
交差検証
ythonとscikit-learnを使用して交差検証を行う基本的なコードを以下に示します。
この例では、K-Fold交差検証を使用します。
また、結果をグラフ化するためにmatplotlibを使用します。
1 | from sklearn.datasets import load_iris |
このコードは、Irisデータセットを使用して決定木分類器の交差検証を行います。
cross_val_score関数は、分類器、特徴量、ターゲット、および分割数(この場合は5)を引数に取り、各分割に対するスコアの配列を返します。
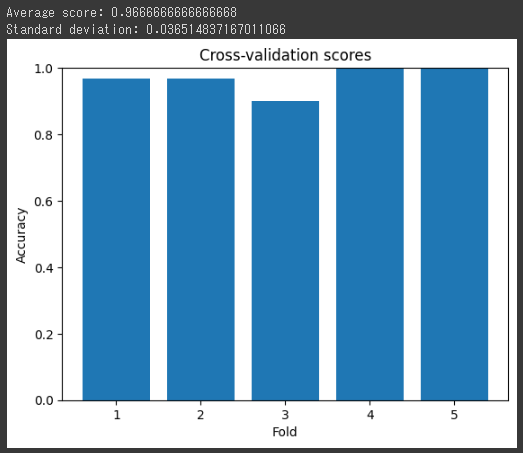
最後に、各分割のスコアを棒グラフで表示します。
これにより、モデルのパフォーマンスがどの程度一貫しているか(つまり、分割によって大きく変動しないか)を視覚的に確認できます。
[実行結果]
コード解説
このコードは、scikit-learnを使用して決定木分類器を交差検証するためのサンプルコードです。
以下にコードの詳細を説明します。
1行目から5行目:
必要なモジュールと関数をインポートします。load_iris関数は、Irisデータセットをロードするために使用されます。cross_val_score関数は、指定した分類器とデータセットで交差検証を行い、スコアを計算します。DecisionTreeClassifierは、決定木分類器のクラスです。matplotlib.pyplotモジュールは、グラフの可視化のために使用されます。numpyモジュールは、数値計算をサポートするために使用されます。
8行目から9行目:
load_iris関数を使用してIrisデータセットをロードし、Xとyに特徴量とラベルを格納します。
12行目:
DecisionTreeClassifierをインスタンス化します。random_stateパラメータは、再現性のために乱数生成器のシードを設定します。
15行目:
cross_val_score関数を使用して交差検証のスコアを計算します。cross_val_score関数は、指定された分類器とデータセットを使用して、指定された分割数(この場合は5)で交差検証を実行し、各分割のスコアを返します。
これらのスコアはscoresに格納されます。
18行目から21行目:
scoresの平均値と標準偏差を計算します。np.mean関数はスコアの平均を計算し、np.std関数はスコアの標準偏差を計算します。print関数では、平均スコアと標準偏差をコンソールに出力します。
24行目から29行目:
結果を棒グラフで可視化します。plt.bar関数を使用して棒グラフを作成し、plt.ylimでy軸の範囲を設定します。plt.xlabelとplt.ylabelでx軸とy軸のラベルを指定し、plt.titleでグラフのタイトルを設定します。
最後に、plt.showでグラフを表示します。
このコードは、Irisデータセットを使用して決定木分類器の交差検証を行い、結果を可視化する例です。
分類器やデータセットを変更することで、他の問題に対しても同様の手順を実行できます。