
糖尿病患者の病状進行予測 Scikit-learn
Scikit-learnは、Pythonの機械学習ライブラリで、分類、回帰、クラスタリング、次元削減などの機能が含まれています。
現実的な問題として、糖尿病患者のデータを使って、患者の1年後の病状進行を予測する回帰モデルを作成してみましょう。
この例では、Scikit-learnのデータセットから糖尿病患者のデータをロードし、線形回帰モデルを使って予測を行います。
まず、必要なライブラリをインポートします。
1 | import numpy as np |
次に、糖尿病患者のデータセットをロードします。
1 | diabetes = datasets.load_diabetes() |
データセットを説明変数(特徴量)と目的変数(1年後の病状進行)に分割します。
1 | X = diabetes.data |
データをトレーニングセットとテストセットに分割します(トレーニングセット:75%、テストセット:25%)。
1 | X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42) |
線形回帰モデルを作成し、トレーニングセットで学習させます。
1 | model = LinearRegression() |
モデルを使ってテストセットの予測を行い、平均二乗誤差(MSE)を計算してモデルの性能を評価します。
1 | y_pred = model.predict(X_test) |
[実行結果]
Mean squared error: 2848.3106508475053
この例では、糖尿病患者のデータを使って線形回帰モデルを作成し、1年後の病状進行を予測しました。
Scikit-learnを使って、さまざまな機械学習アルゴリズムを試すことができます。
現実的な問題に対して最適なモデルを選択し、パラメータを調整することで、より高い性能の予測モデルを作成することができます。
グラフ化
上記の例では、糖尿病患者のデータを使って線形回帰モデルを作成し、1年後の病状進行を予測しました。
予測結果をグラフ化して視覚的に評価するために、matplotlibというPythonのグラフ描画ライブラリを使用します。
まず、matplotlibをインポートします。
1 | import matplotlib.pyplot as plt |
次に、実際の目的変数(y_test)と予測値(y_pred)を散布図でプロットします。
対角線上にプロットされるほど、予測が正確であることを示します。
1 | plt.scatter(y_test, y_pred) |
[実行結果]
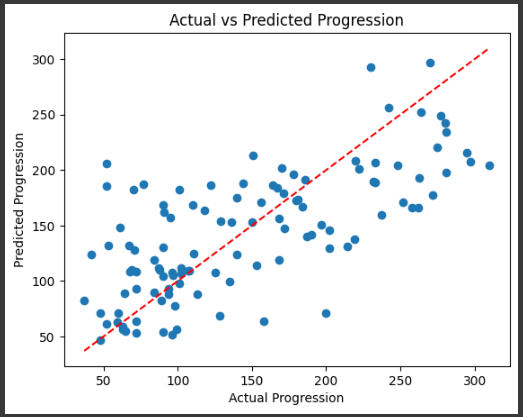
このグラフは、実際の病状進行(x軸)と予測された病状進行(y軸)を比較しています。
赤い破線は、予測が完全に正確である場合にデータポイントが存在するべき場所を示しています。
グラフから、多くのデータポイントが対角線の近くにあることがわかりますが、いくつかの外れ値も存在しています。
これは、モデルが完全に正確ではないことを示していますが、ある程度の予測性能があることがわかります。
このようなグラフを使って、モデルの性能を視覚的に評価することができます。
さらに、他の機械学習アルゴリズムを試したり、ハイパーパラメータを調整して、予測性能を向上させることができます。