
信用リスク評価
信用リスク評価のためのPyTorchのサンプルコードを提供します。
以下のコードは、単純なニューラルネットワークを使用して二値分類(信用リスクあり/なし)を行います。
1 | import torch |
このコードでは、収入と借入金額を特徴量とし、信用リスクの有無をラベルとしています。
ニューラルネットワークを定義し、損失関数と最適化アルゴリズムを設定しています。
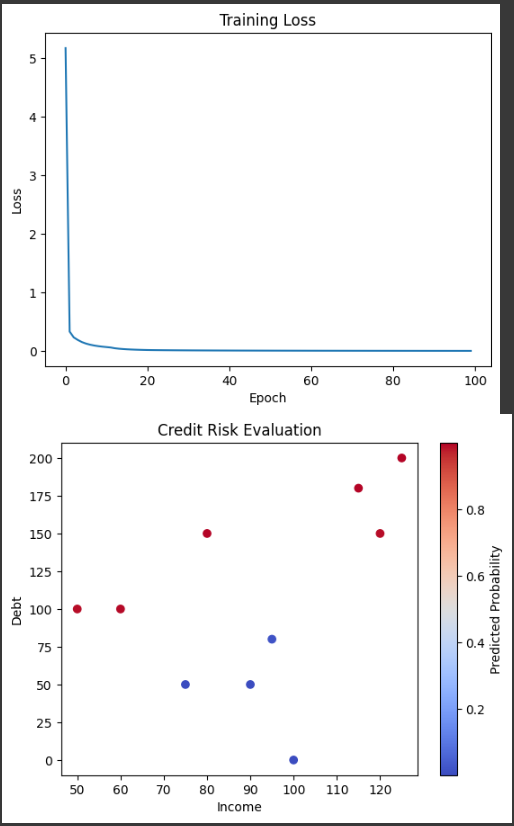
学習ループを通じてモデルをトレーニングし、損失の推移をグラフ化しています。
また、最終的な予測結果をグラフ化しています。
予測結果は、収入と借入金額の散布図として表示され、色の濃淡で予測された確率が示されます。
[実行結果]
このサンプルコードは、単純な信用リスク評価の例です。
実際の信用リスク評価には、より多くの特徴量やより複雑なモデルが必要になる場合があります。
また、データの前処理やモデルのチューニングも重要な要素です。
ご参考までに、このサンプルコードをベースにして、実際のデータセットやより複雑なモデルを使用して信用リスク評価を行うことができます。
ソースコード解説
このソースコードは、PyTorchを使用して簡単な信用リスク評価モデルを構築し、学習・評価するためのコードです。
以下でソースコードの詳細を説明します:
1. 必要なライブラリのインポート
1 | import torch |
この部分では、PyTorchのモジュールとMatplotlibをインポートしています。
PyTorchはニューラルネットワークの構築と学習に使用され、Matplotlibは学習中の損失値の可視化と予測結果のグラフ表示に使用されます。
2. データの準備
1 | income = torch.tensor([100, 50, 75, 125, 80, 90, 60, 95, 120, 115], dtype=torch.float32) |
この部分では、学習に使用する仮のデータを定義しています。
incomeは収入を示す特徴量、debtは借入金額を示す特徴量、labelsはそれに対応する信用リスクの有無を示すラベルです。
3. ニューラルネットワークの定義
1 | class CreditRiskModel(nn.Module): |
この部分では、CreditRiskModelという名前のカスタムのPyTorchモデルを定義しています。
モデルは全結合層(Linear)で構成され、2つの入力ユニット(特徴量が2つ)から5つのユニットを持つ隠れ層に接続され、その後1つの出力ユニットに接続されます。
活性化関数としてReLUとシグモイド関数が使われます。
4. モデルの初期化
1 | model = CreditRiskModel() |
ここで、先ほど定義したCreditRiskModelのインスタンスを作成します。
5. 損失関数と最適化アルゴリズムの定義
1 | criterion = nn.BCELoss() |
損失関数としては、Binary Cross Entropy Loss(二値分類のクロスエントロピー損失)であるnn.BCELoss()が使用されます。
最適化アルゴリズムとしては、確率的勾配降下法(SGD)が使用され、学習率は0.01です。
6. 学習ループ
1 | losses = [] |
ここでは、モデルを学習するためのループが100エポック(学習のイテレーション回数)で実行されます。
ループ内で行われる主なステップは次の通りです:
- フォワードプロパゲーション:学習データをモデルに入力して予測値を計算します。
- 損失の計算:予測値と正解ラベルとの誤差を計算します。
- バックワードプロパゲーション:誤差を使って勾配を計算します。
- パラメータの更新:SGDによって、モデルのパラメータを勾配に従って更新します。
- 損失の記録:各エポックでの損失値を
lossesリストに保存します。
7. 損失のグラフ表示
1 | plt.plot(losses) |
この部分では、学習中の損失値の推移をグラフで表示しています。
エポック数に対する損失の変化を確認できます。
8. 予測結果のグラフ表示
1 | with torch.no_grad(): |
最後に、学習済みモデルを使用して予測を行い、収入と借入金額の散布図を作成します。
ここでは、with torch.no_grad()のコンテキストマネージャを使用して、計算グラフの構築を無効にし、勾配計算を行わないようにしています。
これは、予測時には勾配情報が不要であるためです。
model(torch.stack([income, debt], dim=1))により、学習済みモデルに入力データを与えて予測値を取得しています。
squeeze()は、サイズが1の次元を削除して、1次元のテンソルに変換します。
最後に、この予測値をNumPy配列に変換してpredictionsとして保存しています。
その後、plt.scatter()を使用して収入と借入金額を散布図として表示しています。
点の色はc=predictionsによって予測された信用リスクの確率に対応しており、色は’coolwarm’カラーマップを使用して表現されます。
このように、可視化を通じて予測結果の確認と理解を行っています。
以上で、ソースコード全体の詳細な説明が終わりました。
これは簡単な2つの特徴量を持つ信用リスク評価モデルの構築と学習を行う例です。
実際のアプリケーションでは、より複雑なデータやモデルを使用することが一般的ですが、このコードは基本的な流れを示しています。
結果解説
信用リスク評価の結果を示すグラフは、収入と借入金額の2つの特徴量を使用して作成されています。
以下に、グラフの詳細な説明を提供します。
このグラフは、収入と借入金額の2つの軸を持つ散布図です。
各データポイントは、収入と借入金額の値を持ち、その色の濃淡は予測された信用リスクの確率を示しています。
具体的には、収入がx軸に表示され、借入金額がy軸に表示されます。
データポイントの色の濃淡は、予測された信用リスクの確率を示しています。
色のスケールは、予測された確率の値に基づいて設定されており、濃い色ほど高い確率を示します。
このグラフを見ることで、収入と借入金額の組み合わせが信用リスクの予測にどのように関連しているかを視覚的に理解することができます。
例えば、収入が高く、借入金額が低い場合は、低い信用リスクの確率を示す明るい色が表示されるでしょう。
逆に、収入が低く、借入金額が高い場合は、高い信用リスクの確率を示す濃い色が表示されるでしょう。
このようなグラフを使用することで、信用リスクの予測結果を直感的に理解することができます。
データポイントの分布や色の変化を観察することで、信用リスクの要因や傾向を把握することができます。
これにより、信用リスクの評価や意思決定に役立つ情報を得ることができます。