階層クラスタリングは、これまでの非階層クラスタリングとは違い最も距離が近くて似ている(類似度が高い)組み合わせからまとめていく方法です。
結果として出力される樹形図から、分類の過程でできるクラスタがどのように結合されていくかをひとつずつ確認できるため、最適なクラスタ数を後から決めることができます。
樹形図で視覚的に解釈がしやすいというメリットがある反面、非階層クラスタリングよりも計算量が多くなる傾向があるので結果がでるまでに時間がかかることがあります。
データセットの準備
階層クラスタリング用のデータセットを準備します。
まずscikit-learnのアヤメのデータセットを読み込みます。
解釈がしやすくなるようにサンプル数を10分の1に減らし、4つある説明変数も2つに減らします。(4行目)
選択したデータを最後に散布図に表示します。(10行目)
[Google Colaboratory]
1 | from sklearn.datasets import load_iris |
[実行結果]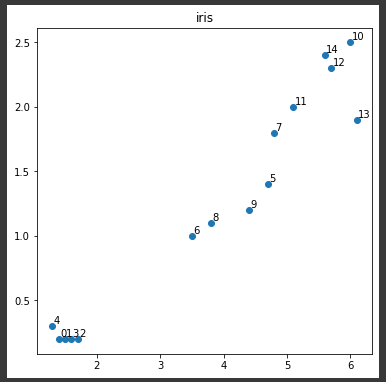
散布図に表示されている番号は、樹形図に出てくる番号に対応します。
(樹形図は次回表示します。)
階層クラスタリングの実行
scipyを使って階層クラスタリングを行います。
4行目のmethodには、ウォード法(ward)を設定しています。
ウォード法(ward)は、あるクラスタ同士が結合すると仮定したとき、結合後の全てのクラスタにおいて、クラスタの重心とクラスタ内の各点の距離の2乗和の合計が最小となるようにクラスタを結合させていく方法です。
同じく4行目のmetricには元のデータの点と点の距離の定義で、今回はユークリッド距離(euclidean)を指定しています。
ユークリッド距離とは、2点間の直線距離のことです。
[Google Colaboratory]
1 | import pandas as pd |
[実行結果]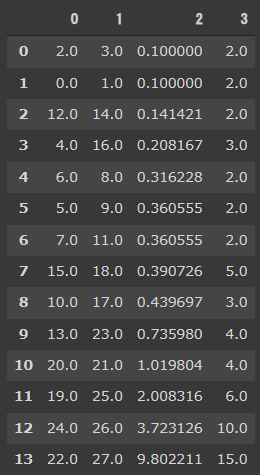
結果に出力したデータフレームZの意味は次の通りです。
- 1~2列目
結合されたクラスタの番号 - 3列目
クラスタ間の距離 - 4列目
結合後に新しくできたクラスタの中に入っている元のデータの数
次回は、今回の結果を樹形図に表示します。