ニューラルネットワークで数値データの予測を行う推定モデルを作成します。
住宅情報から価格を予測します。
まずは必要なパッケージをインポートします。
1 | # パッケージのインポート |
データセットの準備を行います。
各データの内容は次の通りです。
| 変数名 | 内容 |
|---|---|
| train_data | 訓練データの配列 |
| train_labels | 訓練ラベルの配列 |
| test_data | テストデータの配列 |
| test_labels | テストラベルの配列 |
1 | # データセットの準備 |

データセットのシェイプを確認します。
1 | # データセットのシェイプの確認 |

訓練データと訓練ラベルは404件、テストデータとテストラベルは102件です。
データの13は住宅情報の種類数です。
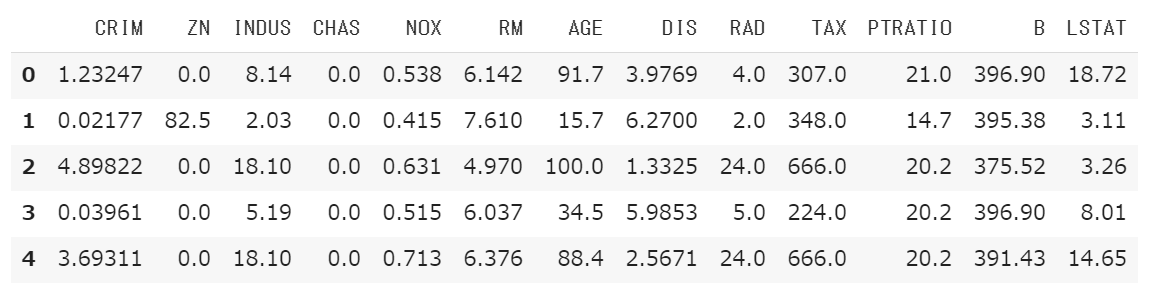
訓練データの先頭10件を表示します。
1 | # データセットのデータの確認 |
訓練ラベルの先頭10件を表示します。
1 | # データセットのラベルの確認 |
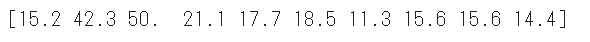
学習前の準備として、訓練データと訓練ラベルをシャッフルします。
似たデータを連続して学習すると偏りが生じてしまうのを防ぐためです。
1 | # データセットのシャッフルの前処理 |
訓練データとテストデータの正規化を行います。
データを一定の方法で変換し同じ単位で比較しやすくするためです。
具体的には平均0、分散1で正規化を行います。
1 | # データセットの正規化の前処理 |
データセットのデータが平均0、分散1になっていることを確認します。
1 | # データセットの前処理後のデータの確認 |

モデルを作成します。今回は全結合層を3つ重ねた簡単なモデルとなります。
1 | # モデルの作成 |
ニューラルネットワークモデルのコンパイルを行います。
- 損失関数 mse
平均二乗誤差 Mean Squared Error - 実際の値と予測値との誤差の二乗を平均したものです。
0に近いほど予測精度が高いことになります。 - 最適化関数 Adam
lrは学習率です。 - 評価指標 mae
平均絶対誤差 Mean Absolute Error - 実際の値と予測値との絶対値を平均したものです。
0に近いほど予測精度が高いことになります。
1 | # コンパイル |
EarlyStoppingの準備を行います。
任意のエポック数改善がないと学習を停止します。
1 | # EarlyStoppingの準備 |
学習を行います。callbacksにEarlyStoppingを指定しています。
1 | # 学習 |
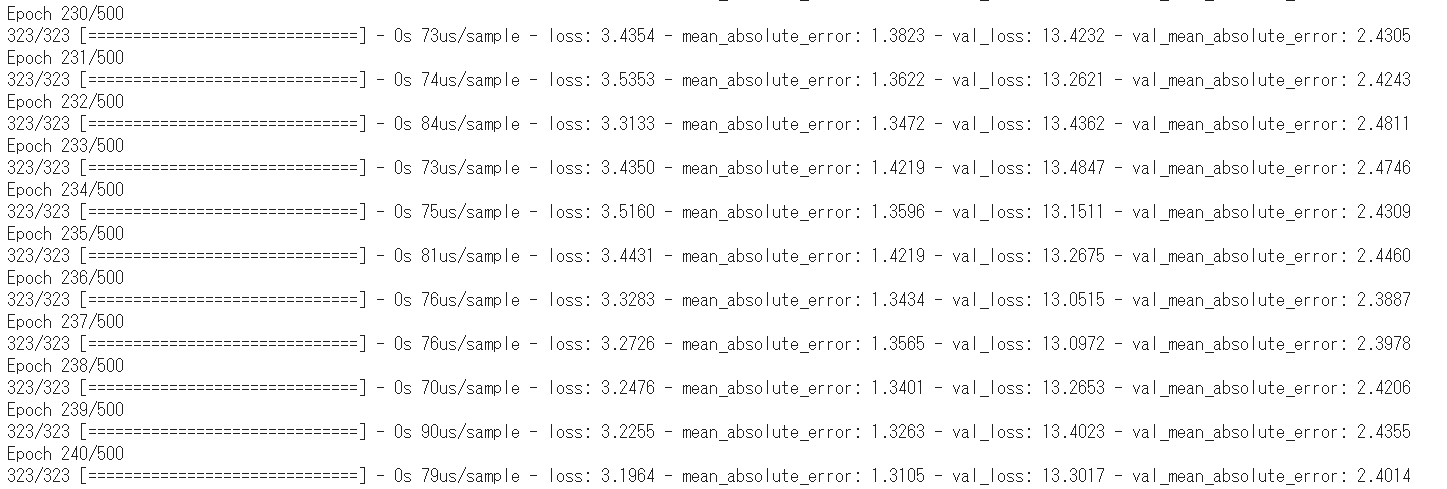
学習中に出力される情報の意味は次の通りです。
| 情報 | 説明 |
|---|---|
| loss | 訓練データの誤差です。0に近いほどよい結果となります。 |
| mean_absolute_error | 訓練データの平均絶対誤差です。0に近いほどよい結果となります。 |
| val_loss | 検証データの誤差です。0に近いほどよい結果となります。 |
| val_mean_absolute_error | 検証データの平均絶対誤差です。0に近いほどよい結果となります。 |
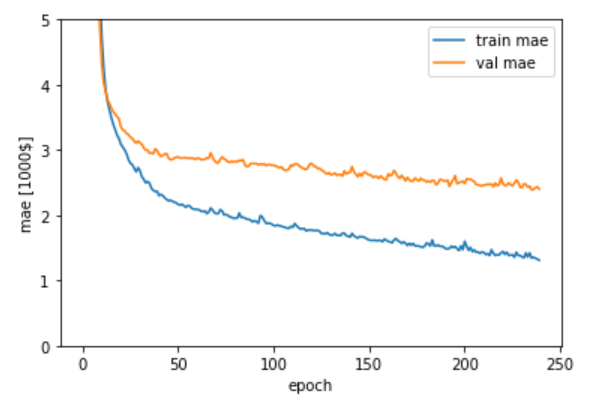
上記のデータうち、訓練データの平均絶対誤差(mae)と検証データの平均絶対誤差(val_mae)をグラフ表示します。
1 | # グラフの表示 |
テストデータとテストラベルを推定モデルに渡して評価を行い、平均絶対誤差を算出します。
1 | # 評価 |

平均絶対誤差は2.655となりました。
テストデータの先頭10件の推論を行い、予測結果を出力します。
1 | # 推論する値段の表示 |

実際の価格に近い価格が推論されているような気がします。
(Google Colaboratoryで動作確認しています。)
参考
AlphaZero 深層学習・強化学習・探索 人工知能プログラミング実践入門 サポートページ
深層学習 ニューラルネットワークで分類
手書き数字を分類するためにニューラルネットワークを作成し、実際の数字を推論するモデルを作ります。
まずは必要なパッケージをインポートします。
1 | # パッケージのインポート |
データセットの準備を行います。
各データの内容は次の通りです。
| 変数名 | 内容 |
|---|---|
| train_images | 訓練画像の配列 |
| train_labels | 訓練ラベルの配列 |
| test_images | テスト画像の配列 |
| test_labels | テストラベルの配列 |
1 | # データセットの準備 |

データセットのシェイプを確認します。
1 | # データセットのシェイプの確認 |

訓練画像データは60000×画像サイズ(28×28)です。
訓練ラベルデータは60000の1次元配列となります。
データセットの画像を確認するために先頭の10件を表示します。
1 | # データセットの画像の確認 |

データセットのラベルを確認するために先頭の10件を表示します。
1 | # データセットのラベルの確認 |
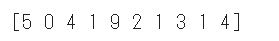
学習を開始する事前準備として、データセットをニューラルネットワークに適した形に変換します。
具体的には、画像データを28×28の2次元配列から1次元配列(786)に変換します。
1 | # データセットの画像の前処理 |

ラベルデータに関しても、ニューラルネットワークに適した形に変換します。
具体的にはone-hot表現に変えます。
one-hot表現とは、ある1要素が1でほかの要素が0である配列です。
ラベルが8の場合は[0, 0, 0, 0, 0, 0, 0, 0, 1, 0]という配列になります。
1 | # データセットのラベルの前処理 |

ニューラルネットワークのモデルを作成します。
入力層のシェイプは画像データに合わせて786で、出力層はラベルデータに合わせて10とします。
ユニット数と隠れ層の数は自由に決められますが今回はユニット数256と隠れ層128としました。
層とユニット数を増やすと複雑な特徴をとらえることができるようになる半面、学習時間が多くかかるようになってしまいます。
またユニット数が多くなると重要性の低い特徴を抽出して過学習になってしまう可能性があります。
Dropoutは過学習を防いでモデルの精度をあげるための手法となります。
任意の層のユニットをランダムに無効にして特定ニューロンへの依存を防ぎ汎化性能を上げます。
活性化関数は結合層の後に適用する関数で層からの出力に対して特定の関数を経由し最終的な出力値を決めます。活性化関数を使用することで線形分離不可能なデータも分類することができるようになります。
1 | # モデルの作成 |
ニューラルネットワークのモデルをコンパイルします。
- 損失関数 [loss]
モデルの予測値と正解データの誤差を計算する関数です。 - 最適化関数 [optimizer]
損失関数の結果が0に近づくように重みパラメータとバイアスを最適化する関数です。 - 評価指標 [metrics]
モデル性能を測定するための指標です。測定結果は、学習を行うfit()の戻り値に格納されます。
1 | # コンパイル |
訓練画像と訓練モデルを使って学習を実行します。
1 | # 学習 |

学習中に出力される情報の意味は次の通りです。
| 情報 | 説明 |
|---|---|
| loss | 訓練データの誤差です。0に近いほどよい結果となります。 |
| acc | 訓練データの正解率です。1に近いほどよい結果となります。 |
| val_loss | 検証データの誤差です。0に近いほどよい結果となります。 |
| val_acc | 検証データの正解率です。1に近いほどよい結果となります。 |
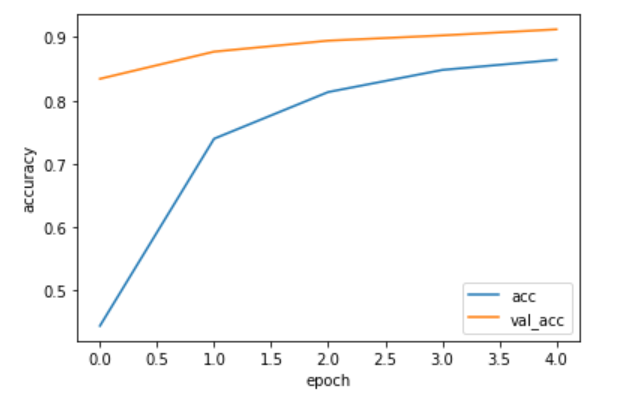
上記のデータうち、訓練データの正解率(acc)と検証データの正解率(val_acc)をグラフ表示します。
1 | # グラフの表示 |
テスト画像とテストラベルをモデルに渡して評価を行います。
1 | # 評価 |

正解率は91.0%となりました。
先頭10件のテスト画像の推論を行い、画像データと予測結果を合わせて表示します。
1 | # 推論する画像の表示 |
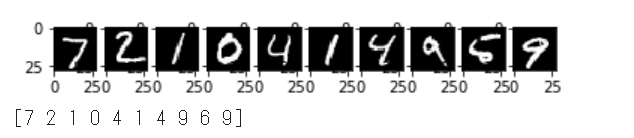
90%の正解率であることが確認できます。
(Google Colaboratoryで動作確認しています。)
参考
AlphaZero 深層学習・強化学習・探索 人工知能プログラミング実践入門 サポートページ
逆強化学習
逆強化学習では報酬関数を推定します。そのメリットは次の通りです。
- 人が報酬を設定する必要がない。
- 他タスクでの利用が可能になる。
- 人間や動物の行動理解に利用できる。
逆強化学習の手順は以下のようになります。
- エキスパートの行動を評価する。(戦略、状態遷移等)
- 報酬関数の初期化を行う。
- 報酬関数を利用し戦略を学習する。
- 学習した戦略の評価が、エキスパートの評価結果(手順1)と近くなるよう報酬関数を更新する。
- 手順3に戻り処理を繰り返す。
逆強化学習のデメリットとしては学習に時間がかかるということです。
通常の強化学習手順である手順3だけでも時間がかかるところを、逆強化学習ではその手順3を繰り返し行う必要があるためです。
強化学習の弱点
強化学習にはいくつか弱点があります。
弱点① サンプル効率が悪い。
DNNでの強化学習は、入力が画像であればいろいろな課題に対応できるという大きなメリットがあります。どのようなゲームであっても行動の数を調整するだけで同じネットワークで解くことができます。
ただし学習には大量のサンプルを用意する必要があり時間がかかります。
対策の1つとして何度もプレイ可能なシミュレーターを用意するという手がありますが、シミュレータの用意も相応の時間がかかるため深層強化学習の適用は難しいのが現状です。
OpenAI Gymのようなすでに用意されているシミュレータを使うのが近道となります。
弱点② 局所的な行動に陥る・過学習することが多い
大量のサンプルを学習したとしても、最適な行動を獲得できるとは限りません。
失敗する行動パターンは次の2種類です。
- 局所最適な行動
報酬は獲得できているものの最適とは言えない行動です。
そこそこいい成績であればそれ以上頑張らないようなイメージです。 - 過学習
ある環境に特化した行動を獲得してしまうことです。
試験で問題を理解するのではなく答えを覚えてしまうようなイメージです。
弱点③ 再現性が低い。
同じアルゴリズムを同じパラメータで学習したとしても獲得報酬が異なることが多々あります。
これはフレームワークのデフォルト値が影響するためです。
☆弱点を克服するための対策
対応策は次の3点が挙げられます。
- テスト可能なモジュールに切り分ける。
各モジュールごとにテストを行うことで全体テストの前に処理をブラッシュアップします。
あるいはエージェントを複数用意して、エージェントを切り替えて効率的な学習を目指します。 - 可能な限りログをとる。
一度の実験からなるべく多くの情報を得るためです。 - 学習を自動化する。
学習の実行をスクリプト化し、設定パラメータや実行結果の明確化を目指します。
できるだけ事前に動作確認を行ったうえで実験を行い、可能な限り取得した動作ログからベストの対策を検討・実装したうえで何度もテストを行い、このプロセスを繰り返すことで強化学習の弱点を克服していきます。
強化学習の概要
強化学習では、「エージェント」がある「環境」の中で「行動」し、その行動から得られる「報酬」が最大化するような「推論モデル」を作成します。
推論モデルがあれば学習した状態で「環境」の中を「行動」することができます。
強化学習のサイクルを簡単にまとめると下記のようになります。
- エージェントが環境に対して行動を起こします。
- 環境が状態の更新と行動の評価を行います。
- 状態と報酬をエージェントに知らせます。
強化学習のポイントとなる用語を下記にまとめます。
| 用語 | 説明 |
|---|---|
| エージェント - Agent | 環境のなかでいろいろと行動し学習を行います。さまざまな試行を行い状態ごとに行動を最適化していきます。 |
| 環境 - Environment | 行動に対して、状態の更新と行動の評価を行います。 |
| 行動 - Action | エージェントがいろいろな状態で起こすことができる行動です。 |
| 状態 - State | 環境の状態です。行動によって変化します。 |
| 報酬 - Reward | 行動すると得られる報酬です。いい結果のときは正の報酬が得られ、悪い結果のときには負の報酬となります。 |
深層強化学習 ブロック崩し(breakout)をA2Cで攻略 -プレイ編-
前回学習したデータを使ってブロック崩し(breakout)をプレイします。
まず必要なパッケージをインポートします。
1 | # パッケージのimport |
動画ファイルを保存する関数を定義します。
1 | # 動画の描画関数の宣言 |
実行環境を設定します。
おさらいとなりますがブロック崩し(breakout)の学習には4つの工夫をします。
- No-Operation
実行環境をリセットするときに0~30ステップのいずれかの間何もしない行動を実施します。
=> ゲーム開始の初期状態を様々にし、特定の開始情報に特化しないようにするためです。 - Episodic Life
5機ライフがありますが、1回失敗したときにゲーム終了とします。
ただし崩したブロックはそのままの状態で次の試行を開始するようにします。
=> 多様な状態に対して学習ができるようにするためです。 - Max and Skip
4フレームごとに行動を判断させ、4フレーム連続で同じ行動をするようにします。
=> 60Hzでゲームが進行すると早すぎるためエージェントの行動を15Hzにするためです。 - Warp frame
縦210ピクセル、横160ピクセルのRGB値を縦横84ピクセルずつのグレースケール画像へと変換します。
=> 学習しやすくするためです。
また上記の4工夫とPyTorch環境に合わせるためのクラスWrapPyTorchを定義します。
1 | # 実行環境の設定 |
再生用の実行環境を実装します。
- EpisodicLifeEnvPlay 関数で1度でも失敗したらブロックの状態を最初から完全になり直します。
- MaxAndSkipEnvPlay クラスで4フレーム目だけを画像として出力します。
- make_env_play 関数で実行環境を生成します。
1 | # 再生用の実行環境 |
定数を設定します。
1 | # 定数の設定 |
A2Cの損失関数の計算をするための定数を設定します。
1 | # A2Cの損失関数の計算のための定数設定 |
GPU使用の設定を行います。(GPUがなくても実行できます。)
1 | # GPUの使用の設定 |
メモリオブジェクトの定義を行います。
1 | # メモリオブジェクトの定義 |
A2Cのディープ・ニューラルネットワークの構築を行います。
1 | # A2Cのディープ・ニューラルネットワークの構築 |
エージェントが持つ頭脳となるクラスを定義します。
このクラスは全エージェントで共有されます。
前回の「学習編」で作成した学習データ weight_end.pth を使います。
1 | # エージェントが持つ頭脳となるクラスを定義、全エージェントで共有する |
Breakoutを実行する環境のクラスを定義します。
1 | # Breakoutを実行する環境のクラス |
実行します。
1 | # 実行 |
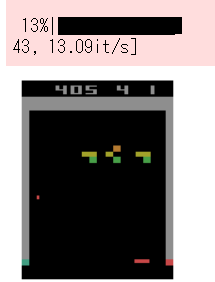
出力される動画ファイル 7breakout_play.mp4 は下記のようになります。
うまく壁の端からブロックを消して裏側に通したくさんのブロックを崩しています。
画面上部の方のブロックを消した方が高得点なので、報酬を-1から1にクリッピングしない方が裏側に通すように学習しやすくなります。
参考 > つくりながら学ぶ!深層強化学習 サポートページ
深層強化学習 ブロック崩し(breakout)をA2Cで攻略 -学習編-
ブロック崩し(breakout)を強化学習A2Cで攻略していきます。
まずOpenAI Gymの環境を並列で動かすために必要なパッケージをインストールします。
1 | pip install tqdm |
使用するパッケージをインポートします。
1 | # パッケージのimport |
ブロック崩し(breakout)の学習には4つの工夫をします。
- No-Operation
実行環境をリセットするときに0~30ステップのいずれかの間何もしない行動を実施します。
=> ゲーム開始の初期状態を様々にし、特定の開始情報に特化しないようにするためです。 - Episodic Life
5機ライフがありますが、1回失敗したときにゲーム終了とします。
ただし崩したブロックはそのままの状態で次の試行を開始するようにします。
=> 多様な状態に対して学習ができるようにするためです。 - Max and Skip
4フレームごとに行動を判断させ、4フレーム連続で同じ行動をするようにします。
=> 60Hzでゲームが進行すると早すぎるためエージェントの行動を15Hzにするためです。 - Warp frame
縦210ピクセル、横160ピクセルのRGB値を縦横84ピクセルずつのグレースケール画像へと変換します。
=> 学習しやすくするためです。
また上記の4工夫とPyTorch環境に合わせるためのクラスWrapPyTorchを定義します。
1 | # 実行環境の設定 |
マルチプロセルでBreakoutを並列実行する環境を生成する関数make_envを定義します。
OpenAIが用意しているマルチプロセス環境であるクラスSubprocVecEnvを使用します。
1 | # 実行環境生成関数の定義 |
定数を設定します。
Breakout-v0ですとフレームが自動的に2~4のランダムにskipされるため、今回はフレームスキップはさせないBreakoutNoFrameskip-v4を使用します。
1 | # 定数の設定 |
GPU使用の設定を行います。
GPU環境があれば cuda が出力されますが、そうでない場合は cpu が出力されます。
1 | # GPUの使用の設定 |
Advantage学習するためのメモリクラスを定義します。
.to(device)を使用して、GPU環境がある場合には自動的にGPUを使えるようにしています。
PyTorchではCPU環境とGPU環境を意識せずに同じプログラムをどちらの環境でも実行できるのが便利です。
1 | # メモリオブジェクトの定義 |
A2Cのディープ・ニューラルネットワークの構築を実装します。
コンボリューション層の定義のNUM_STACK_FRAME(=4)は、過去4フレーム分の画像を使って1つの状態として扱いニューラルネットワーク入力とすることを意味します。
1つのフレームではボールの位置しか分かりませんが、2フレームあれば速度が分かり、3フレームあれば加速度が分かるようになります。
今回はDQNのNature論文に合わせて4フレームとしています。
1 | # A2Cのディープ・ニューラルネットワークの構築 |
Brainクラスを定義します。
勾配降下法にはRMSpropを使用します。
1 | # エージェントが持つ頭脳となるクラスを定義、全エージェントで共有する |
実行環境のクラス Environment を定義します。
- 入力データは画像となります。4フレームで1つの状態を表します。
- マルチプロセル環境 SuvprocVecEnv を使用しているのでエージェントごとのforループ処理は必要ありません。
- 実行ループ100回ごとに得点を出力します。この出力で学習状態を確認します。
- 定期的に結合パラメータを保存します。
1 | # Breakoutを実行する環境のクラス |
最後に実行します。
1 | # 実行 |
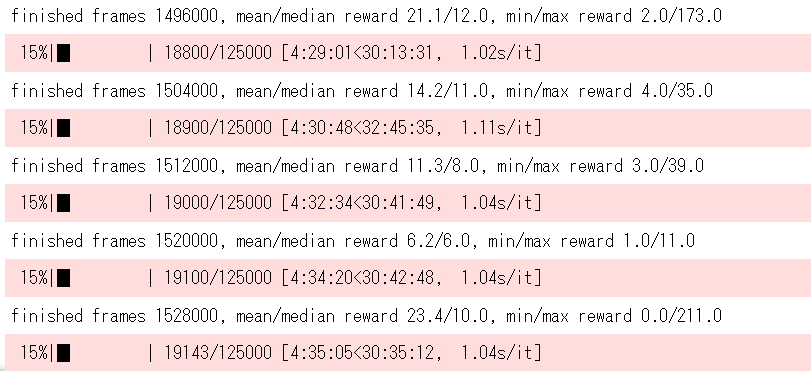
学習が完了すると学習データ weight_end.pth ファイルが出力されます。
次回はこの学習データを使ってBreakoutをプレイします。
参考 > つくりながら学ぶ!深層強化学習 サポートページ
深層強化学習 ブロック崩し(breakout)をランダム操作
OpenAI Gym に用意されている環境の1つブロック崩し(breakout)を実行してみます。
まずbreakout-v0を実行するために、次のコマンドを実行します。
1 | pip install --no-index -f https://github.com/Kojoley/atari-py/releases atari_py |
使用するパッケージをインポートします。
1 | # パッケージのimport |
ブロック崩し(Breakout-v0)を指定して環境を作成します。
1 | # ゲームの開始 |
ゲームの状態と行動を把握するためのコードを実行します。
1 | # ゲームの状態と行動を把握 |

- 状態 env.observation_space は縦210ピクセル、横160のRGB情報です。
CartPoleのような物理情報ではなく画面そのものが状態となっているのがポイントです。 - 行動 env.unwrapped.get_action_meanings() は次の4種類となります。
- NOOP : 何もしない
- FIRE : 玉を発射
- RIGHT : 右へ移動
- LEFT : 左へ移動
試しに初期状態の画面を表示してみます。
1 | # 初期状態を描画してみる |
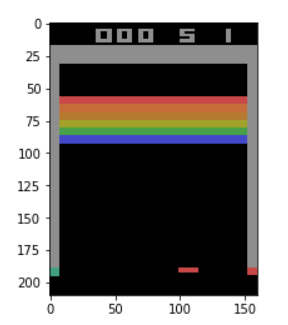
画面上部に表示される数字の意味は下記の通りです。
- 左の数字 : 得点
- 中央の数字 : ライフ(残機)
- 右の数字 : プレイヤー数/チーム数(今回は無視)
動画ファイルを保存する関数を定義します。
1 | # 動画の描画関数の宣言 |
ランダムに行動し、その様子を動画ファイルで保存します。
1 | frames = [] # 画像を格納していく変数 |
出力される動画ファイル 7_1breakout.mp4 は下記のようになります。
以上で、ブロック崩し(Breakout)をランダムに動かすことができました。
次回はこの環境に強化学習を適用します。
参考 > つくりながら学ぶ!深層強化学習 サポートページ
深層強化学習 A2C
A2Cという深層強化学習を実装します。
A2Cではエージェントを複数用意して強化学習を行います。
A2Cは「Advantage学習」と「Actor-Critic」を意味します。
- Advantage学習は2ステップ以上先まで動かしてQ関数を更新します。
- Actor-Criticは方策反復法と価値反復法の両方を使用します。
使用するパッケージをインポートします。
1 | # パッケージのimport |
定数を定義します。
今回はエージェントを16個用意し、Advantageするステップ数を5とします。
1 | # 定数の設定 |
A2Cの損失関数の計算のための定数を設定します。
1 | # A2Cの損失関数の計算のための定数設定 |
Advantage学習用にメモリクラスを準備します。
- marks は試行の終端を表します。
- 関数 insert は現在の transition を RolloutStorage に追加します。
- 関数 after_update は Advantage する5ステップが終了したら一番最新(後ろ)の内容を先頭に格納します。
- 関数 compute_returns は各ステップでの割引報酬和を計算します。
1 | # メモリクラスの定義 |
A2Cのディープ・ニューラルネットワークの構築するクラスを実装します。
fc層を2つ用意し、Actor側とCritic側の出力を用意します。
- 関数 act は状態xから行動を確率的に求めます。
- 関数 get_value は状態xでの状態価値を求めます。
- 関数 evaluate_actions はネットワークを更新します。
状態xでの状態価値および実際に行った行動actionsを利用して、行動のlog確率action_log_probsと方策のエントロピーを計算します。
1 | # A2Cのディープ・ニューラルネットワークの構築 |
エージェントが持つ頭脳となるBrainクラスを定義します。
このクラスのオブジェクトは全エージェントで共有されます。
1 | # エージェントが持つ頭脳となるクラスを定義、全エージェントで共有する |
実行する環境のクラスを実装します。
このクラスでエージェントを複数生成し Advantage学習による報酬の計算を行います。
- 関数 run でAdvantageする5ステップ分ずつ各環境を実行します。
この5ステップ全てのtransitionに対してそれぞれ1~5ステップのAdvantage学習を実施します。
1 | # 実行する環境のクラスです |
学習を実行します。
1 | # main学習 |
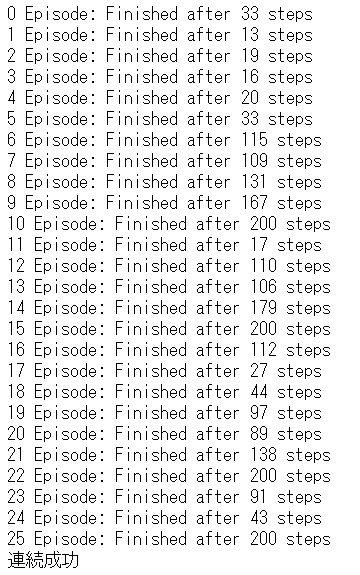
25エピソードで学習が完了しました。
参考 > つくりながら学ぶ!深層強化学習 サポートページ
深層強化学習 Prioritized Experience Replay
Prioritized Experience Replayという深層強化学習を実装します。
- Prioritized Experience Replayは、学習がきちんと進んでいない状態に対して優先的に学習させる深層強化学習です。
- 具体的には誤差が大きいtransitionを優先的にExperience Replay時に学習させ、価値関数のニューラルネットワークの出力誤差が小さくなるようにします。
使用するパッケージをインポートします。
1 | # パッケージのimport |
動画ファイルを保存する関数を定義します。
1 | # 動画の描画関数の宣言 |
経験(Transition)を表すnamedtupleを生成します。
(状態 state、行動 action、次の状態 next_state、報酬 rewardに容易にアクセスできます。)
1 | # namedtupleを生成 |
定数を宣言します。
1 | # 定数の設定 |
経験を保存するメモリクラスを定義します。
- 経験を保存する関数 push、ランダムに経験を取り出す関数 sampleがあります。
1 | # 経験を保存するメモリクラスを定義します |
TD誤差を格納するメモリクラスを定義します。
- 関数 get_prioritized_indexes はメモリ格納されている誤差の大きさに応じて確率的にindexを求める関数です。
- 関数 update_td_erro はメモリに格納されている誤差を更新するための関数です。
1 | # TD誤差を格納するメモリクラスを定義します |
ニューラルネットワークを構築するクラスを定義します。
1 | # ディープ・ニューラルネットワークの構築 |
Brainクラスを実装します。
(このクラスがニューラルネットワークを保持します。)
初期化関数にはTD誤差を格納するクラス TDerrorMemory のオブジェクト生成処理を追加します。
- 関数 replay では最初にExperience Replay を行い、途中から Prioritized Experience Replayに切り替えます。
- 関数 update_td_error_memory でメモリオブジェクトの保存された全transitionのTD誤差を再計算します。
1 | # エージェントが持つ脳となるクラスです、PrioritizedExperienceReplayを実行します |
棒付き台車を表すAgentクラスを実装します。
- 関数 memorize でメモリオブジェクトに経験したデータ transition を格納します。
- 関数 memorize_td_erro ではそのステップでのTD誤差を格納します。
- 関数 update_td_error_memory は各試行の終わりに実行され TDerrorMemory クラスのオブジェクトに格納されたTD誤差を更新します。
1 | # CartPoleで動くエージェントクラスです、棒付き台車そのものになります |
CartPoleを実行する環境クラスを定義します。
(表形式表現のように離散化は行わず、観測結果 observationをそのままstateとして使用します。)
- 各ステップでのTD誤差をTD誤差メモリに追加します。
- Q_Networkの更新には引数 episode を追加します。(update_q_function関数)
- 各試行の終わりにはTD誤差メモリの中身を更新させます。
1 | # CartPoleを実行する環境のクラスです |
学習を実行します。
1 | # main クラス |
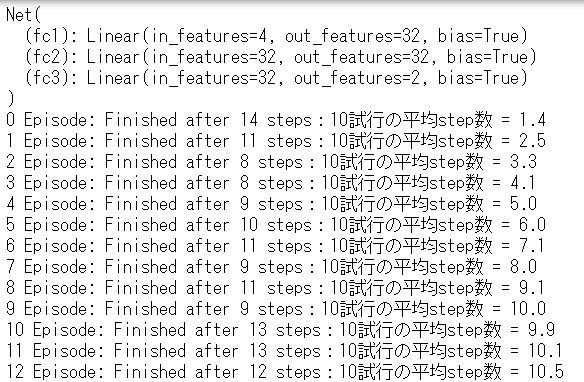
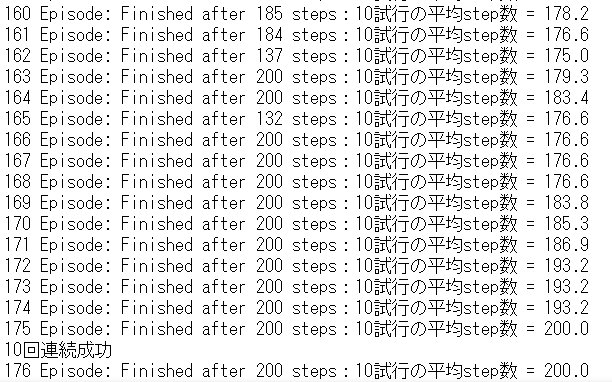
175エピソードで学習が完了しました。
出力された動画ファイル’6_4movie_cartpole_prioritized_experience_replay.mp4’は下記のようになります。
参考 > つくりながら学ぶ!深層強化学習 サポートページ