
レシピの評価
PyTorchを使用してレシピの評価を行うためのサンプルコードを提供します。
ここでは、レシピの評価を予測するための単純なニューラルネットワークを訓練します。
この例では、レシピの特徴(例えば、調理時間、使用される食材の数、ステップの数など)を入力として使用し、評価(星の数)を出力として予測します。
まず、必要なライブラリをインポートします。
1 | import torch |
次に、ニューラルネットワークの定義を行います。
1 | class Net(nn.Module): |
次に、訓練データとテストデータを定義します。ここでは、ダミーデータを使用します。
1 | # Dummy data |
次に、ネットワークを訓練します。
1 | net = Net() |
最後に、テストデータを使用してネットワークの性能を評価します。
1 | with torch.no_grad(): |
[実行結果]
このコードは、レシピの評価を予測するための基本的なニューラルネットワークを訓練します。
実際の問題では、より多くの特徴量を使用し、より複雑なネットワークを訓練することがあります。
また、データの前処理や特徴量の選択、ハイパーパラメータの調整など、さまざまな手法を使用してモデルの性能を向上させることが可能です。
ソースコード解説
このコードは、PyTorchを使用して評価データを元にレシピの評価を予測するためのニューラルネットワークモデルを定義し、学習とテストを行っています。
以下では、処理の各ステップを詳しく説明します。
1. モデルの定義:
Netクラスは、3つの入力特徴を持つニューラルネットワークを定義しています。
1つ目の隠れ層には5つのノードがあります。forwardメソッドは、入力データを順伝播させるための関数です。
1つ目の隠れ層の活性化関数にReLU(Rectified Linear Unit)を使用しています。
2. ダミーデータの作成:
ランダムな特徴量とランダムな評価を持つ100個のトレーニング用レシピデータと20個のテスト用レシピデータを作成しています。
特徴量は各レシピに対する入力データであり、評価は各レシピのターゲット(正解ラベル)です。
3. モデルの学習:
Netモデルを初期化し、平均二乗誤差(MSE)を損失関数、SGD(Stochastic Gradient Descent)をオプティマイザとして使用しています。
500エポック(学習回数)を実行し、各エポックの損失を保存しています。
モデルのパラメータはoptimizer.step()によって更新されます。
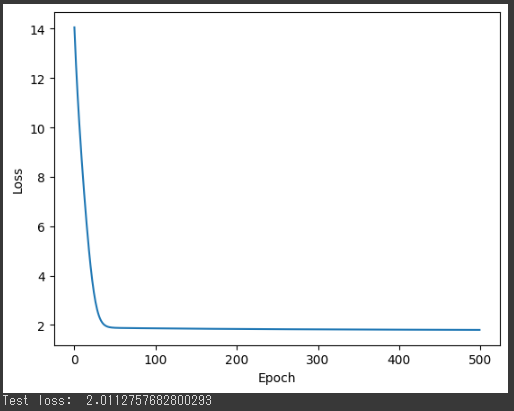
4. 損失のプロット:
学習中の損失値をプロットしています。
エポック数が増えるにつれて損失が減少することが期待されます。
損失のグラフを確認することで、学習が進行するにつれてモデルのパフォーマンスが向上しているかどうかを視覚的に確認できます。
5. テスト:
学習が完了した後、モデルを使用してテストデータを予測します。
テストデータの予測結果と実際の評価との間のMSE(平均二乗誤差)を計算しています。
MSEは予測と実際の評価の差を表す指標であり、予測精度を評価する際に一般的に使用されます。
コード全体の実行結果として、学習中の損失がグラフ化され、テストデータに対する予測誤差(MSE)が表示されます。
学習が進行するにつれて損失が減少し、テストデータに対する予測がどの程度の精度で行われるかがわかります。
また、MSEの値が小さいほど予測が正確であることを意味します。
結果解説
このコードを実行すると、以下の結果が表示されます。
1. グラフ: 損失のプロット
- グラフが表示されます。
x軸はエポック数を表し、y軸は損失値(MSE)を表します。
エポック数が増えるにつれて損失がどのように減少しているかを示します。
学習が進行するにつれて損失が減少することが期待されます。
損失が減少し続けることで、モデルがトレーニングデータに適応していることが示されます。
2. テスト損失の値
- 学習が完了した後、テストデータを用いてモデルの評価を行います。
その結果として、テストデータに対する予測と実際の評価との間のMSE(平均二乗誤差)が表示されます。
MSEは予測と実際の評価の差を表す指標であり、値が小さいほど予測が正確であることを示します。
テスト損失の値が小さい場合は、モデルがテストデータに対してより正確な予測を行っていることを示します。
なお、具体的な数値によって結果がどのように表示されるかはデータや学習の状況により異なりますが、一般的には損失のグラフが学習回数に応じて減少し、テスト損失が小さくなることが期待されます。
これは、モデルがデータに適応し、過学習(オーバーフィッティング)を避けるように学習が進行していることを示します。