
選挙結果予測
選挙に関するデータ分析の一例として、選挙結果を予測するモデルを作成してみましょう。
ここでは、選挙の候補者の年齢、教育レベル、キャンペーンの予算などを特徴として使用します。
これらの特徴を基に、候補者が選挙に勝つかどうかを予測します。
まず、サンプルデータを作成します。
ここでは、pandasとnumpyを使用します。
1 | import pandas as pd |
次に、scikit-learnを使用してデータを訓練セットとテストセットに分割し、ロジスティック回帰モデルを訓練します。
1 | from sklearn.model_selection import train_test_split |
最後に、matplotlibを使用して結果をグラフ化します。
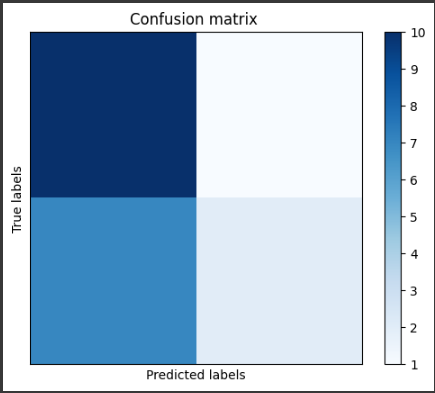
ここでは、テストデータの予測結果と実際の結果を比較する混同行列を作成します。
1 | import matplotlib.pyplot as plt |
[実行結果]
このコードはあくまで一例であり、実際の選挙データ分析では、より多くの特徴を考慮に入れ、より複雑なモデルを使用することが一般的です。
また、データの前処理や特徴選択、モデルの評価など、ここでは触れていない重要なステップもあります。
ソースコード解説
以下にソースコードの詳細な説明を示します:
1行目と2行目では、pandasとnumpyをインポートしています。
pandasはデータ解析や操作を行うためのライブラリであり、numpyは数値計算を行うためのライブラリです。
5行目から11行目では、データセットを作成しています。
np.random.seed(0)は乱数のシードを設定し、再現性を確保しています。
dataには4つの特徴(年齢、教育レベル、キャンペーン予算、選挙結果)を持つ100行のデータが生成されます。
12行目では、作成したデータを使ってpandasのDataFrameを作成しています。
22行目では、scikit-learnのtrain_test_splitを使用してデータを訓練セットとテストセットに分割しています。
Xには特徴量のカラム(’年齢’、’教育レベル’、’キャンペーン予算’)が代入され、yにはラベルのカラム(’選挙結果’)が代入されます。
test_size=0.2はテストセットの割合を指定しており、random_state=0は乱数のシードを設定して再現性を確保しています。
25行目では、scikit-learnのLogisticRegressionを使用してロジスティック回帰モデルを作成しています。
28行目と29行目では、matplotlibのpyplotモジュールとscikit-learnのconfusion_matrixをインポートしています。
32行目では、作成したモデルを使用してテストデータの予測を行っています。
35行目では、予測結果と真のラベルを用いて混同行列を作成しています。
38行目から45行目では、混同行列をグラフ化しています。
plt.imshow()で混同行列を表示し、plt.xlabel()、plt.ylabel()で軸ラベルを設定しています。
plt.xticks([], [])とplt.yticks([], [])は軸の目盛りを非表示にしています。
plt.title()でグラフのタイトルを設定し、plt.colorbar()でカラーバーを表示しています。
最後のplt.show()でグラフを表示します。
このソースコードは、訓練セットとテストセットの分割、ロジスティック回帰モデルの訓練、テストデータの予測、混同行列の作成とグラフ化を順番に行っています。