Tominaga 方程式
Tominaga 方程式は次のように定義される非線形微分方程式です:
$$
\frac{d^2 y}{dt^2} + \frac{dy}{dt} + y^3 = \cos(t)
$$
この方程式を数値的に解くために、Python を使用してグラフ化する方法を示します。
まずは、必要なライブラリをインポートします。
1 | import numpy as np |
次に、Tominaga 方程式の微分方程式を定義します。
1 | def tominaga_equation(t, y): |
ここで tominaga_equation 関数は、Tominaga 方程式を表しています。
この関数は、現在の時刻$ ( t ) $と状態$ ( y ) $を引数として受け取り、微分方程式の右辺の値を計算して返します。
具体的には、$ ( y[0] ) $は$ ( y ) $の値を表し、$ ( y[1] ) $は$ ( \frac{dy}{dt} ) $の値を表します。
次に、微分方程式を数値的に解きます。
ここでは solve_ivp 関数を使用して、初期条件から微分方程式を解きます。
1 | # 初期条件 |
このコードでは、solve_ivp 関数を使用して** Tominaga 方程式を数値的に解きます。
初期条件 y0 は [0.0, 0.0] と設定されており、初期位置と初速度を表します。t_span は解く時間の範囲**を表しています。
解が得られた後は、解の時間変化に対する y(t) と y'(t)(速度)の値をプロットしています。
これにより、Tominaga 方程式の解の振る舞いや特性をグラフ上で視覚化することができます。
このコードを実行すると、Tominaga 方程式の解の時間変化が示されたグラフが表示されます。
解の振動や周期性などの特性を観察することができます。
[実行結果]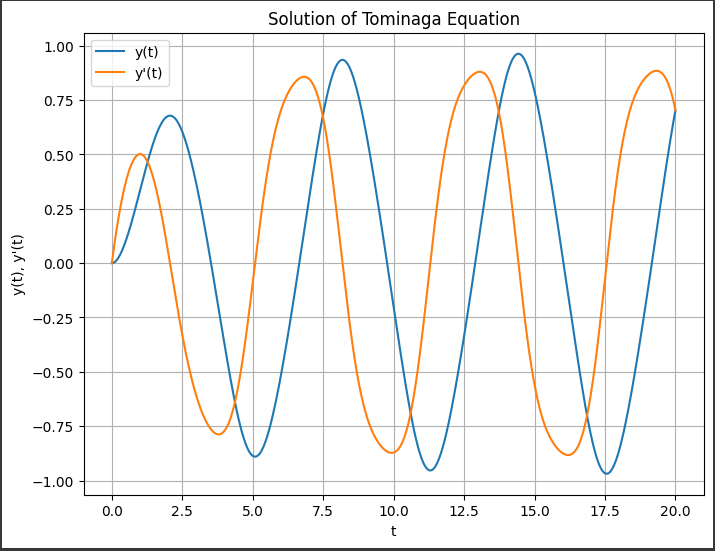
ソースコード解説
ソースコードの各部分を詳しく説明します。
1. ライブラリのインポート
1 | import numpy as np |
numpyライブラリは数値計算用の基本的な機能を提供します。matplotlib.pyplotライブラリはグラフ描画用の機能を提供します。scipy.integrate.solve_ivp関数は微分方程式を数値的に解くための機能を提供します。
2. Tominaga 方程式の定義
1 | def tominaga_equation(t, y): |
tominaga_equation関数は、Tominaga 方程式を定義します。- 引数
tは現在の時間を表し、yは状態ベクトル[y, dy/dt]を表します。 - 関数内では、
y[1]をdy/dtとして定義し、np.cos(t) - y[1] - y[0]**3をd^2y/dt^2として定義しています。 - 関数は、
[dy/dt, d^2y/dt^2]をリストとして返します。
3. 初期条件の設定
1 | y0 = [0.0, 0.0] # 初期位置と初速度 |
y0は Tominaga 方程式の初期条件を設定します。
ここでは初期位置を0.0、初速度を0.0としています。
4. 解く時間の範囲の設定
1 | t_span = [0, 20] # 0から20までの時間範囲 |
t_spanは解く時間の範囲を指定します。
ここでは0から20までの時間範囲を指定しています。
5. 数値的に微分方程式を解く
1 | sol = solve_ivp(tominaga_equation, t_span, y0, t_eval=np.linspace(t_span[0], t_span[1], 1000)) |
solve_ivp関数を使用して、tominaga_equation関数で定義された微分方程式を数値的に解きます。tominaga_equationは微分方程式を表す関数です。t_spanは解く時間の範囲を指定します。y0は初期条件を指定します。t_eval=np.linspace(t_span[0], t_span[1], 1000)は、解を評価する時間点を指定します。
ここでは時間範囲を$1000$個の等間隔で分割して解を評価します。
6. 結果のプロット
1 | plt.figure(figsize=(8, 6)) |
plt.figure(figsize=(8, 6))は図のサイズを指定します。plt.plot(sol.t, sol.y[0], label='y(t)')とplt.plot(sol.t, sol.y[1], label="y'(t)")で、解solの時間変化をグラフ化します。sol.tは時間、sol.y[0]は位置y(t)、sol.y[1]は速度y'(t)を表します。plt.xlabel('t')とplt.ylabel('y(t), y\'(t)')で軸ラベルを設定します。plt.title('Solution of Tominaga Equation')でグラフのタイトルを設定します。plt.legend()で凡例を表示します。plt.grid(True)でグリッドを表示します。plt.show()でグラフを表示します。
これにより、Tominaga 方程式の解 y(t) とその導関数 y'(t) の時間変化がグラフで可視化されます。
グラフから、解の振動や特性を観察することができます。
結果解説
[実行結果]
グラフを説明します。
1. 横軸 (t):
- 時間$ ( t ) $を表します。
この例では、$0$から$20$までの時間範囲を等間隔で分割した点が横軸上に表示されます。
2. 縦軸 (y(t), y’(t)):
- $ ( y(t) ) $と$ ( y’(t) ) $の値を表します。
- $ ( y(t) ) $は Tominaga 方程式の解であり、時間 $ ( t ) $に対する位置や変位を表します。
- $ ( y’(t) ) $は$ ( \frac{dy}{dt} ) $の値であり、時間 $ ( t ) $に対する速度を表します。
3. グラフの表示:
- グラフには、時間$ ( t ) $に対する$ ( y(t) ) $と$ ( y’(t) ) $の変化がプロットされます。
- $ ( y(t) ) $の曲線は Tominaga 方程式の解の時間変化を示し、振動や非線形な特性が視覚化されます。
- $ ( y’(t) ) $の曲線は$ ( y(t) ) $の時間変化に対する速度を示し、解の変化率や速度の振る舞いを表します。
4. タイトル:
- グラフの上部には「Solution of Tominaga Equation」というタイトルが表示されます。
これは、表示されている曲線が Tominaga 方程式の数値解を表していることを示します。
5. 凡例 (Legend):
- グラフには「y(t)」と「y’(t)」という凡例が表示されています。
- 「y(t)」は Tominaga 方程式の解$ ( y(t) ) $を表し、位置や変位の時間変化を示します。
- 「y’(t)」は Tominaga 方程式の解の導関数$ ( y’(t) ) $を表し、速度や変化率の時間変化を示します。
グラフを通じて、Tominaga 方程式の解の時間変化や振る舞いが視覚的に理解できます。
特に非線形な微分方程式の場合、解の振動や周期性、または解がどのように非線形項$ ( \cos(t) ) $によって影響を受けるかがグラフから読み取れます。
数値的な解法を用いた場合は、計算の精度や初期条件の影響を考慮する必要があります。
また、解の振動や安定性を観察するために、時間範囲や時間刻みの選択によって解の挙動が異なることもあります。