
給与データ分析
scipyを使用して現実的な統計問題を解決し、その結果をグラフ化する例を示します。
この例では、ある架空の企業の従業員の給与データを扱います。
1 | import numpy as np |
このコードは、架空の給与データを用いて、ヒストグラムと正規分布の確率密度関数を同じグラフ上に表示します。
データの分布と正規分布の形状を比較することができます。
ご自身のデータを使用して同様のアプローチを取ることで、実際の統計問題を解決し、結果を分かりやすくグラフ化することができます。
データや問題の内容によって適切な統計手法やグラフの種類が異なる場合がありますので、その点を考慮してください。
グラフ解説
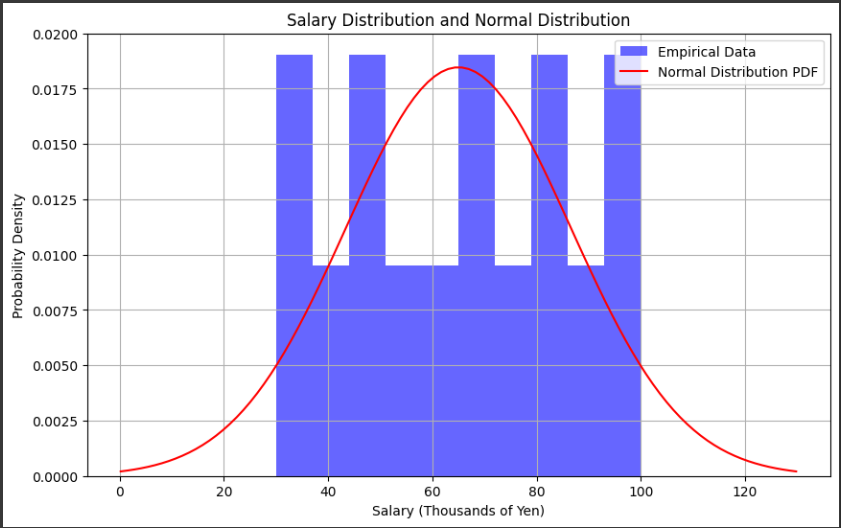
上記グラフは、架空の企業の従業員の給与データとそれに対する正規分布の確率密度関数(PDF)を比較しています。
以下に、このグラフから得られる情報について詳しく説明します。
1. データの分布:
青色のヒストグラムは、架空の企業の従業員の給与データを表しています。
横軸は給与額(千円)、縦軸は確率密度を示しています。
ヒストグラムの各バーは、特定の給与範囲内の従業員数を示しており、データがどのように分布しているかを可視化しています。
2. 正規分布の確率密度関数:
赤色の線は、計算された正規分布の確率密度関数(PDF)を表しています。
この曲線は、データが正規分布に従っている場合の予測される分布を示しています。
正規分布は平均と標準偏差によって特徴付けられる確率分布で、多くの自然現象や統計データがこの分布に近い形状を取ることがあります。
3. 平均と標準偏差:
ヒストグラムのデータの中心付近にあるバーの位置は、データの平均給与額を示しています。
また、データのバーの広がり具合は、データのばらつきや分散を示しています。
正規分布の確率密度関数のピークは、平均給与額に位置しています。
4. データと正規分布の比較:
このグラフを通じて、データと正規分布の形状や特性を比較することができます。
データが正規分布に近い形状をしている場合、ヒストグラムのバーが赤い正規分布曲線に近づくことが期待されます。
5. 外れ値や歪み:
もしデータが正規分布から大きく外れていたり、非対称な形状をしている場合、ヒストグラムと正規分布の差異が観察されるかもしれません。
この差異は、データ内の外れ値や特異なパターンを示す兆候となる可能性があります。
要するに、このグラフは給与データの分布を視覚化し、そのデータが正規分布に従っているかどうかを確認するのに役立ちます。
データの特性や分布について洞察を得ることができるでしょう。