変分混合ガウスモデル(VBGMM:Variational Bayesian Gaussian Mixture)でのクラスタリングを試してみます。
VBGMMは、クラスタ数が不明な場合に有効な手法です。
複数のガウス分布を仮定して、各データがどのガウス分布に所属するのかを決定してクラスタ分析を行います。
MeanShiftとは違って、ベイズ推定に基づいて確率分布を計算しながらクラスタ数や分布の形状を決定します。
VBGMMでクラスタリング
データは前前前回使用したワインの分類データセットを使います。(前前前回記事を参照)
比較のため、最初にk-meansのクラスタリング結果を可視化し(1~5行目)、その後にGMMでクラスタリングを行ってから同じく可視化しています(7~15行目)。
VBGMMモデルはmixture.BayesianGaussianMixture関数で作成し、クラスタ数の上限としてn_componentsに10を指定しています。(8行目)
[Google Colaboratory]
1 | plt.figure(figsize=(10,3)) |
[実行結果]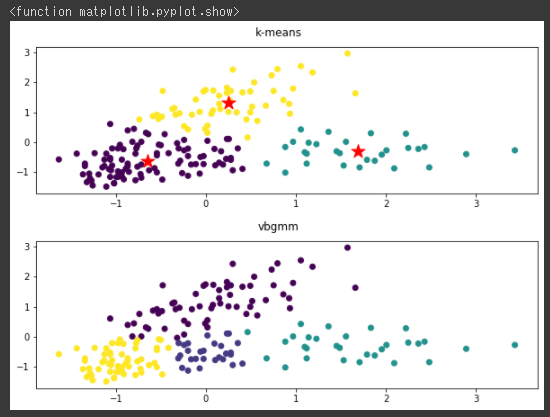
VBGMMで最適なクラスタ数を探す
VBGMMでは、weightsを参照するとクラスタごとの各データ分布を確認することができます。
縦軸がweightsで、横軸がクラスタ番号の棒グラフを作成します。(3行目)
[Google Colaboratory]
1 | x_tick =np.array([1,2,3,4,5,6,7,8,9,10]) |
[実行結果]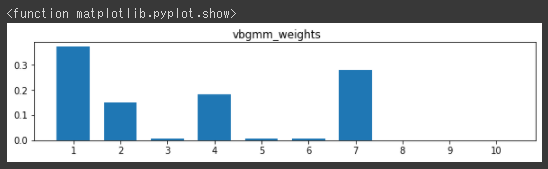
クラスタ数の上限(n_components)を10で実行しましたが、1つも分類されていないクラスタがあります。
クラスタ数の変更
グラフで見ると、だいたい3つ(クラスタ番号1~2と4と7)に分類されているので、n_componentsに3を設定して、もう一度クラスタリングを行います。(1行目)
[Google Colaboratory]
1 | vbgmm = mixture.BayesianGaussianMixture(n_components=3, random_state=0) |
[実行結果]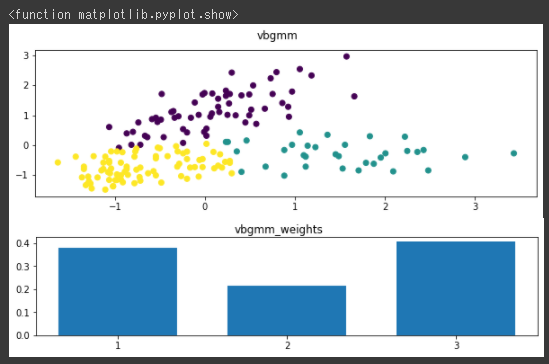
今回実施したように、VBGMMではweightsを確認して低い割合のクラスタがある場合は、n_componentsをさげて再度クラスタリングを行うという手順でクラスタ数を調整することが可能です。