k-means法を使う際の問題点の1つは、クラスタ数を指定しなければならないことです。
今回はエルボー法という方法で最適なクラスタ数を探索していきます。
エルボー法とは
クラスタリングの性能を数値化するには、クラスタ内の残差平方和(SSE)という指標を用います。
エルボー法は、クラスタの数を変えながら残差平方和(SSE)を計算し結果を図表することで適切なクラスタ数を推定する手法です。
サンプルデータの作成と可視化
サンプルデータを作成し、可視化を行います。
[Google Colaboratory]
1 | from sklearn.datasets import make_blobs |
[実行結果]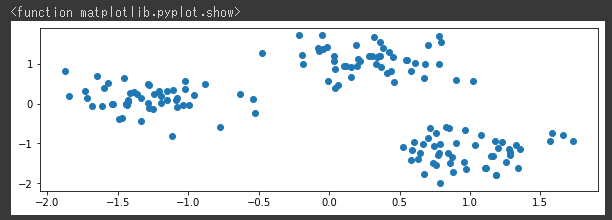
3つのグループに分かれたデータを作成することができました。
残差平方和(SSE)を算出
k-meansにてクラスタ数を1から10までのループし残差平方和(SSE)=km.inertia_を算出しリストに格納します。
残差平方和(SSE)が小さいほど歪みのない良いモデル(クラスタリングがうまくいっているモデル)ということになります。
[Google Colaboratory]
1 | distortions = [] |
[実行結果]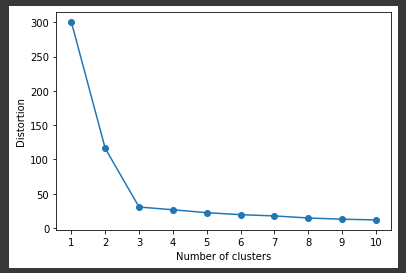
この図がエルボー図と呼ばれます。
クラスタ数3までは、残差平方和(SSE)が減少しクラスタ数4以降はほぼ横ばいとなっています。
エルボー法では、今回のデータにおいてのクラスタ数3のように急激に変化している点を最適なクラスタ数として選択します。
最適なクラスタ数でのクラスタリング
エルボー法で最適クラスタ数と導き出された3を指定して、クラスタリングを行います。
[Google Colaboratory]
1 | km = KMeans(n_clusters=3, |
[実行結果]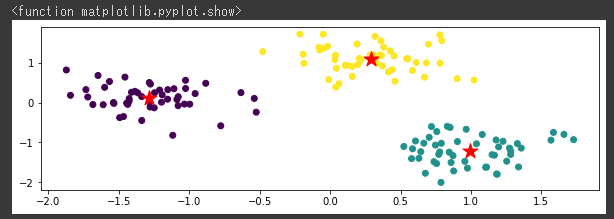
きれいに3つのクラスタ(グループ)に分類することができました。
エルボー法を用いることで、数値として根拠を持ったクラスタ数の探索が可能になることが分かりました。
ただ、かなり明確に分かれたデータでないとエルボー図はなだらかな曲線を描き最適なクラスタ数を判定するのが難しいため、万能な手法ではありません。
次回は別の方法でクラスタ数を探索していきます。