レコメンデーションシステム Scikit-learn
Scikit-learn を使ってレコメンデーションシステムを実装する例として、k近傍法(K-Nearest Neighbors) を用いた協調フィルタリング(Collaborative Filtering)を紹介します。
以下は、ユーザーとアイテムの評価データを使って、ユーザーに対するアイテムのレコメンデーションを行うサンプルコードです。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 import numpy as npimport pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.neighbors import NearestNeighborsdata = pd.DataFrame({ 'user_id' : [1 , 1 , 2 , 2 , 3 , 3 , 4 , 4 , 5 , 5 ], 'item_id' : [1 , 2 , 1 , 3 , 2 , 3 , 1 , 4 , 4 , 5 ], 'rating' : [5 , 4 , 4 , 5 , 3 , 4 , 5 , 4 , 5 , 4 ] }) train_data, test_data = train_test_split(data, test_size=0.2 , random_state=42 ) user_item_matrix = train_data.pivot_table(index='user_id' , columns='item_id' , values='rating' ).fillna(0 ) model = NearestNeighbors(metric='cosine' , algorithm='brute' ) model.fit(user_item_matrix) user_id = 1 n_recommendations = 3 distances, indices = model.kneighbors(user_item_matrix.loc[user_id].values.reshape(1 , -1 ), n_neighbors=n_recommendations+1 ) similar_users_ratings = user_item_matrix.iloc[indices.flatten()[1 :]] mean_ratings = similar_users_ratings.mean(axis=0 ) recommended_items = mean_ratings[user_item_matrix.loc[user_id] == 0 ].sort_values(ascending=False ).index.tolist() print (f"ユーザー {user_id} におすすめのアイテム: {recommended_items[:n_recommendations]} " )
[実行結果]
ユーザー 1 におすすめのアイテム: [3, 4, 2]
このサンプルコードでは、仮のデータを使用していますが、実際のアプリケーションでは、ユーザーとアイテムの評価データを含むデータセットを用意する必要があります。
また、レコメンデーションの精度を向上させるために、ハイーパラメータの調整や他のアルゴリズムの検討も検討してください。
グラフ化
k近傍法を用いた協調フィルタリングによるレコメンデーションシステムをグラフで説明します。
まず、matplotlibを使ってデータを可視化し、その後、k近傍法の適用方法を説明します。
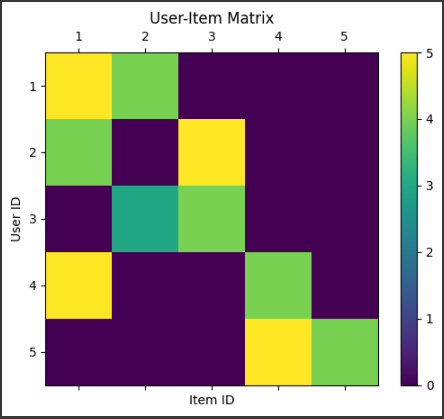
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.neighbors import NearestNeighborsdata = pd.DataFrame({ 'user_id' : [1 , 1 , 2 , 2 , 3 , 3 , 4 , 4 , 5 , 5 ], 'item_id' : [1 , 2 , 1 , 3 , 2 , 3 , 1 , 4 , 4 , 5 ], 'rating' : [5 , 4 , 4 , 5 , 3 , 4 , 5 , 4 , 5 , 4 ] }) user_item_matrix = data.pivot_table(index='user_id' , columns='item_id' , values='rating' ).fillna(0 ) fig, ax = plt.subplots() cax = ax.matshow(user_item_matrix, cmap='viridis' ) fig.colorbar(cax) ax.set_xticks(np.arange(len (user_item_matrix.columns))) ax.set_yticks(np.arange(len (user_item_matrix.index))) ax.set_xticklabels(user_item_matrix.columns) ax.set_yticklabels(user_item_matrix.index) plt.xlabel('Item ID' ) plt.ylabel('User ID' ) plt.title('User-Item Matrix' ) plt.show()
このグラフは、ユーザー-アイテム行列を表しています。
行はユーザーID、列はアイテムIDを表し、セルの色は評価値を示しています。
色が暗いほど評価が低く、色が明るいほど評価が高いことを示します。
k近傍法を適用する際、類似度を計算するためにコサイン類似度などの距離指標を使用します。
この例では、コサイン類似度を用いています。ユーザー間の類似度を計算し、最も類似度が高いk人のユーザーを見つけます。
その後、これらの類似ユーザーが高く評価したアイテムを推薦します。
[実行結果]
このグラフを使ってk近傍法を説明すると、例えばユーザー1に対してアイテムを推薦する場合、ユーザー1と類似した評価パターンを持つユーザー(この場合はユーザー2とユーザー3)を見つます。
次に、これらの類似ユーザーが高く評価したアイテムをユーザー1に推薦します。
この例では、アイテム3が推薦される可能性が高いです。