HDBSCANを使ってクラスタリングを行います。
HDBSCANは、DBSCANを階層型クラスタリングのアルゴリズムに変換したもので、階層DBSCAN(Hierarchical DBSCAN)と呼ばれることもあります。
密度でグループを作成し、そのグループを距離に基づいて順次まとめていきます。
ライブラリのインストールとデータ生成
まずHDBSCANのライブラリをインストールします。(1行目)
2行目以降でデータ生成を行います。
密度の異なる3つの塊データを作成しています。
[Google Colaboratory]
1 | !pip install hdbscan |
[実行結果]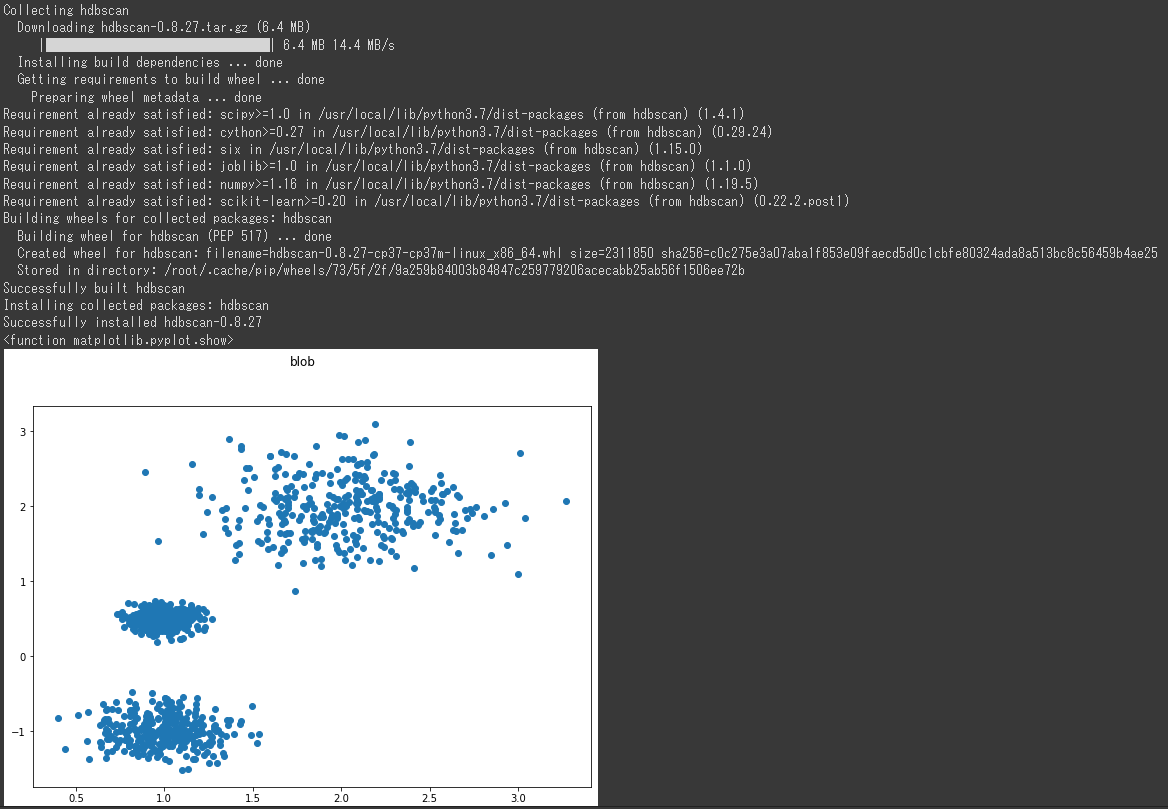
クラスタリング
比較のため、HDBSCAN(1~7行目)とDBSCAN(9~16行目)でクラスタリングを行います。
[Google Colaboratory]
1 | print("\nDBSCAN") |
[実行結果]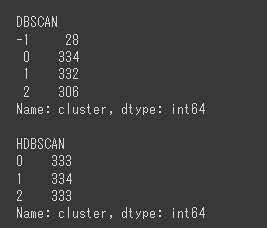
DBSCANは外れ値(-1)が少しありますが、HDBSCANは3つに分類されています。
クラスタリング結果の可視化
各クラスタリング結果を可視化します。
[Google Colaboratory]
1 | plt.figure(figsize=(10,3)) |
[実行結果]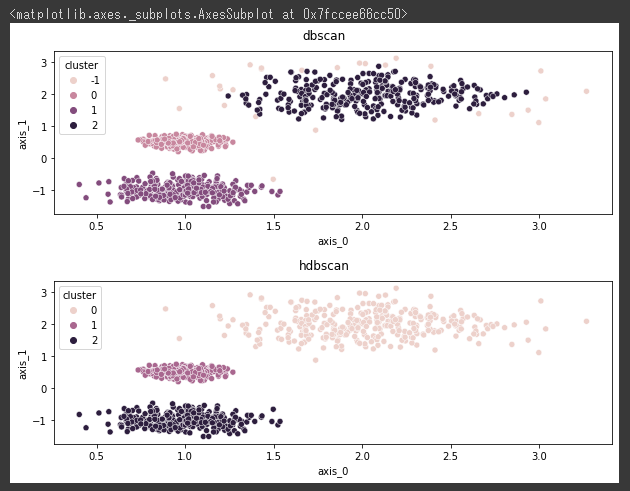
HDBSCAN(下図)は、塊ごとの密度の違いに対応できるアルゴリズムのため、きちんと3つに分類されています。
DBSCAN(上図)は密度の低い塊はノイズになっているようです。
2つのクラスタリングの使い分けポイントとしては、塊ごとに密度が違うかどうかという点になります。