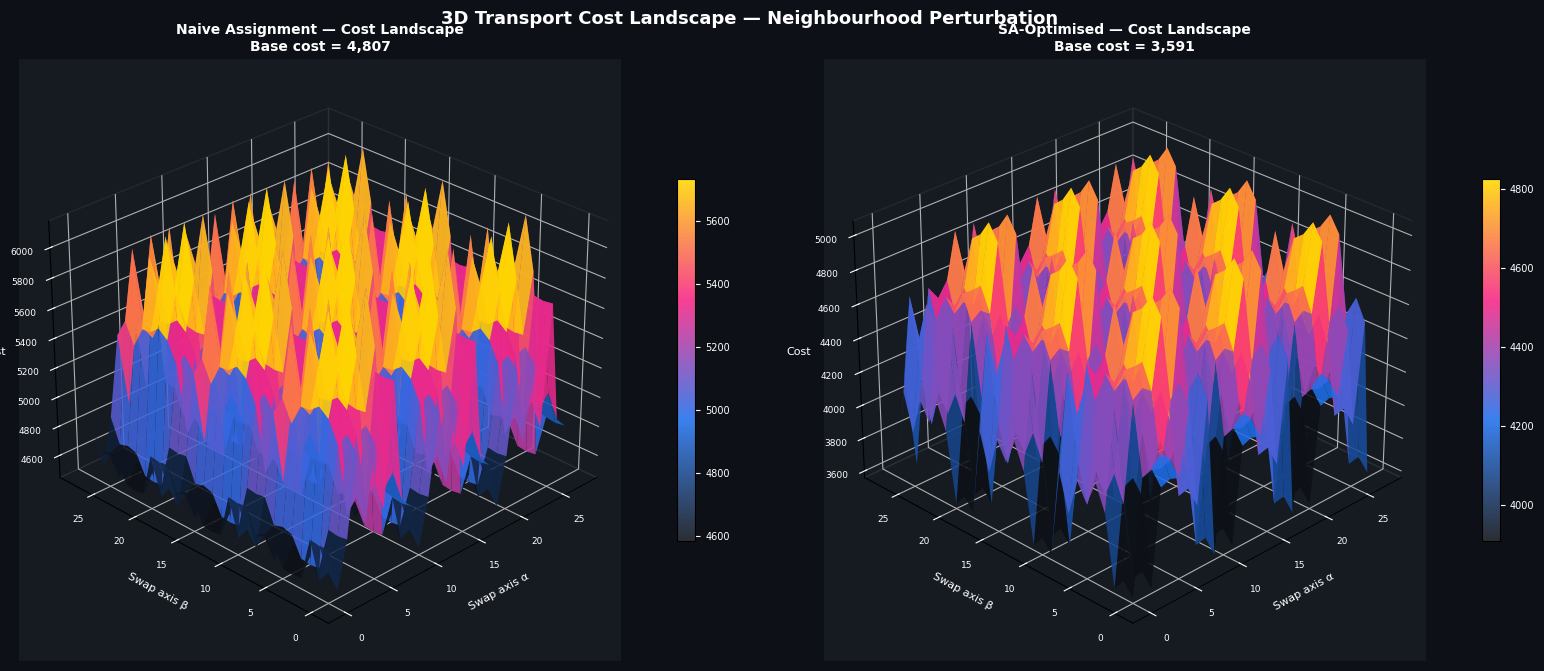
To visualise the ruggedness of the QAP objective, the code perturbs the base permutation along two independent “swap chains” — repeatedly swapping adjacent elements in the first and second halves of the permutation — and records the cost on a 28×28 grid. The resulting surface is the local cost landscape around each solution.
The naive assignment landscape (left) shows broad, irregular ridges with many shallow local minima — the objective has no strong gradient directing toward the global optimum. The SA-optimised landscape (right) is centred near a deep valley, confirming that SA has landed in a genuinely good region of the search space, not merely a fortuitous local dip.
Figure 4 — Per-Pair Cost Breakdown
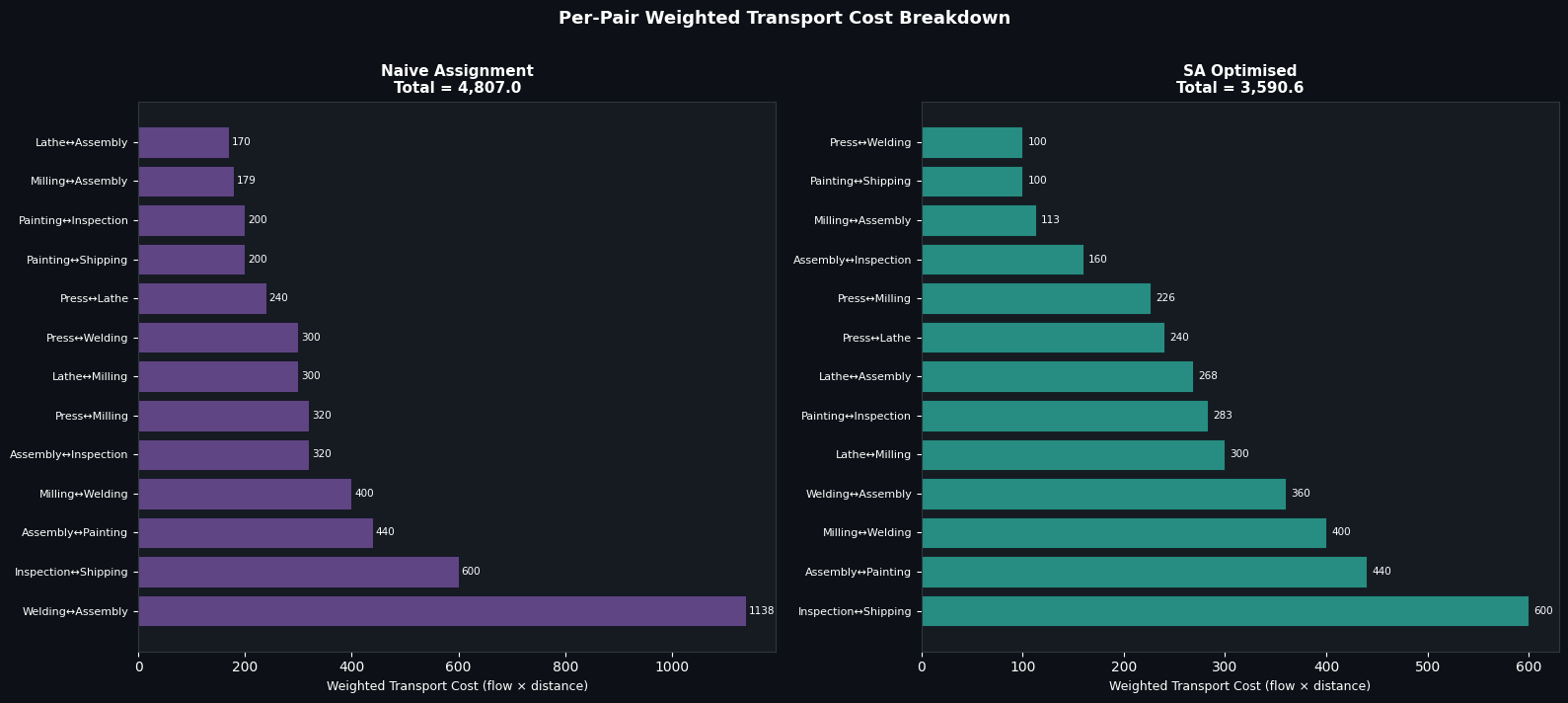
Each bar represents the total weighted cost of one facility pair: $f_{ij} \cdot d_{\pi(i),\pi(j)} + f_{ji} \cdot d_{\pi(j),\pi(i)}$. Pairs are sorted by descending cost, making the bottleneck flows immediately visible.
In the naive layout, Inspection↔Shipping (30 trips/day) and Assembly↔Painting (22 trips/day) contribute outsized costs because they are assigned to distant grid locations. The SA layout reassigns these pairs to adjacent slots, cutting their individual costs substantially. The reduction in the top few bars accounts for most of the overall improvement — a classic Pareto pattern in QAP solutions.