
詐欺検出
金融取引の詐欺検出の例題として、以下のデータセットを考えます。
1 | import numpy as np |
この例では、Isolation Forestと呼ばれるアルゴリズムを使用して詐欺検出を行っています。
Isolation Forestは、データの異常度を評価し、異常なデータポイントを検出するために使用されます。
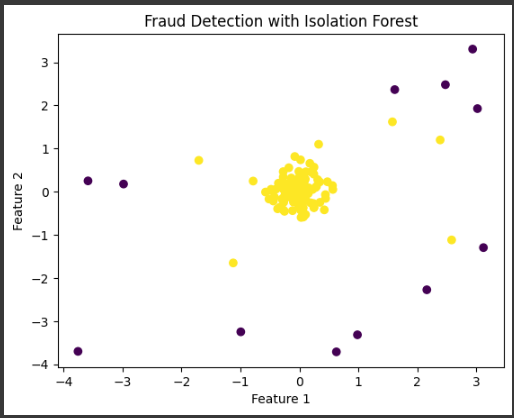
結果をグラフ化すると、データポイントが異常かどうかに応じて色分けされた散布図が表示されます。
異常なデータポイントは通常、他のデータポイントからは明らかに分離していることが視覚的に確認できます。
異常なデータポイントは、詐欺の可能性が高いと考えられます。
上記のコードを実行すると、詐欺検出の結果をグラフで確認することができます。
[実行結果]
コード解説
このコードは、Isolation Forestを使用して金融取引の詐欺検出を行い、結果をグラフ化するためのものです。
以下に各部分の説明をします。
1行目から3行目:
必要なライブラリをインポートします。numpyは数値計算のために使用され、matplotlib.pyplotはグラフの描画に使用されます。sklearn.ensembleからはIsolation Forestモデルをインポートします。
6行目から9行目:
サンプルデータの生成を行います。numpy.random.RandomStateを使用して乱数のシードを設定し、乱数を用いて2次元のデータセットXを生成します。X_outliersは異常値を表すデータセットです。最後にnp.vstackを使用してXとX_outliersを結合します。
12行目:
IsolationForestクラスのインスタンスを作成します。contaminationパラメータは異常値の割合を指定し、random_stateパラメータは乱数のシードを指定します。
13行目:
fitメソッドを使用してIsolation Forestモデルをデータに適合させます。
13行目:
predictメソッドを使用してデータポイントの異常度を予測します。
異常であれば-1、正常であれば1のラベルが返されます。
17行目から21行目:
結果を可視化します。plt.scatterを使用してデータポイントを散布図として表示します。cパラメータをy_predとし、異常度に応じて色を付けます。plt.title、plt.xlabel、plt.ylabelを使用してグラフにタイトルや軸ラベルを追加します。
最後の行で、グラフを表示します。
このコードを実行すると、生成されたデータセット上での詐欺検出結果を可視化したグラフが表示されます。
異常なデータポイントは異なる色で表示され、詐欺の可能性が高いと予測されます。