
アノマリ検知
アノマリ検知の一つの例として、Isolation Forestを使ったアノマリ検知を紹介します。
Isolation Forestは、異常値を見つけるための効果的な方法で、特に高次元のデータセットに対して有効です。
以下にPythonとScikit-learnを使ったサンプルコードを示します。
このコードでは、2次元のデータセットを生成し、Isolation Forestを使ってアノマリを検出し、結果をグラフ化します。
1 | import numpy as np |
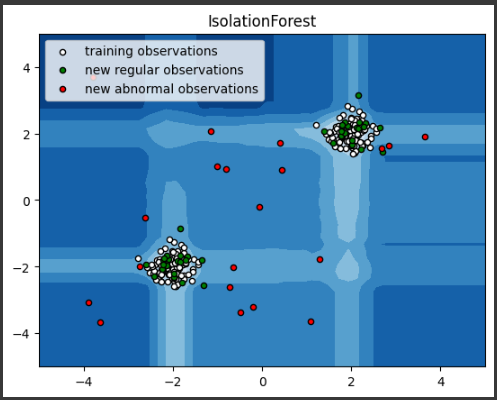
このコードを実行すると、正常なデータポイント(白と緑の点)と異常なデータポイント(赤い点)がプロットされます。
Isolation Forestは、異常なデータポイントを効果的に検出します。
[実行結果]
ソースコード解説
このソースコードは、Isolation Forest(孤立性森)アルゴリズムを使用してアノマリ検知を行う例です。
以下にソースコードの各部分を詳しく説明します。
1. ライブラリのインポート:
1 | import numpy as np |
必要なライブラリをインポートします。NumPyは数値計算を行うために使用し、Matplotlibはグラフの描画に使用します。
IsolationForestはScikit-learnのアノマリ検知アルゴリズムです。
2. データの生成:
1 | rng = np.random.RandomState(42) |
正常なデータポイント(X_train)と新しい正常なデータポイント(X_test)を生成します。
また、異常なデータポイント(X_outliers)も生成します。
3. Isolation Forestの適用:
1 | clf = IsolationForest(max_samples=100, random_state=rng) |
IsolationForestクラスのインスタンスを作成し、X_trainを使用してモデルをトレーニングします。
そして、トレーニングデータとテストデータ、異常データそれぞれのアノマリスコアを予測します。
4. プロット:
1 | xx, yy = np.meshgrid(np.linspace(-5, 5, 50), np.linspace(-5, 5, 50)) |
アノマリスコアをグラフ化し、データポイントをプロットします。等高線プロットはアノマリスコアのレベルを示し、青い色が正常である領域を表します。
また、正常データポイントは白色で、新しい正常データポイントは緑色、異常データポイントは赤色でプロットされます。
これにより、Isolation Forestアルゴリズムによるアノマリ検知の結果が可視化されます。
グラフを通じて、異常データポイントが正常データから分離される様子を確認できます。