今回は、学習率を微調整して結果がどう変わるか見ていきたいと思います。
[広くしたマップイメージ]
学習率の微調整
前回の結果より、学習率0.1~1.0付近でのゴール回数が多いように感じられました。
今回は学習率を0.5から1.5まで0.1ずつ増やしてその結果を確認していきたいと思います。
ソースの修正箇所は、26-36行目となります。
[ソース]
1 | # 警告を非表示 |
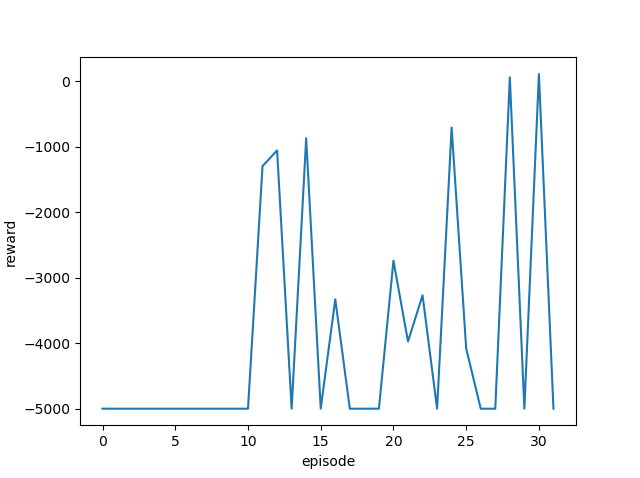
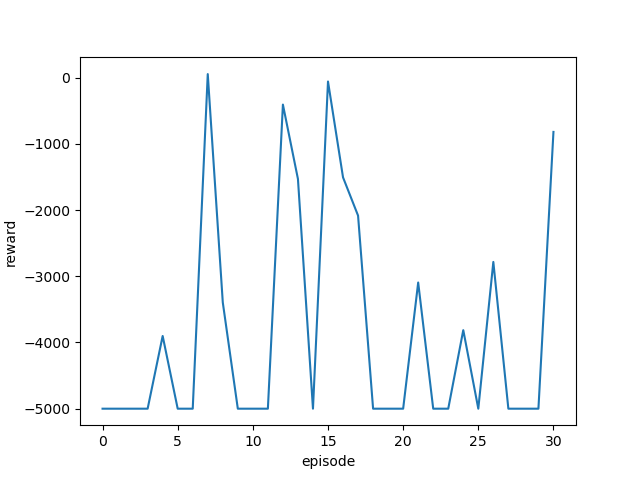
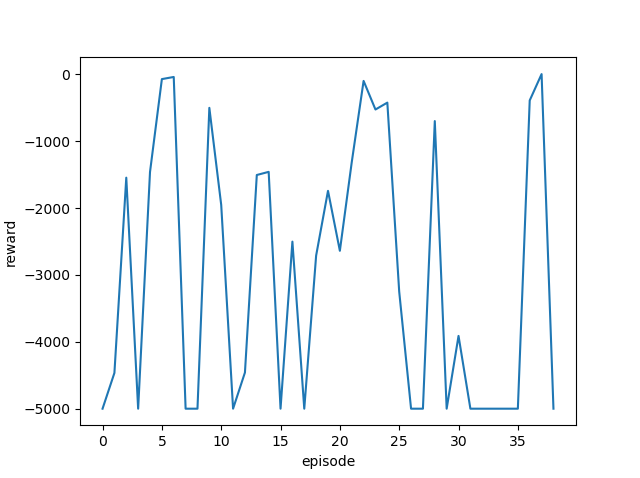
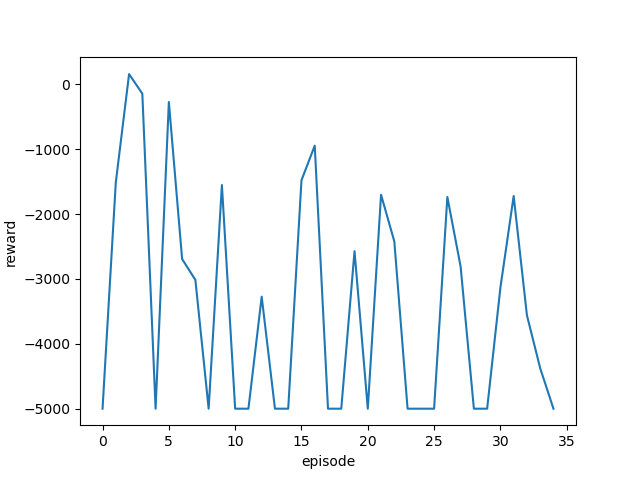
学習率を変更しながら実行し、それぞれの最終結果と平均報酬遷移(グラフ)を確認します。
[結果]
| 学習率 | 最終位置・最終報酬 | 平均報酬遷移 |
|---|---|---|
| 0.5 |  |
 |
| 0.6 |  |
 |
| 0.7 |  |
 |
| 0.8 |  |
 |
| 0.9 |  |
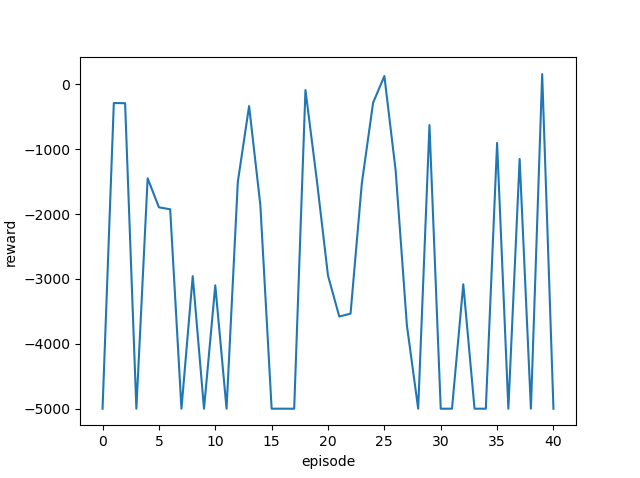 |
| 1.0 |  |
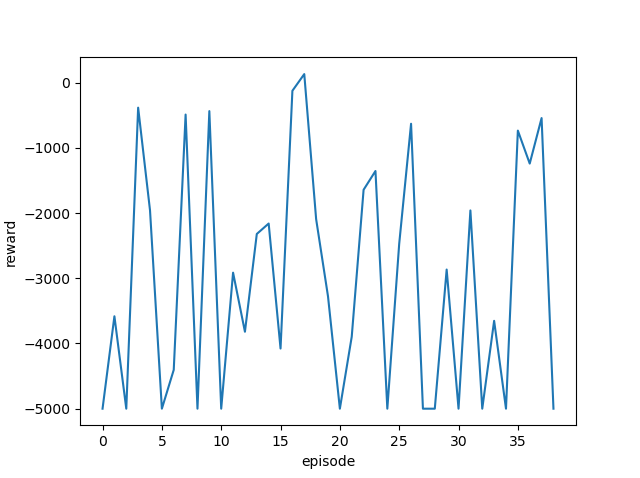 |
| 1.1 |  |
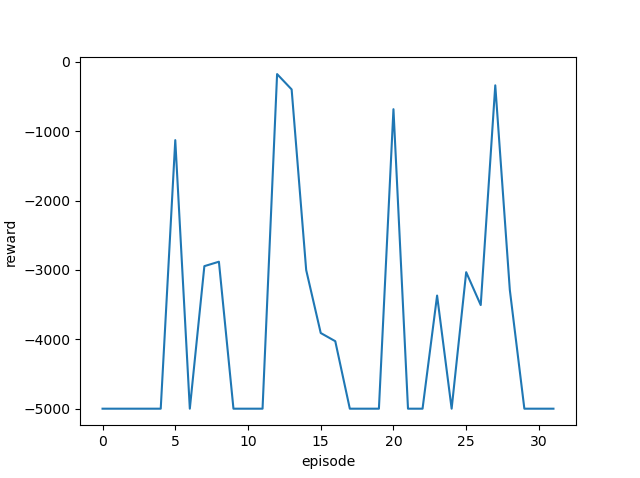 |
| 1.2 |  |
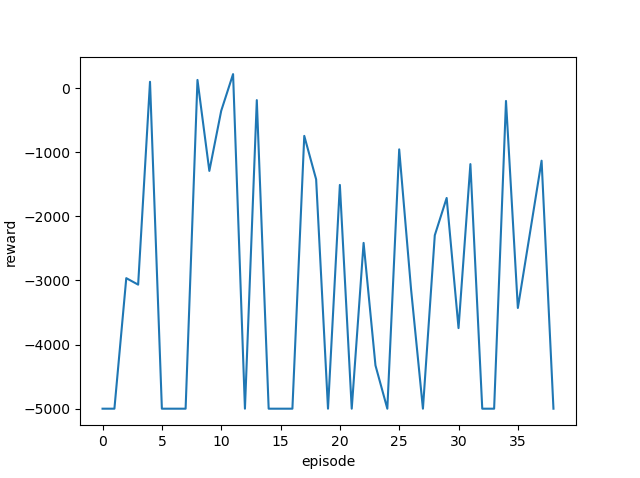 |
| 1.3 | 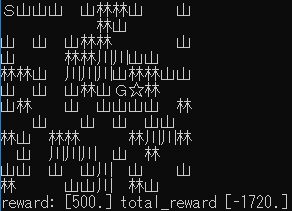 |
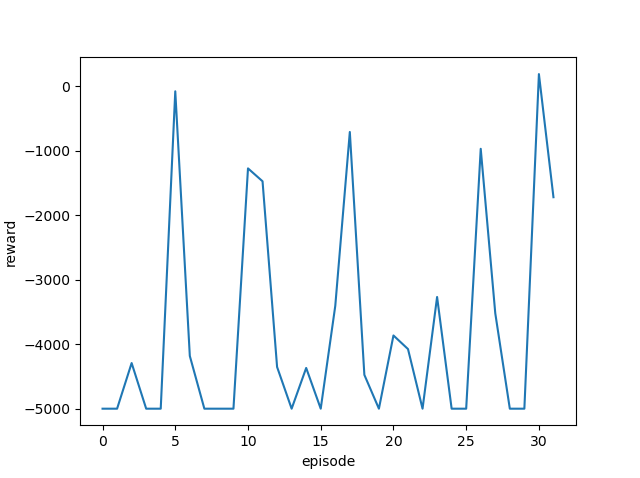 |
| 1.4 | 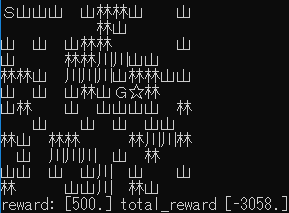 |
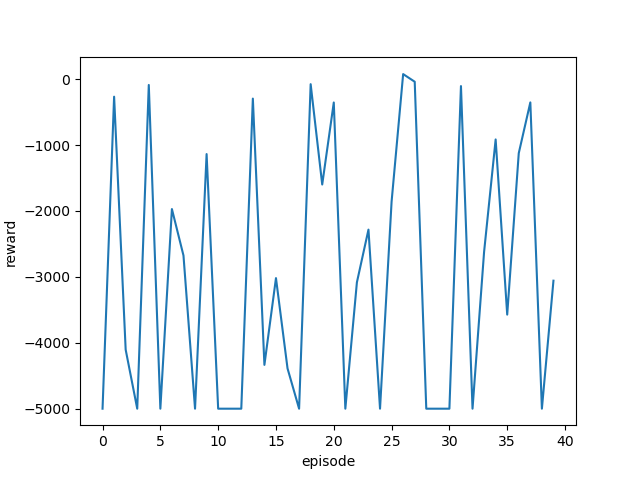 |
| 1.5 |  |
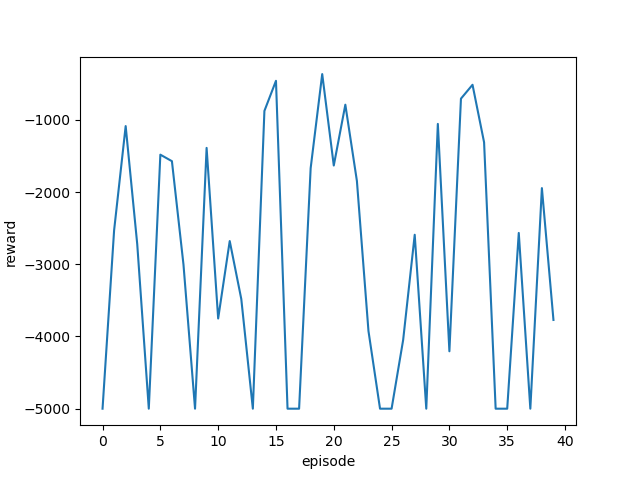 |
ゴール回数は増えているように見えますが、今回も攻略するまでには至りませんでした。
次回ももう少し学習率を調整を行ってみたいと思います。