MeanShiftを使ったクラスタリングを行います。
MeanShiftはクラスタ数が分からない場合に、データをクラスタを分類する方法です。
複数のガウス分布(正規分布)を仮定して、各データがどのガウス分布に所属するのかを決定し、クラスタ分析を行います。
ワインの分類データセット
まず、オープンデータであるワインの分類データセットを準備します。
[Google Colaboratory]
1 | df_wine_all = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data", header=None) |
今回はワインの品種(0列目)、色(10列目)、プロリン量(13列目)を使用します。
[実行結果(一部略)]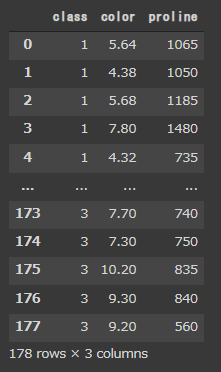
データセットを可視化
抽出したワインのデータセットを可視化します。
[Google Colaboratory]
1 | X = df_wine[["color","proline"]] |
[実行結果]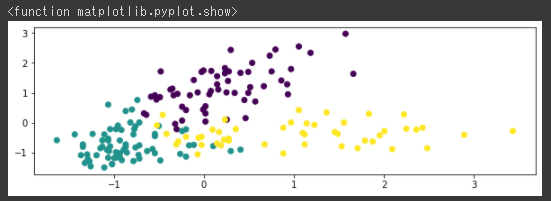
3品種ごとに色分けされたデータが確認できます。
k-meansでクラスタリング
k-meansでクラスタリングを行います。
品種ごとに3つに分類したいのでクラスタ数は3に設定します。
[Google Colaboratory]
1 | km = cluster.KMeans(n_clusters=3) |
[実行結果]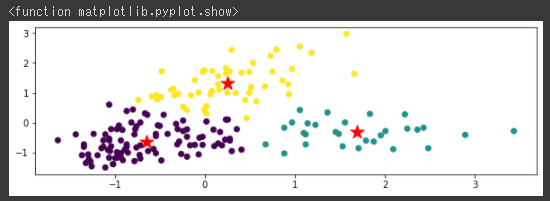
中心点から同心円状に広がって分類されていることが分かります。
MeanShiftでクラスタリング
MeanShift関数(1行目)を使って、MeanShiftでクラスタリングを行います。
[Google Colaboratory]
1 | ms = cluster.MeanShift(seeds=X_norm) |
[実行結果]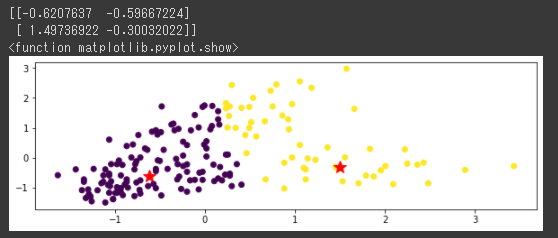
MeanShiftでは2つに分類されて実際の分類とはだいぶ違う結果となりました。
MeanShiftではクラスタ数を指定しなくてもクラスタリングが実施可能なので、パラメータはseeds(乱数シード)のみ設定しています。(1行目)
MeanShiftはk-meansをベースとして近いクラスタをまとめていき、既定の距離より近くなったクラスタをまとめて1つにします。