ドロップアウトは層の中のニューロンのうちいくつかをランダムに無効にして学習を行い、パラメータが多く表現の高いネットワークの自由度を抑えることで、モデルの頑健性を高めます。
最適化
機械学習や深層学習において、「学習」とは予測の誤差を最小化・最適化することを意味します。
最適化とは、与えられた関数を最小または最大にするようなパラメータを見つけることです。
機械学習とは、予測の誤差を最小にするパラメータを見つけることと言い換えることもできます。
TensorFlowでは勾配法という手法を使って関数を最小化します。
深層強化学習
深層強化学習とは深層学習と強化学習の2つを組み合わせた方法です。
- 深層学習
答えのある問題を学習して分類する問題(画像認識や自動作文)などに用いられます。 - 強化学習
よい状態と悪い状態だけを決めておいてその過程を自動的に学習してよりよい動作を獲得する問題(ロボットのコントロールやゲームの操作)などに用いられます。
TensorBoard(3)
TesnorBoardはTesorFlowのデータを可視化するツールです。
学習状況をより詳細に観察することができるようになります。
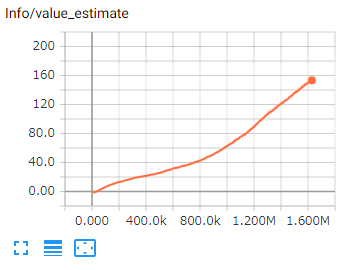
7.Value Estimates
予測する将来の報酬です。
学習成功時には増加し、継続して増加することが期待されます。
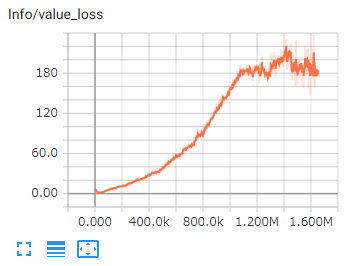
8.Value Loss
予測する将来の報酬と実際の報酬がどれだけ離れているかを示す値です。
報酬が安定したら、減少することが期待されます。
TensorBoard(2)
TesnorBoardはTesorFlowのデータを可視化するツールです。
学習状況をより詳細に観察することができるようになります。
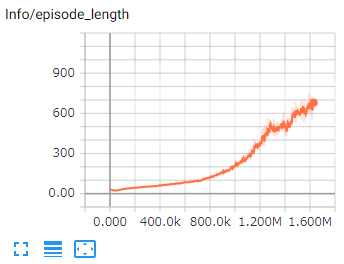
4.Episode Length
エピソードの平均の長さです。評価する環境によって望まれる結果は異なります。
ボールを落ちないようにする環境では、増加することが期待されます。
迷路を解くようなゲームでは、減少することが期待されます。
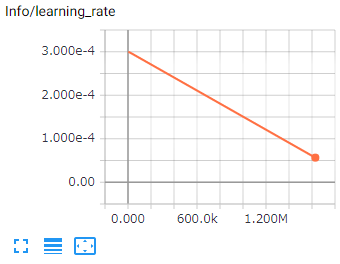
5.Learning Rate
学習率です。今回の行動評価を過去の行動評価と比べてどの程度信じるかという割合になります。
時間とともに継続して減少します。
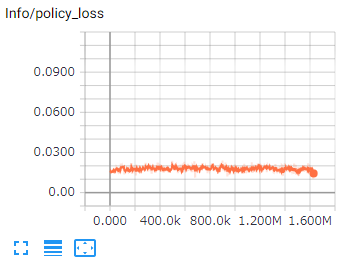
6.Policy Loss
Brainが行動を決定する「方策がどれだけ変化しているか」を示す値となります。
学習成功時には減少し、継続的に減少することが期待されます。
TensorBoard(1)
TesnorBoardはTesorFlowのデータを可視化するツールです。
学習状況をより詳細に観察することができるようになります。
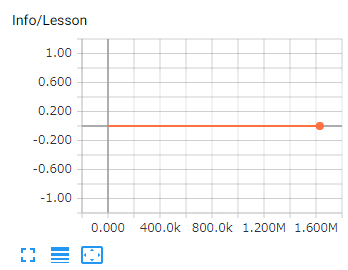
1.Lesson
カリキュラム学習のレッスンの進捗です。カリキュラム学習でない場合は、Lesson 0のままとなります。
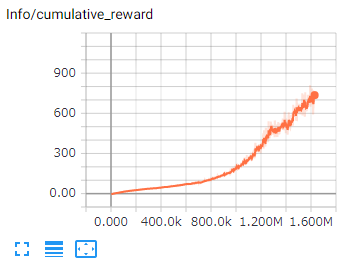
2.Cumulative Reward
エージェントの平均累積報酬です。継続して増加し、上下の振れ幅が小さいことが期待されます。
タスクの複雑さによってはなかなか増加しないこともあります。
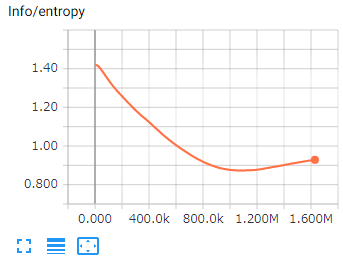
3.Entropy
Brainが決定する「Actionがどれだけランダムであるか」を示す値です。
継続的に減少することが期待されます。
Actionのデータ型が離散(Discrete)の場合、次のような対応が有効となります。
- エントロピーの減少が早すぎる。
→ ハイバーパラメータのbetaを増やす。 - エントロピーの減少が遅すぎる。
→ ハイバーパラメータのbetaを減らす。
Unity ML-AgentsのBrain
Agentが観測した状態に応じて、行動を決定するオブジェクトとなります。
1つのBrainで複数のAgentsの行動を決定することもできます。
Brainには下記の4種類があります。
1.External
外部の自作MLライブラリ(Tensorflowなど)を使用します。
学習時に設定されます。
2.Internal
プロジェクトに埋め込まれた推論モデルを使用します。
推論時に設定されます。
3.Player
プレイヤー(人間)の入力に従って行動します。
学習環境の動作確認時などに利用します。
4.Heuristic
ルールベース(プログラム)に従って行動します。
Unity ML-Agentsのプロセス
Unity ML-Agentsは、Unityで機械学習の学習環境を構築するためのフレームワークです。
Unity ML-Agentsでの2プロセスに関して説明します。
学習プロセス
学習用Pythonスクリプトが学習環境となるUnityで強化学習を行います。
学習結果は推論モデルとして保存されます。
推論プロセス
学習結果となる推論モデルをつかってUnityで動作します。
推論モデルは与えられたデータから推論結果を導き出すものです。
Intrinsic Curiosity Module(ICM)
Intrinsic Curiosity Module(ICM)
まだ見たことのない場面に対する好奇心を報酬として学習させる手法です。
ICMでは次の2つのモデルを同時に学習します。
- 逆モデル
2つの状態からその間に選択した行動を予測する。 - 順モデル
状態と選択した行動から次の状態を予測する。
この予測が外れるほど多くの報酬を与える。
これらによってエージェントにとって未知である行動を取るほど報酬を多く受け取ることになります。
迷路を探索してさまざまな行動をとる必要があるゲーム等に最適な学習方法です。