MiniBatchKMeansでのクラスタリングを実行します。
ミニバッチとは部分的にサンプリングされた入力データのことです。
ミニバッチでクラスタリングを行うことにより、計算時間を大幅に短縮することができますが、k-meansと比べると少し精度が落ちることがあります。
MiniBatchKMeansでクラスタリング
データは前回同様にワインの分類データセットを使います。
比較のため、最初にk-meansのクラスタリング結果を可視化し(1~5行目)、その後にMiniBatchKMeansでクラスタリングを行ってから同じく可視化しています(7~14行目)。
MiniBatchKMeansモデルはcluster.MiniBatchKMeans関数で作成し、batch_sizeには100を設定しています。(7行目)
[Google Colaboratory]
1 | plt.figure(figsize=(10,3)) |
[実行結果]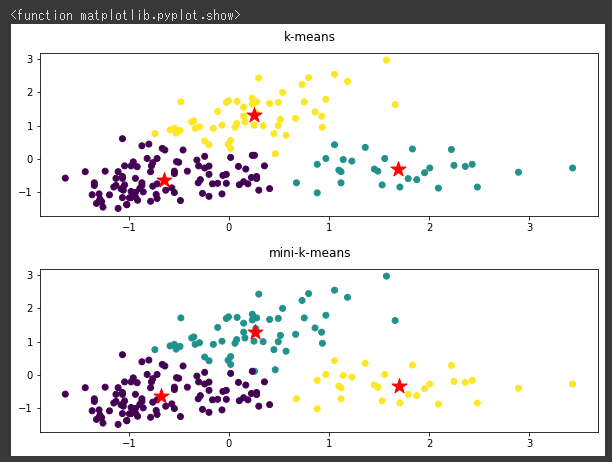
k-meansとMiniBatchKMeansの結果は、ほぼ同じとなりました。
MiniBatchKMeansでは、全データではなくbatch_size分のデータごとにk-meansを実行し、結果を更新する手法です。
データが1万個よりも多い場合はMiniBatchKMeansを使うことが推奨されています。
GMMモデルなどの感度のよいクラスタリングは計算時間がかかってしまいますので、データが多い場合はMiniBatchKMeansの利用を検討しましょう。