
クレジットスコアリング
クレジットスコアリングの一例として、ロジスティック回帰を用いた二項分類問題を考えてみましょう。
この例では、顧客がローンを返済する(1)かしない(0)かを予測します。
特徴量としては、年齢と収入を考えてみます。
まず、必要なライブラリをインポートし、仮想のデータセットを作成します。
1 | import numpy as np |
次に、データを訓練セットとテストセットに分割し、ロジスティック回帰モデルを訓練します。
1 | # 特徴量とターゲットに分割 |
最後に、訓練したモデルを用いてテストセットのデータを予測し、結果をグラフ化します。
1 | # テストセットのデータを予測 |
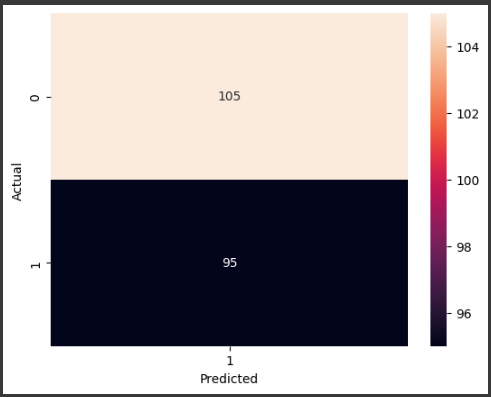
このヒートマップは混同行列を表しており、モデルがどの程度正確に予測できているかを視覚的に理解するのに役立ちます。
[実行結果]
ソースコード解説
コードの詳細な説明は下記の通りです。
1. import ステートメント:
必要なライブラリやモジュールをインポートします。numpy、pandas、sklearn、matplotlib.pyplot、seabornが使用されています。
2. 仮想データセットの作成:
numpy.randomを使って、age(年齢)、income(収入)、will_pay_back(返済するかどうか)の3つの特徴量を持つ仮想的なデータセットを作成します。
これらの特徴量はランダムな値で生成されます。
3. データフレームの作成:
pandas.DataFrameを使って、上記で生成した特徴量を含むデータフレーム df を作成します。
4. 特徴量とターゲットの分割:
df から特徴量 X(’age’と’income’)とターゲット変数 y(’will_pay_back’)を分割します。
5. 訓練セットとテストセットの分割:
sklearn.model_selection.train_test_split を使って、データを訓練セットとテストセットに分割します。
ここでは、テストセットのサイズを設定し、乱数のシードを固定して再現性を確保しています。
6. ロジスティック回帰モデルの訓練:
sklearn.linear_model.LogisticRegression を使って、ロジスティック回帰モデルを作成し、訓練セットを用いてモデルを訓練します。
7. テストセットのデータを予測:
訓練されたモデルを使って、テストセットの特徴量 X_test を予測します。
8. 結果のグラフ化:
予測結果と実際のターゲット変数 y_test をもとに、混同行列(confusion matrix)を作成し、seaborn.heatmap を使って可視化します。
混同行列は、予測されたクラスと実際のクラスの組み合わせごとにカウントされます。
9. plt.show():
グラフを表示します。
このコードを実行すると、ロジスティック回帰モデルを使って返済するかどうかを予測し、混同行列をグラフ化することができます。
混同行列は、予測の正確性や誤分類の種類を評価するのに役立ちます。