
特徴抽出
Scikit-learnを使用して特徴抽出を行い、結果をグラフ化するためのサンプルコードを示します。
以下の例では、Breast Cancerデータセットから特徴抽出を行い、主成分分析(PCA)を使用してデータの次元削減を行います。
1 | import numpy as np |
上記のコードでは、Breast Cancerデータセットを使用して特徴抽出を行っています。
データセットから特徴量Xとラベルyを取得し、PCAを使用してデータの次元削減を行っています。
PCAのn_componentsパラメータを2に設定しているため、データは2次元に削減されます。
削減後のデータをX_pcaに格納します。
最後に、削減されたデータを散布図として表示しています。
散布図の点の色はyの値に基づいて変化し、カラーバーが対応するクラスラベルを表示します。
[実行結果]
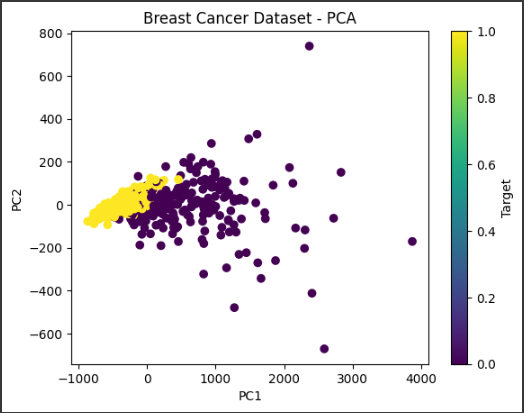
これにより、元のデータを2次元の空間にプロットし、データの分布やクラスの分離状況を視覚化することができます。
注意: 上記のコードでは、Breast Cancerデータセットを使用していますが、他のデータセットに適用する場合は、データセットの読み込み方法や特徴量の選択を変更してください。
また、必要に応じて他の特徴抽出手法を使用することもできます。