ノイズ確認
DBSCANでは、どのクラスタにも所属しないノイズ点(外れ値)を分離できるという特徴があります。
前回実施した塊データのクラスタリングからクラスタごとのデータ数を確認します。
各クラスタのデータ数をカウントして、クラスタ番号でソートします。
[Google Colaboratory]
1 | pd.DataFrame(labels)[0].value_counts().sort_index() |
[実行結果]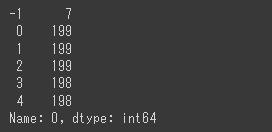
1列目がクラスタ番号で-1~4が付与されています。
2列目は所属クラスタのデータ数です。
ノイズはクラスタ番号が-1が付与されるので、7個のデータがノイズと分類されていることが分かります。
ノイズの可視化
続いてノイズデータの可視化を行います。
[Google Colaboratory]
1 | import seaborn as sns |
[実行結果]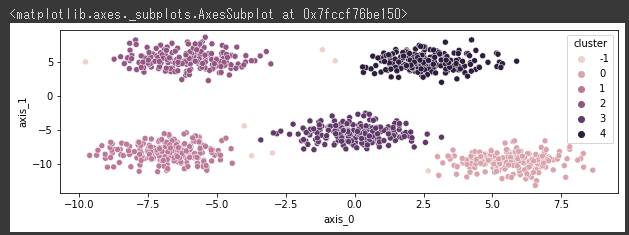
大きなクラスタから離れている点がクラスタラベルで-1でノイズ点となっています。
ノイズ点はクラスタリングの用途によっては除外しますが、反対に異常値として検知するために注目することもあります。