主成分分析(PCA:Principal Component Analysis)は、多次元データのもつ情報をできるだけ損なわずに低次元とする方法です。
次元削減で最も簡単な方法であり、広い分野で使われています。
アイリスデータの読み込み
まずアイリスデータを読み込みます。
結果の確認用にtarget_nameに正解の花の名称を追加しています。(5~8行目)
[Google Colaboratory]
1 | import pandas as pd |
[実行結果]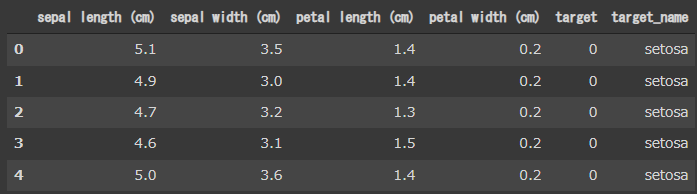
アイリスデータの散布図行列
読み込んだアイリスデータを散布図行列で可視化します。
hueパラメータに名称”target_name”を設定することで色をつけています。(2行目)
[Google Colaboratory]
1 | import seaborn as sns |
[実行結果]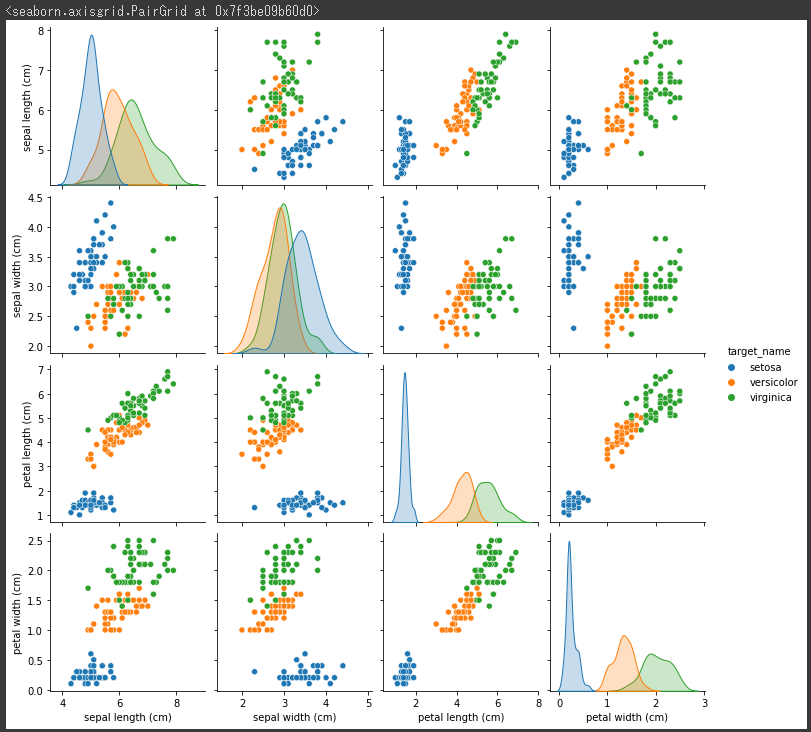
品種ごとに色分けされていて分類されていることは把握できますが、次元が多いため解釈するのが大変です。
アイリスの3次元立体図
花の品種ごとにpetal_width以外の情報を取得します。(5~6行目)
その後、3次元での可視化を行います。(7~12行目)
[Google Colaboratory]
1 | from matplotlib import pyplot as plt |
[実行結果]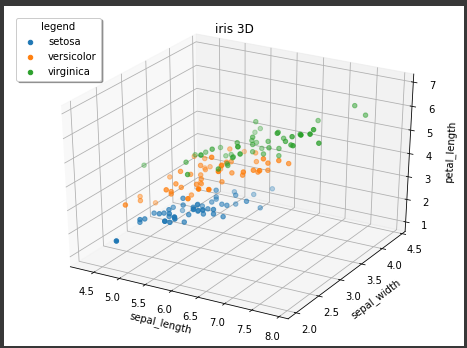
3品種に分かれているように見えますが、petal_widthの情報は全く無視してしまっています。
この情報が特徴量のある重要なデータだったという可能性もあります。
PCAを使用すれば、この4次元データを2次元データで表現することが可能になります。
PCA実行
PCAを実行し(3~4行目)、結果である主成分得点を表示します(5~8行目)。
[Google Colaboratory]
1 | from sklearn.decomposition import PCA |
[実行結果]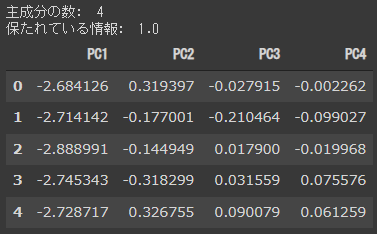
横軸が主成分(PC:Principal Component)で、縦軸が各サンプルを表します。
主成分(PC)とは、データを要約(縮小)したあとの新しい合成変数で、第1主成分(PC1)に最も多くの情報が集まっていて第2主成分(PC2)以降にだんだんと情報が小さくなります。
PC1とPC2を可視化
多くの情報が集まっているPC1とPC2を可視化します。
[Google Colaboratory]
1 | sns.scatterplot(x="PC1", y="PC2", data=df_pca, hue=df["target_name"]) |
[実行結果]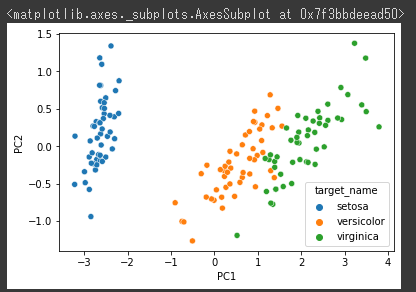
4次元あったデータを2次元で可視化することができました。
うまく3種類に分類されています。
PCAの用途はいくつかあるのですが、多次元データの特徴を低次元に次元削減し可視化する手段としてとても有効です。