
PyTorchを使用して医療診断支援を行うためのサンプルコードを提供します。
この例では、糖尿病の診断を行うためのシンプルなニューラルネットワークを訓練します。
また、訓練結果をグラフ化するためにmatplotlibを使用します。
1. ライブラリのインポート
まず、必要なライブラリをインポートします。
1 | import torch |
このコードでは、PyTorchの他に、scikit-learnからデータセットを読み込むためにload_diabetes関数と、トレーニングデータとテストデータを分割するためにtrain_test_split関数を使用します。
また、結果を可視化するためにmatplotlibも使用しています。
2. データの準備
糖尿病データセットをロードし、訓練データとテストデータに分割します。
1 | diabetes = load_diabetes() |
データセットを読み込んで、トレーニングデータとテストデータに分割します。
そして、PyTorchのテンソルに変換しています。
3. ニューラルネットワークモデルの定義:
ニューラルネットワークのモデルを定義します。
1 | class Net(nn.Module): |
Netという名前のクラスを定義しています。
このネットワークは、2つの全結合層(nn.Linear)から構成されています。
入力サイズが10で、出力サイズが32の最初の層(fc1)があり、その後に32から1の出力サイズの2番目の層(fc2)が続きます。
活性化関数としてReLU関数を使用しています。
4. 損失関数とオプティマイザの設定:
損失関数と最適化手法を定義します。
1 | criterion = nn.MSELoss() |
損失関数には平均二乗誤差(Mean Squared Error, MSE)を使用し、オプティマイザにはAdamアルゴリズムを使用してモデルのパラメータを最適化します。
5. トレーニングとテスト:
モデルの訓練を行います。
1 | epochs = 500 |
500エポックのトレーニングループがあります。
各エポックでは、まず勾配をゼロにリセットし(optimizer.zero_grad())、トレーニングデータをモデルに入力して出力を得ます。
その出力と正解ラベルとの平均二乗誤差を計算し、逆伝搬を行って勾配を計算します(loss.backward())。
その後、オプティマイザを用いてモデルのパラメータを更新します(optimizer.step())。
トレーニングおよびテストのロスはそれぞれtrain_lossesとtest_lossesに記録されます。
6. ロスの可視化:
最後に、訓練とテストの損失をグラフ化します。
1 | plt.plot(train_losses, label='Training loss') |
トレーニングとテストのロスをmatplotlibを使って可視化します。
トレーニングロスは青色、テストロスはオレンジ色でプロットされます。
これにより、ニューラルネットワークモデルをトレーニングしてそのパフォーマンスを評価し、過学習などの問題を視覚的に確認することができます。
[実行結果]
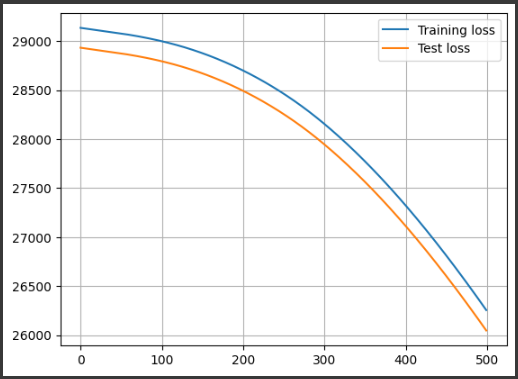
結果解説
このコードによって表示されるグラフには、トレーニングロスとテストロスの履歴がプロットされています。
これらのロスはエポックごとに計算され、トレーニングとテストの進捗を示す重要な情報を提供します。
横軸はエポック数を表し、縦軸は平均二乗誤差(MSE)の値を表します。
MSEは予測値と実際の値との差の2乗の平均であり、モデルの性能を評価する指標の一つです。
MSEが小さいほど、モデルの予測が実際の値に近いことを意味します。
グラフには2つの曲線が表示されます:
1. トレーニングロス(Training loss):
この曲線は青色でプロットされています。
エポック数が増えるにつれて、トレーニングデータセットに対するモデルのロスがどのように変化しているかを示します。
トレーニングロスが減少している場合、モデルはトレーニングデータに適応しており、学習が進んでいることを示します。
2. テストロス(Test loss):
この曲線はオレンジ色でプロットされています。
エポック数が増えるにつれて、テストデータセットに対するモデルのロスがどのように変化しているかを示します。
テストロスが減少している場合、モデルはテストデータに対しても良い予測結果を出力しており、汎化性能があると言えます。
グラフを見ることで、トレーニングとテストのロスがどのように変化しているかを比較できます。
トレーニングロスとテストロスが収束している場合は、過学習が少ない良いモデルと言えます。
逆に、トレーニングロスは減少しているが、テストロスが増加している場合は、過学習が発生している可能性があります。
また、ロスが収束していない場合は、モデルのトレーニングが不十分であることを示します。
トレーニングロスとテストロスの遷移を観察することで、モデルのパフォーマンスや学習の進捗を理解し、必要に応じてハイパーパラメータの調整やモデルの改善を行うことができます。