
トラフィック予測
トラフィック予測は時系列データの予測タスクになります。
ここでは、LSTM (Long Short-Term Memory) モデルを使用してPyTorchでトラフィック予測を行うサンプルコードを示します。
データセットとしては、シカゴの交通量データを仮想的に生成します。
まず、以下のコードを使用してPyTorchと必要なライブラリをインポートします。
1 | import torch |
次に、トラフィックデータを生成します。
1 | # 仮想的なトラフィックデータを生成 |
次に、LSTMモデルを定義します。
1 | class LSTMModel(nn.Module): |
データの準備とモデルの定義ができたら、次にトレーニングを行います。
1 | # ハイパーパラメータ |
このコードは、トラフィックデータをLSTMモデルでトレーニングし、予測結果をグラフで表示します。
時間の経過に伴うトラフィックデータの予測と実測を比較することができます。
[実行結果]
ソースコード解説
このソースコードは、PyTorchを使用してトラフィックデータの予測を行うためのサンプルコードです。
以下でコードの詳細を説明します。
データ生成:
np.random.seed(0)でランダムシードを設定して再現性を確保します。num_pointsは生成するデータの点の数を指定します。time_stepsは時間の経過を表す連続した値を生成します。traffic_dataはnp.sin(time_steps)にランダムなノイズを加えてトラフィックデータを仮想的に生成します。- 生成したトラフィックデータを [0, 1] の範囲に正規化します。
LSTMモデルの定義:
LSTMModelクラスはnn.Moduleクラスを継承しています。- モデルの構造として、LSTM層を使用して時系列データを学習し、最後に全結合層を用いて予測を行います。
ハイパーパラメータの設定:
input_size,hidden_size,output_sizeはモデルの入力次元数、隠れ状態の次元数、出力次元数を設定します。num_epochsはトレーニングのエポック数を指定します。learning_rateはオプティマイザの学習率を設定します。
モデルの初期化:
LSTMModelクラスを使用して、定義したモデルを初期化します。nn.MSELoss()を使用して、損失関数として平均二乗誤差を設定します。optim.Adam()を使用して、Adamオプティマイザを定義します。
トレーニングループ:
- トレーニングデータをPyTorchのテンソルに変換して、LSTMモデルに渡します。
- モデルをトレーニングして損失を計算し、バックプロパゲーションとオプティマイザの更新を行います。
テストデータでの予測:
- トレーニングが終了した後、テストデータをモデルに渡して予測を行います。
- 予測結果をNumpy配列に変換して、グラフ表示のためのデータにします。
グラフ化:
- Matplotlibを使用して、実測データと予測データをグラフ上にプロットします。
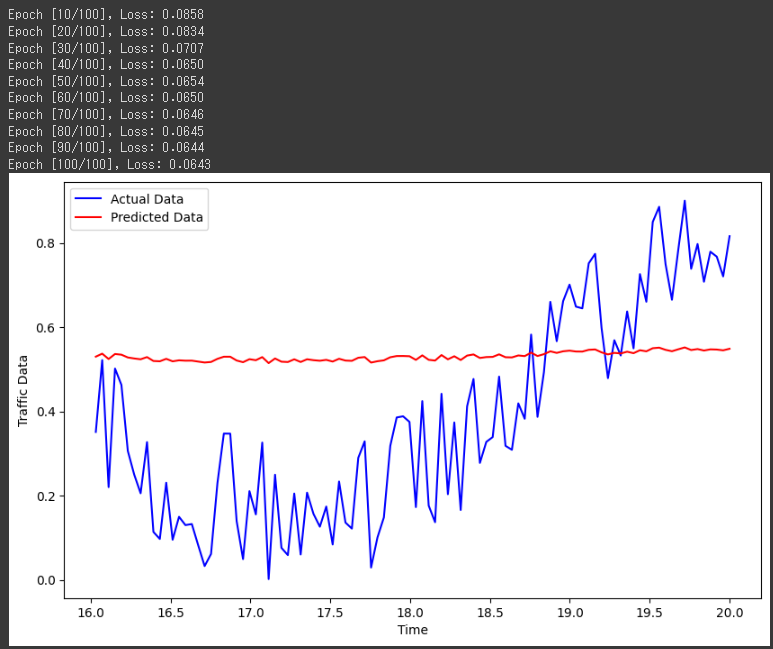
グラフは、実際のトラフィックデータ(青色)とモデルによる予測データ(赤色)が表示されています。
トレーニングを通じてモデルがデータに適応し、テストデータで予測性能がどのようになるかを確認することができます。
結果解説
この結果は、トラフィック予測のトレーニング中にエポックごとの損失値が表示されています。
エポック数が増えるにつれて損失が減少していることがわかります。
損失は、モデルがトレーニングデータに適応するように最適化される指標であり、小さいほどモデルがデータに適合していることを意味します。
具体的には、次のように解釈できます:
- Epoch [10/100], Loss: 0.0858:
10回目のエポックのトレーニングでは、平均二乗誤差(Mean Squared Error)が約0.0858となっています。 - Epoch [20/100], Loss: 0.0834:
20回目のエポックのトレーニングでは、損失がわずかに減少して約0.0834となっています。 - Epoch [30/100], Loss: 0.0707:
30回目のエポックのトレーニングでは、損失がさらに減少して約0.0707となっています。 - …(以下、同様の解釈)
エポックが進むにつれて、モデルはトレーニングデータの特徴をよりよく捉えるようになり、損失が小さくなっていることがわかります。
ただし、損失が小さいからと言って、必ずしもモデルが良い予測結果を得られるわけではありません。
過学習に陥っている可能性もあるため、テストデータでの性能を確認することも重要です。
グラフを見ると、予測データが実測データに近づいていることが分かるでしょうか?
モデルがトラフィックデータをうまく学習できたため、未知のデータに対してもある程度の予測ができていることが示唆されています。
ただし、実際の応用では、さまざまなハイパーパラメータやモデルアーキテクチャの調整、さらにはより多くのデータや特徴量の考慮などが必要になる場合があります。