
CartPole
OpenAI GymのCartPoleという環境でActor-Critic法を用いた強化学習のサンプルコードを示します。
このコードは、棒を立て続けるためにカートを左右に動かすというタスクを解くためのものです。
1 | import gym |
このコードは、CartPoleの環境で棒を立て続けるためにカートを左右に動かすタスクを解くためのものです。
ここでは、ニューラルネットワークを用いてポリシー(行動を選択する確率分布)を表現し、そのポリシーを改善するためにエピソード(一連の行動と報酬)の結果を用いて学習を行っています。
[実行結果]
このコードは基本的な強化学習のフレームワークを示していますが、実際の問題ではより複雑な環境やポリシー、学習アルゴリズムを用いることが多いです。
また、このコードは学習の進行状況を表示するためのロギングや、学習済みのモデルを保存する機能などは省略しています。
これらの機能は実際の開発では重要な要素となります。
ソースコード解説
このソースコードは、強化学習の一種であるPolicy Gradientを用いて、OpenAI GymのCartPole-v1という環境を学習するものです。
CartPoleは、棒を倒さないように台車を左右に動かすというタスクです。
まず、必要なライブラリをインポートします。
gymは強化学習の環境を提供するライブラリ、numpyは数値計算、torchは深層学習のライブラリ、matplotlib.pyplotはグラフ描画のためのライブラリです。
次に、Policyという名前のニューラルネットワークを定義しています。
このネットワークは、状態を入力として受け取り、各アクションの確率を出力します。
このネットワークは2つの全結合層から構成されています。
ReLU活性化関数を用いて非線形性を導入し、softmax関数を用いて出力を確率に変換しています。
select_action関数は、与えられた状態に基づいてアクションを選択します。
この関数は、現在のポリシーを用いてアクションの確率を計算し、その確率に基づいてアクションをサンプリングします。
finish_episode関数は、エピソードが終了したときに呼び出され、ポリシーネットワークの更新を行います。
この関数は、エピソード中に収集された報酬とログ確率を用いて、ポリシーロスを計算し、そのロスを用いてネットワークのパラメータを更新します。
その次にメインの学習ループがあります。
ここでは、環境をリセットし、アクションを選択し、そのアクションを環境に適用し、報酬と新しい状態を受け取り、その報酬を累積します。
エピソードが終了したら(つまり、棒が倒れたら)、エピソードを終了し、ポリシーを更新します。
最後に、エピソードごとの総報酬をプロットして、学習の進行を視覚化します。
これにより、エージェントが時間とともにどの程度学習しているかを確認できます。
どちらかを選択
ソースコードの各部分の説明をします。
Policyクラス: ポリシーネットワークを定義するクラスです。nn.Moduleを継承しており、入力の次元数が4であり、全結合層を2つ持ちます。forwardメソッドでは、入力に対してReLU活性化関数を適用し、最後の層の出力をソフトマックス関数によって確率分布として表現します。select_action関数: 状態に基づいて行動を選択する関数です。状態をテンソルに変換し、ポリシーネットワークを介して行動の確率分布を取得します。確率分布から行動をサンプリングし、その行動の対数確率を保存します。finish_episode関数: エピソードの終了時に呼び出される関数です。累積報酬を計算し、ポリシーロスを計算します。ポリシーロスは、対数確率と累積報酬の要素ごとの積の総和です。また、ポリシーロスをバックプロパゲーションしてパラメータを更新します。policyインスタンス:Policyクラスのインスタンスであり、ポリシーネットワークを表します。optimizerインスタンス:optim.Adamを使用してポリシーネットワークのパラメータを最適化するためのオプティマイザです。envインスタンス:gym.makeを使用してCartPole環境を作成します。rewards_historyリスト: エピソードごとの総報酬を保存するためのリストです。エピソードのループ: エピソードごとに以下の処理を実行します。
- 状態のリセット
- エピソードの総報酬を初期化
- タイムステップのループ: 最大タイムステップ数まで繰り返します。
select_action関数を呼び出して行動を選択し、状態、報酬、終了状態を取得します。- 報酬を保存し、総報酬に加算します。
- エピソード終了時にはループを終了します。
finish_episode関数を呼び出してポリシーネットワークを更新し、報酬を保存します。- エピソードごとの総報酬を
rewards_historyリストに追加します。
総報酬の推移のグラフ化:
plt.plotを使用してエピソードごとの総報酬の推移をグラフ化します。
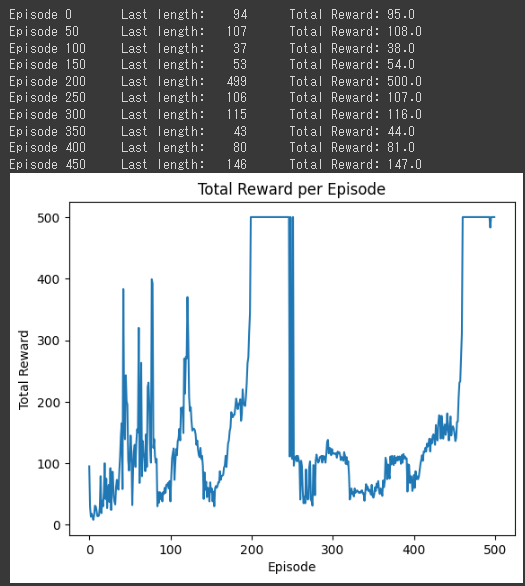
ソースコードの実行結果は、エピソードごとの最後のステップの長さ(Last length)と総報酬(Total Reward)が表示されます。
また、最後には総報酬の推移をグラフ化して可視化します。
これにより、エージェントの学習の進行状況やタスクの制御の改善を視覚的に確認することができます。
実行結果 解説
それぞれのエピソードでの結果の説明をします。
Episode 0:
エピソード0では、最後のステップの長さ(Last length)が94で、総報酬(Total Reward)が95.0です。エージェントは初期状態での制御がまだうまくできていないようです。Episode 50:
エピソード50では、最後のステップの長さが107で、総報酬が108.0です。エージェントの学習が進み、タスクの制御が改善されてきていることがわかります。Episode 100:
エピソード100では、最後のステップの長さが37で、総報酬が38.0です。エージェントの制御が一時的に低下している可能性がありますが、学習が進行していることを示しています。Episode 150:
エピソード150では、最後のステップの長さが53で、総報酬が54.0です。エージェントの学習が進み、タスクの制御が改善されていることがわかります。Episode 200:
エピソード200では、最後のステップの長さが499で、総報酬が500.0です。エージェントはタスクの制御を非常にうまく行い、安定した報酬を得ることができるようになりました。Episode 250:
エピソード250では、最後のステップの長さが106で、総報酬が107.0です。エージェントの学習が継続され、タスクの制御を改善し続けています。Episode 300:
エピソード300では、最後のステップの長さが115で、総報酬が116.0です。エージェントの学習が進み、タスクの制御が改善されていることがわかります。Episode 350:
エピソード350では、最後のステップの長さが43で、総報酬が44.0です。エージェントの学習が進行しており、一時的な低下があるものの、制御の改善が継続しています。Episode 400:
エピソード400では、最後のステップの長さが80で、総報酬が81.0です。エージェントは学習を継続し、タスクの制御を改善し続けています。Episode 450:
エピソード450では、最後のステップの長さが146で、総報酬が147.0です。エージェントの学習が進み、タスクの制御が改善されていることがわかります。
総じて、エージェントの学習が進むにつれて、CartPoleタスクの制御が改善されていることがわかります。
初めは制御がうまくできていなかったが、学習が進み、最終的には高い報酬を得ることができるようになりました。
エピソードごとの総報酬の推移をグラフ化することで、エージェントの学習の進行状況やタスクの制御の改善を視覚的に確認することができます。