前回は、これまでの改善点をまとめましたが、まだ学習アルゴリズムの変更を試していないことに気づきました。
[広くしたマップイメージ]
というわけで今回は別の学習アルゴリズムを試してみます。
学習アルゴリズム変更
いままでは学習アルゴリズムとしてACKTRを使っていましたがPPO2に変更します。
修正箇所は12-13行目と26-30行目となります。
[ソース]
1 | # 警告を非表示 |
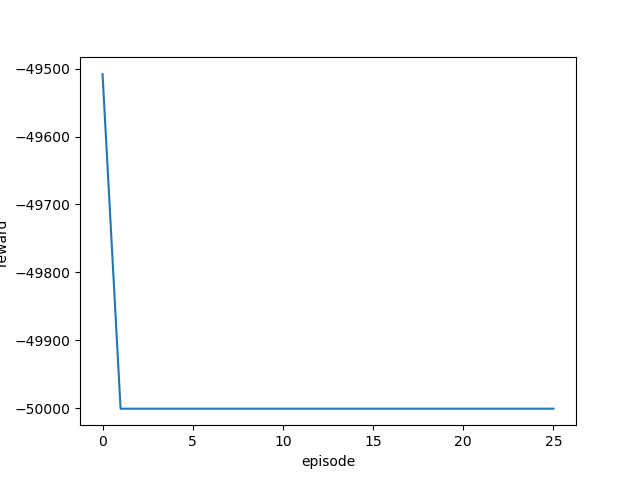
学習率を変更しながら実行し、それぞれの最終結果と平均報酬遷移(グラフ)を確認します。
[結果]
| 学習率 | 最終位置・最終報酬 | 平均報酬遷移 |
|---|---|---|
| 0.01 |  |
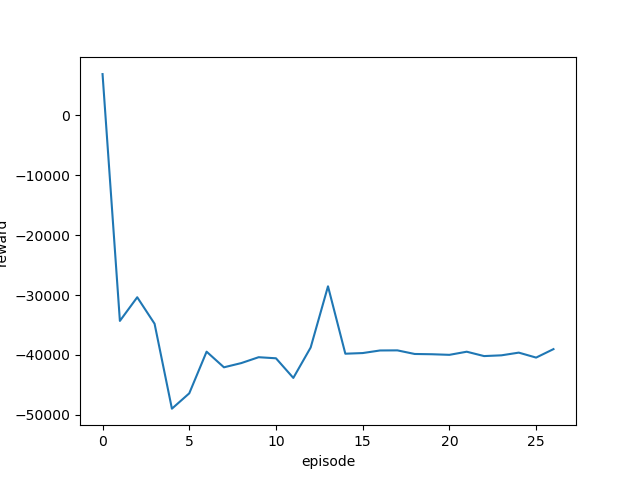 |
| 0.05 | 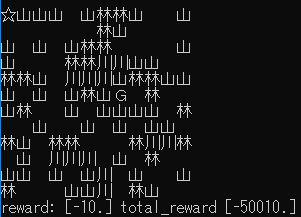 |
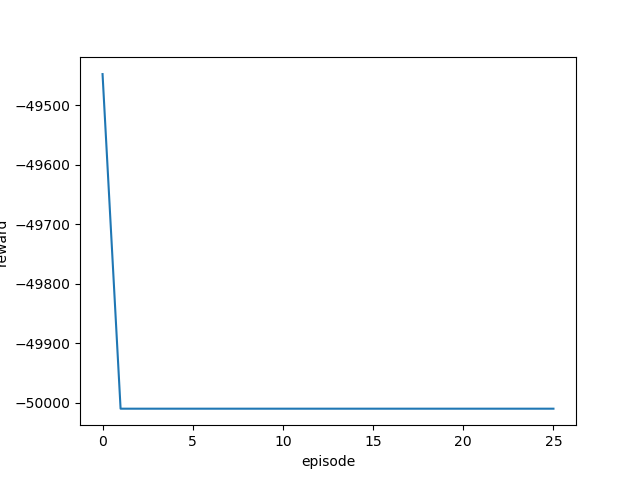 |
| 0.1 |  |
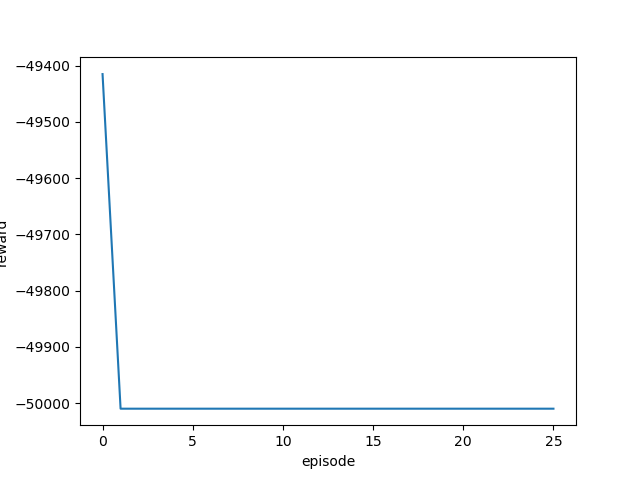 |
| 0.5 |  |
 |
| 1.0 |  |
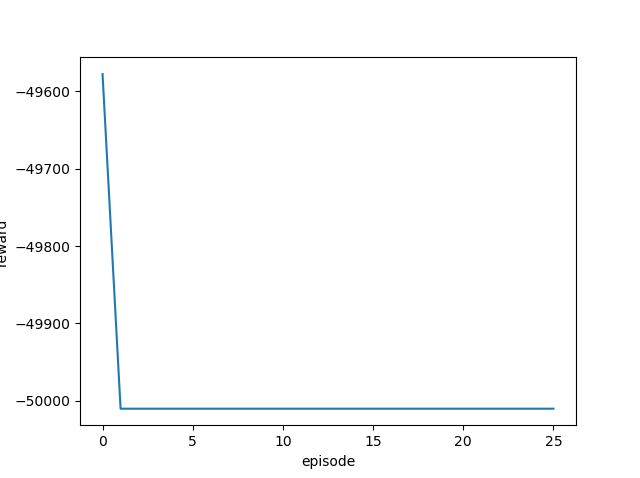 |
ほとんどゴール地点から動かず、全くゴールまでたどり着いていません。
このカスタム環境にはPPO2アルゴリズムは向いていないようです。
一旦学習アルゴリズムはACKTRに戻して、次回は別の改善を行いたいと思います。