シルエット分析という方法で、最適なクラスタ数を探索してみます。
シルエット分析では次のような定義で適切なクラスタを推定します。
- クラスタ内は密になっているほど良い。
- 各クラスタは遠くに離れているほど良い。
シルエット分析はk-means以外のクラスタリング・アルゴリズムにも適応できます。
シルエット係数
前回のクラスタリング結果に対して、シルエット係数を算出します。
sklearnのライブラリを利用します。
[Google Colaboratory]
1
2
3
4
5
6
7
| import numpy as np
from matplotlib import cm
from sklearn.metrics import silhouette_samples
cluster_labels = np.unique(z_km.labels_)
n_clusters = cluster_labels.shape[0]
silhouette_vals = silhouette_samples(X, z_km.labels_)
|
n_clustersはラベルから取得したクラスタ数3を設定しています。(6行目)
silhouette_samplesにデータとラベルをすることで、シルエット係数を取得することができます。(7行目)
シルエット図
シルエット図を作成するコードは以下の通りです。
シルエット図は全てのサンプルを横向き棒グラフに表示したものになります。
[Google Colaboratory]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| y_ax_lower,y_ax_upper = 0,0
yticks = []
for i,c in enumerate(cluster_labels):
c_silhouette_vals = silhouette_vals[z_km.labels_==c]
print(len(c_silhouette_vals))
c_silhouette_vals.sort()
y_ax_upper += len(c_silhouette_vals)
color = cm.jet(float(i)/n_clusters)
plt.barh(range(y_ax_lower,y_ax_upper),
c_silhouette_vals,
height = 1.0,
edgecolor = "none",
color = color)
yticks.append((y_ax_lower+y_ax_upper)/2.)
y_ax_lower += len(c_silhouette_vals)
silhouette_avg = np.mean(silhouette_vals)
plt.axvline(silhouette_avg,color = "red",linestyle = "--")
plt.ylabel("Cluster")
plt.xlabel("Silhouette Coefficient")
plt.yticks(yticks,cluster_labels + 1)
|
適切にクラスタリングできていれば、各クラスタのシルエットの厚さが均等に近くなります。
シルエット係数は、-1から1の間の値をとり次のような意味になります。
- 1に近いほど、そのクラスタは他のクラスタから遠く離れていることを表す。
⇒うまくクラスタ分離できている
- 0に近いほど、隣接するクラスタと接近または隣接するクラスタと重なっていることを表す。
⇒クラスタの分離ができていない
- マイナスの場合は、クラスタ化されたサンプルは誤ったクラスタに所属している可能性あり。
- シルエットの厚さは、所属するサンプル数を表す。
[実行結果]
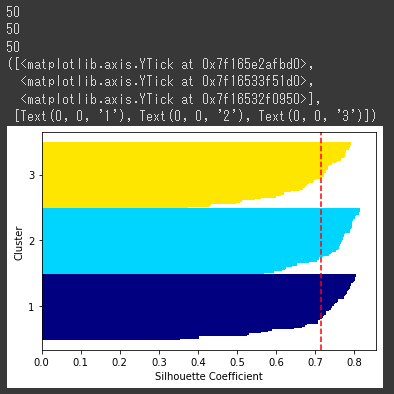
上記のシルエット図より、クラスタ数3でうまくクラスタリングができていることが分かります。
クラスタ数を2に変更
クラスタ数を2に変更(1行目)して散布図を描いてみます。
[Google Colaboratory]
1
2
3
4
5
6
7
8
9
10
| km = KMeans(n_clusters=2,
n_init=10,
max_iter=300,
random_state=0)
z_km=km.fit(X_norm)
plt.figure(figsize=(10,3))
plt.scatter(x,y, c=z_km.labels_)
plt.scatter(z_km.cluster_centers_[:,0],z_km.cluster_centers_[:,1],s=250, marker="*",c="red")
plt.show
|
[実行結果]
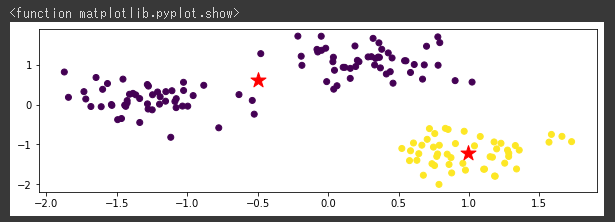
クラスタの中心点が、いまいちな位置になっていることが分かります。
クラスタ数2のシルエット図
クラスタ数2のシルエット図を表示します。
[Google Colaboratory]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| import numpy as np
from matplotlib import cm
from sklearn.metrics import silhouette_samples
cluster_labels=np.unique(z_km.labels_)
n_clusters=cluster_labels.shape[0]
silhouette_vals=silhouette_samples(X, z_km.labels_,metric="euclidean")
y_ax_lower,y_ax_upper=0,0
yticks=[]
for i,c in enumerate(cluster_labels):
c_silhouette_vals=silhouette_vals[z_km.labels_==c]
print(len(c_silhouette_vals))
c_silhouette_vals.sort()
y_ax_upper +=len(c_silhouette_vals)
color=cm.jet(float(i)/n_clusters)
plt.barh(range(y_ax_lower,y_ax_upper),
c_silhouette_vals,
height=1.0,
edgecolor="none",
color=color
)
yticks.append((y_ax_lower+y_ax_upper)/2.)
y_ax_lower += len(c_silhouette_vals)
silhouette_avg=np.mean(silhouette_vals)
plt.axvline(silhouette_avg,color="red",linestyle="--")
plt.ylabel("Cluster")
plt.xlabel("Silhouette coefficient")
plt.show
plt.yticks(yticks,cluster_labels + 1)
|
[実行結果]
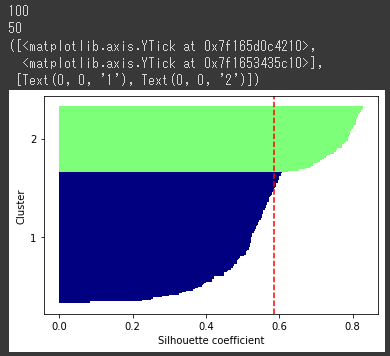
クラスタ1のシルエットが厚く、シルエット係数の平均値(赤い破線)よりもクラスタ1のほぼすべてのサンプルが下回っており、クラスタリングが上手くいっていないことが分かります。
つまりクラスタ数2よりもクラスタ数3のほうが、最適なクラスタ数だったということが導き出せます。


