今回は、SpectralClusteringでクラスタリングを行います。
SpectralClusteringはk-meansとは異なり、データ密度でクラスタを作成するため、同心円状になっていないデータもうまくクラスタリングを行うことができます。
k-meansではうまくクラスタリングできなくても、SpectralClusteringであればきちんとクラスタリングできるケースを確認していきます。
ムーンデータの生成
scikit-learnのサンプルデータセットであるムーンデータと呼ばれる三日月状のデータセットを生成します。
また、データ加工用・可視化用のライブラリもインポートしておきます。
[Google Colaboratory]
1 | import numpy as np |
[実行結果(途中略)]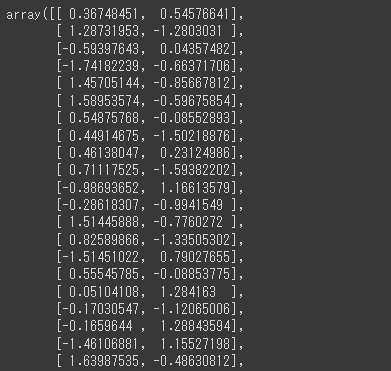
ムーンデータの可視化
生成したデータを可視化します。
[Google Colaboratory]
1 | x = X_norm[:,0] |
[実行結果]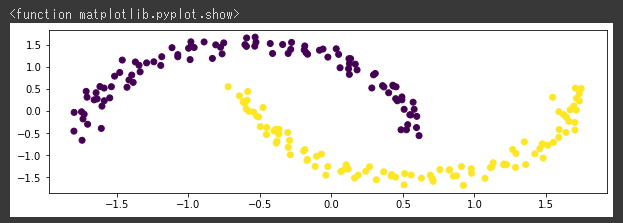
三日月の形をしたデータが上下に2つあることが分かります。
この2つにクラスタリングができれば良さそうです。
k-meansでクラスタリング
クラスタ数を2に設定してk-meansでクラスタリングを行ってみます。(1行目)
[Google Colaboratory]
1 | km = cluster.KMeans(n_clusters=2) |
[実行結果]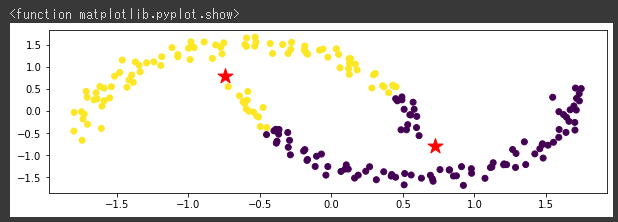
k-meansでは中心点からの距離でクラスタが決まるため、同心円状に広がっていないムーンデータではうまく分類できていないようです。
SpectralClusteringでクラスタリング
今度は、クラスタ数を同じく2に設定してSpectralClusteringでクラスタリングを行ってみます。(1行目)
パラメータのaffinity(親和性)は、クラスタリングを実施する際に作成するグラフ行列の作成法を設定します。
グラフ行列とは、「データがそれぞれどのようにつながっているか」を表す行列です。
設定している“nearest_neighbors”は、最近傍法を意味し「あるデータに対し、もっとも近いデータが属するクラスタに分類する」ことを意味します。
[Google Colaboratory]
1 | spc=cluster.SpectralClustering(n_clusters=2, affinity="nearest_neighbors") |
[実行結果]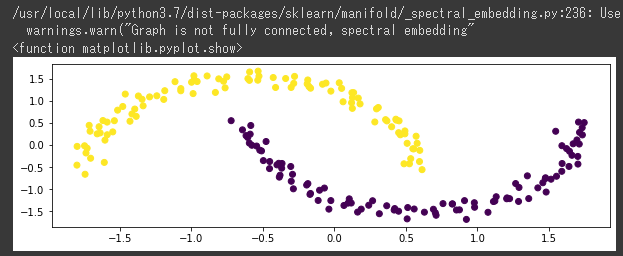
k-means法とは違い、データ密度でクラスタリングを作成するため、上下の三日月ごとにうまくクラスタリングできていることが分かります。