
作物の収量予測
scikit-learnを使って、作物の収量予測を行ってみます。
作物の栽培に関するいくつかの特徴量(例:土壌のpH値、日照時間、降水量)と作物の収量の関係を持つサンプルデータセットを作成し、予測を行います。
1 | import numpy as np |
この例では、土壌のpH値が作物の収量に与える影響を考慮しています。
他の特徴量(日照時間、降水量)も同様に考慮できます。
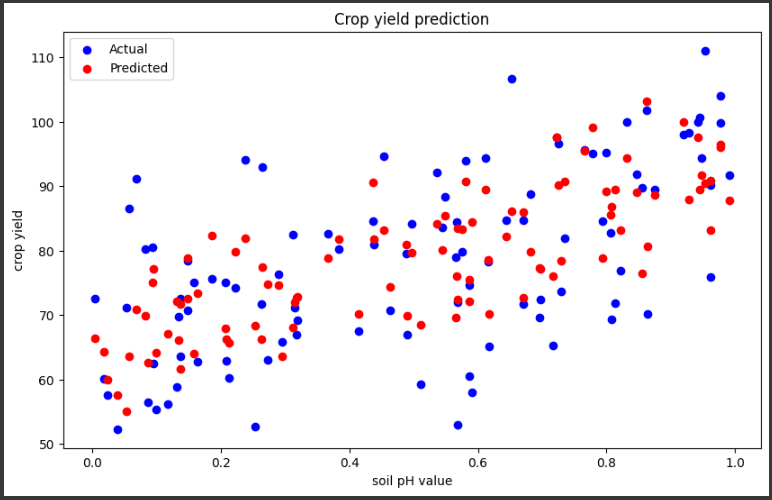
グラフでは、実際の収量(青色の点)と予測された収量(赤色の点)が表示されます。
線形回帰モデルがデータに最適化され、実際の収量に近い予測を行うことが期待されます。
[実行結果]
ソースコード解説
このソースコードは、作物の収量予測を行うためにscikit-learnとmatplotlibを使用しています。
以下にソースコードの詳細を説明します。
1. ライブラリのインポート:
numpyは数値計算を行うためのライブラリです。matplotlib.pyplotはデータの可視化を行うためのライブラリです。sklearn.linear_modelモジュールからLinearRegressionクラスをインポートしています。
2. サンプルデータの作成:
np.random.seed(0)は乱数のシードを設定しています。
これにより、再現可能な結果が得られます。n_samples = 100はサンプルの数を指定しています。X = np.random.rand(n_samples, 3)は、3つの特徴量(土壌のpH値、日照時間、降水量)を持つサンプルデータを作成しています。y = 50 + 30 * X[:, 0] + 20 * X[:, 1] + 10 * X[:, 2] + 10 * np.random.randn(n_samples)は、作物の収量を計算しています。特徴量と係数の線形結合に、ノイズとして正規分布からサンプリングした乱数を加えています。
3. 線形回帰モデルの学習と予測:
model = LinearRegression()はLinearRegressionクラスのインスタンスを作成しています。model.fit(X, y)は作成したモデルにデータをフィットさせて学習を行います。y_pred = model.predict(X)は学習済みモデルを使用して入力データXの収量を予測します。
4. 結果の可視化:
plt.figure(figsize=(10, 6))はグラフの図のサイズを指定しています。plt.scatter(X[:, 0], y, color='b', label='Actual')は実際の収量を散布図で表示しています。
X軸は土壌のpH値、Y軸は作物の収量です。plt.scatter(X[:, 0], y_pred, color='r', label='Predicted')は予測された収量を散布図で表示しています。plt.xlabel('soil pH value')はX軸のラベルを設定しています。plt.ylabel('crop yield')はY軸のラベルを設定しています。plt.title('Crop yield prediction')はグラフのタイトルを設定しています。plt.legend()は凡例を表示します。plt.show()はグラフを表示します。
このコードは、線形回帰モデルを使用して特徴量と作物の収量の関係を学習し、予測結果を可視化する例です。
特徴量には土壌のpH値だけでなく、他の特徴量も含めることができます。