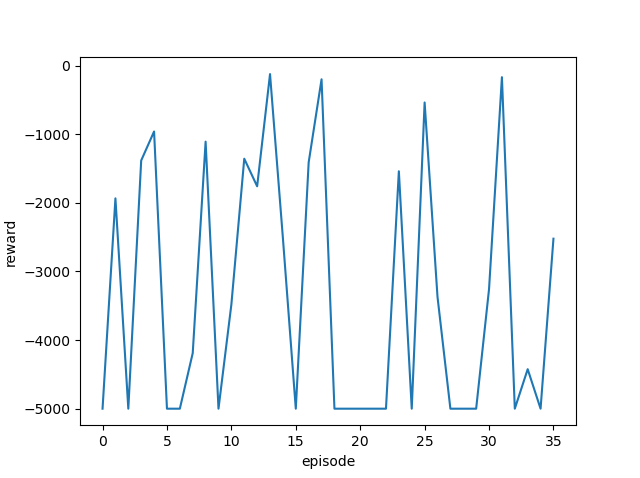
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
| import sys
import gym
import numpy as np
import gym.spaces
class MyEnv(gym.Env):
FIELD_TYPES = [
'S',
'G',
' ',
'山',
'☆',
'三',
'川',
'林',
]
MAP = np.array([
[0, 3, 3, 3, 2, 3, 7, 7, 3, 2, 2, 3],
[2, 2, 2, 2, 2, 2, 7, 3, 2, 2, 2, 2],
[3, 2, 3, 2, 3, 7, 7, 2, 2, 2, 2, 3],
[3, 2, 2, 2, 7, 7, 6, 6, 3, 3, 2, 2],
[7, 7, 3, 2, 6, 6, 6, 3, 7, 7, 3, 3],
[3, 2, 3, 2, 3, 7, 3, 1, 2, 7, 2, 2],
[3, 7, 2, 2, 3, 2, 3, 3, 3, 3, 2, 7],
[2, 2, 3, 2, 2, 3, 2, 3, 2, 3, 3, 2],
[7, 3, 2, 7, 7, 2, 2, 2, 7, 6, 6, 7],
[2, 3, 2, 6, 6, 6, 2, 3, 2, 7, 2, 2],
[3, 3, 2, 3, 2, 3, 6, 2, 3, 2, 2, 3],
[7, 2, 2, 2, 3, 3, 6, 2, 7, 3, 2, 2],
])
MAX_STEPS = 5000
def __init__(self):
super().__init__()
self.action_space = gym.spaces.Discrete(4)
self.observation_space = gym.spaces.Box(
low=0,
high=len(self.FIELD_TYPES),
shape=self.MAP.shape
)
self.reset()
def reset(self):
self.pos = self._find_pos('S')[0]
self.goal = self._find_pos('G')[0]
self.river = self._find_pos('川')
self.trees = self._find_pos('林')
self.start = self._find_pos('S')[0]
self.done = False
self.steps = 0
return self._observe()
def step(self, action):
if action == 0:
next_pos = self.pos + [0, 1]
elif action == 1:
next_pos = self.pos + [0, -1]
elif action == 2:
next_pos = self.pos + [1, 0]
elif action == 3:
next_pos = self.pos + [-1, 0]
if self._is_movable(next_pos):
self.pos = next_pos
moved = True
else:
moved = False
self.steps += 1
observation = self._observe()
reward = self._get_reward(self.pos, moved)
self.done = self._is_done()
return observation, reward, self.done, {}
def render(self, mode='console', close=False):
for row in self._observe():
for elem in row:
print(self.FIELD_TYPES[elem], end='')
print()
def _close(self):
pass
def _seed(self, seed=None):
pass
def _get_reward(self, pos, moved):
'''
if (self.start == pos).all(): # スタート位置に戻ってきたときのマイナス報酬
return -10
if moved:
if (self.goal == pos).all():
#return 3000
return 15000
for x in self.river:
if (x == pos).all():
return -10
for x in self.trees:
if (x == pos).all():
return -3
return -1
#return -3
else: # エージェントが動かなかった場合
return -10
'''
if (self.goal == pos).all():
return 500
else:
return -1
def _is_movable(self, pos):
return (
0 <= pos[0] < self.MAP.shape[0]
and 0 <= pos[1] < self.MAP.shape[1]
and self.FIELD_TYPES[self.MAP[tuple(pos)]] != '山'
)
def _observe(self):
observation = self.MAP.copy()
observation[tuple(self.pos)] = self.FIELD_TYPES.index('☆')
return observation
def _is_done(self):
if (self.pos == self.goal).all():
return True
elif self.steps > self.MAX_STEPS:
return True
else:
return False
def _find_pos(self, field_type):
return np.array(list(zip(*np.where(self.MAP == self.FIELD_TYPES.index(field_type)))))
|