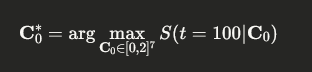
A Practical Guide
Energy minimization is a fundamental technique in computational biology for finding the most stable protein structure. In this blog post, I’ll walk you through a concrete example using Python, showing how to minimize potential energy to predict stable molecular conformations.
The Physics Behind It
The potential energy of a molecular system can be described by various force field terms. For simplicity, we’ll use a basic model that includes:
$$E_{total} = E_{bond} + E_{angle} + E_{torsion} + E_{vdw} + E_{elec}$$
For our example, we’ll focus on a simplified 2D model with:
$$E = \sum_{bonds} k_{bond}(r - r_0)^2 + \sum_{angles} k_{angle}(\theta - \theta_0)^2 + E_{LJ}$$
Where the Lennard-Jones potential is:
$$E_{LJ} = 4\epsilon \left[\left(\frac{\sigma}{r}\right)^{12} - \left(\frac{\sigma}{r}\right)^6\right]$$
Complete Python Implementation
1 | import numpy as np |
Detailed Code Explanation
Let me walk you through each component of this implementation:
1. SimplePeptide Class Structure
The SimplePeptide class encapsulates our molecular system with 5 atoms arranged in a chain. We initialize with random coordinates to simulate an unstable starting configuration.
1 | self.initial_coords = np.random.randn(n_atoms * 2) * 2.0 |
This creates a flattened array of coordinates that we’ll optimize.
2. Force Field Parameters
We define physical constants that govern molecular interactions:
- k_bond = 100.0: The spring constant for covalent bonds (higher = stiffer bonds)
- r0 = 1.5 Å: Equilibrium bond length (typical C-C bond distance)
- k_angle = 50.0: Resistance to angle deformation
- theta0 = 120°: Preferred bond angle (sp² hybridization)
- epsilon, sigma: Lennard-Jones parameters for van der Waals interactions
3. Bond Energy Calculation
1 | def bond_energy(self, coords): |
This implements a harmonic potential: $E_{bond} = \frac{1}{2}k_{bond}(r - r_0)^2$
The energy increases quadratically when bonds deviate from their equilibrium length. We iterate through consecutive atom pairs to sum all bond contributions.
4. Angle Energy Calculation
1 | def angle_energy(self, coords): |
This calculates the angle formed by three consecutive atoms using vector dot products. The angle between vectors is: $\theta = \arccos\left(\frac{\vec{v_1} \cdot \vec{v_2}}{|\vec{v_1}||\vec{v_2}|}\right)$
We use np.clip() to prevent numerical errors when the cosine value slightly exceeds [-1, 1] due to floating-point arithmetic.
5. Lennard-Jones Non-Bonded Interactions
1 | def lennard_jones_energy(self, coords): |
The Lennard-Jones potential models van der Waals forces between non-bonded atoms. The $r^{-12}$ term represents Pauli repulsion at short distances, while the $r^{-6}$ term represents attractive dispersion forces.
Note: We skip adjacent atoms (i + 2) since they’re already connected by bond terms.
6. Energy Minimization with L-BFGS-B
1 | result = minimize( |
We use the Limited-memory Broyden–Fletcher–Goldfarb–Shanno with Box constraints (L-BFGS-B) algorithm. This quasi-Newton method is ideal for:
- High-dimensional optimization problems
- Functions where computing the Hessian is expensive
- Smooth, differentiable objective functions
The algorithm approximates the inverse Hessian using gradient information, converging quickly to local minima.
Graph Visualization Breakdown
The code generates six informative plots:
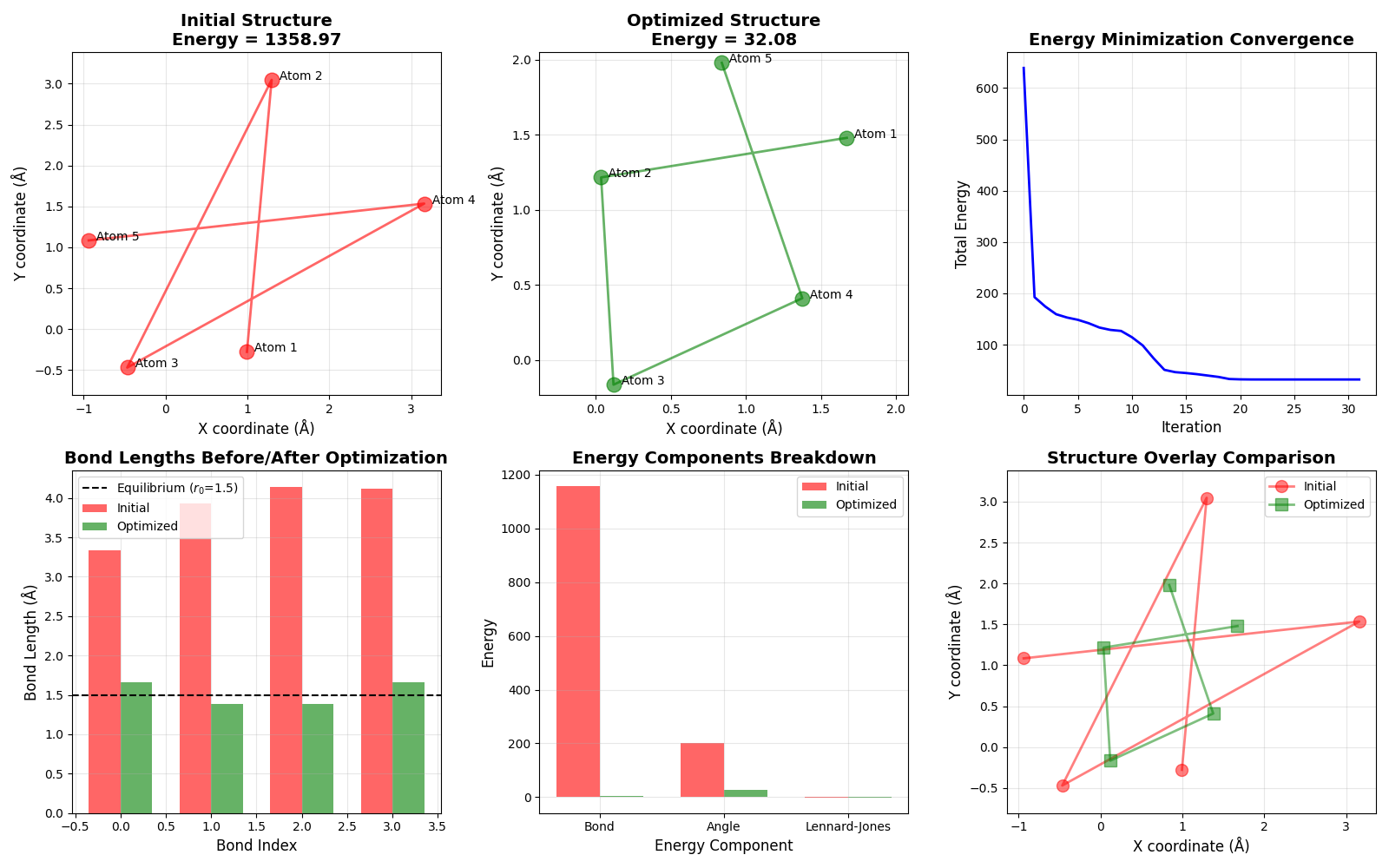
Plot 1 & 2: Initial vs Optimized Structures
These show the spatial arrangement of atoms before and after optimization. The red initial structure is typically distorted with irregular bond lengths and angles, while the green optimized structure shows regular geometry with bonds near 1.5 Å and angles near 120°.
Plot 3: Energy Convergence
This demonstrates how the total energy decreases over iterations. You’ll typically see:
- Rapid initial descent (steep gradient)
- Gradual convergence to a plateau (approaching minimum)
- Small fluctuations as the algorithm fine-tunes the solution
Plot 4: Bond Length Analysis
Compares bond lengths before/after optimization against the equilibrium value (black dashed line). Optimized bonds should cluster tightly around $r_0 = 1.5$ Å, showing the harmonic potential successfully restored proper geometry.
Plot 5: Energy Components
Breaks down the total energy into:
- Bond energy: Should decrease significantly as stretched/compressed bonds relax
- Angle energy: Reduces as angles approach 120°
- Lennard-Jones energy: May be slightly negative (attractive) at equilibrium distances
Plot 6: Overlay Comparison
Superimposes both structures, making it easy to see how each atom moved during optimization. Large displacements indicate the initial structure was far from the energy minimum.
Physical Interpretation
The optimization process mimics what happens in real molecular systems:
- Atoms start in a high-energy, unstable configuration (random initial positions)
- Forces act on each atom, derived from $\vec{F} = -\nabla E$
- The system evolves toward lower energy (the optimizer follows the negative gradient)
- Equilibrium is reached when forces balance and energy is minimized
The final structure represents a local energy minimum—a stable conformation where all bonded and non-bonded interactions are optimized. In real protein folding, this same principle guides polypeptide chains toward their native three-dimensional structures.
Key Takeaways
- Energy minimization finds stable molecular geometries by optimizing force field terms
- The L-BFGS-B algorithm efficiently navigates high-dimensional conformational space
- Visualizing energy components helps diagnose which interactions dominate stability
- This simplified 2D model captures the essential physics of protein structure prediction
Execution Results
Starting energy minimization...
Initial energy: 1358.9664
RUNNING THE L-BFGS-B CODE
* * *
Machine precision = 2.220D-16
N = 10 M = 10
This problem is unconstrained.
At X0 0 variables are exactly at the bounds
At iterate 0 f= 1.35897D+03 |proj g|= 4.90981D+02
At iterate 1 f= 6.39235D+02 |proj g|= 3.12680D+02
At iterate 2 f= 1.92579D+02 |proj g|= 3.65449D+02
At iterate 3 f= 1.74164D+02 |proj g|= 2.16437D+02
At iterate 4 f= 1.59238D+02 |proj g|= 8.80760D+01
At iterate 5 f= 1.52843D+02 |proj g|= 5.20852D+01
At iterate 6 f= 1.48401D+02 |proj g|= 4.80987D+01
At iterate 7 f= 1.41795D+02 |proj g|= 4.73184D+01
At iterate 8 f= 1.33288D+02 |proj g|= 8.08688D+01
At iterate 9 f= 1.28764D+02 |proj g|= 4.71395D+01
At iterate 10 f= 1.26686D+02 |proj g|= 4.73239D+01
At iterate 11 f= 1.14486D+02 |proj g|= 6.38045D+01
At iterate 12 f= 9.83938D+01 |proj g|= 5.10901D+01
At iterate 13 f= 7.33950D+01 |proj g|= 4.24835D+01
At iterate 14 f= 5.08787D+01 |proj g|= 4.33738D+01
At iterate 15 f= 4.63719D+01 |proj g|= 4.67261D+01
At iterate 16 f= 4.46260D+01 |proj g|= 5.89970D+01
At iterate 17 f= 4.24503D+01 |proj g|= 3.65125D+01
At iterate 18 f= 3.97755D+01 |proj g|= 3.04667D+01
At iterate 19 f= 3.70653D+01 |proj g|= 4.91662D+01
At iterate 20 f= 3.29949D+01 |proj g|= 1.19267D+01
At iterate 21 f= 3.23380D+01 |proj g|= 7.14087D+00
At iterate 22 f= 3.21163D+01 |proj g|= 3.26940D+00
At iterate 23 f= 3.20893D+01 |proj g|= 1.26735D+00
At iterate 24 f= 3.20821D+01 |proj g|= 6.82171D-01
At iterate 25 f= 3.20799D+01 |proj g|= 5.40804D-01
At iterate 26 f= 3.20784D+01 |proj g|= 4.30894D-01
At iterate 27 f= 3.20771D+01 |proj g|= 4.19832D-01
At iterate 28 f= 3.20761D+01 |proj g|= 3.19419D-01
At iterate 29 f= 3.20756D+01 |proj g|= 1.40325D-02
At iterate 30 f= 3.20756D+01 |proj g|= 4.54818D-03
At iterate 31 f= 3.20756D+01 |proj g|= 7.83018D-04
At iterate 32 f= 3.20756D+01 |proj g|= 9.30811D-05
* * *
Tit = total number of iterations
Tnf = total number of function evaluations
Tnint = total number of segments explored during Cauchy searches
Skip = number of BFGS updates skipped
Nact = number of active bounds at final generalized Cauchy point
Projg = norm of the final projected gradient
F = final function value
* * *
N Tit Tnf Tnint Skip Nact Projg F
10 32 39 1 0 0 9.308D-05 3.208D+01
F = 32.075587336868509
CONVERGENCE: REL_REDUCTION_OF_F_<=_FACTR*EPSMCH
Final energy: 32.0756
Optimization success: True
Number of iterations: 32
============================================================
DETAILED ANALYSIS
============================================================
Initial Configuration:
Total Energy: 1358.9664
Bond Energy: 1157.3975
Angle Energy: 201.8768
Lennard-Jones Energy: -0.3079
Optimized Configuration:
Total Energy: 32.0756
Bond Energy: 3.8458
Angle Energy: 28.9224
Lennard-Jones Energy: -0.6926
Energy Reduction:
Total: 1326.8908 (97.64%)