深層強化学習とは深層学習と強化学習の2つを組み合わせた方法です。
- 深層学習
答えのある問題を学習して分類する問題(画像認識や自動作文)などに用いられます。 - 強化学習
よい状態と悪い状態だけを決めておいてその過程を自動的に学習してよりよい動作を獲得する問題(ロボットのコントロールやゲームの操作)などに用いられます。
深層強化学習とは深層学習と強化学習の2つを組み合わせた方法です。
TesnorBoardはTesorFlowのデータを可視化するツールです。
学習状況をより詳細に観察することができるようになります。
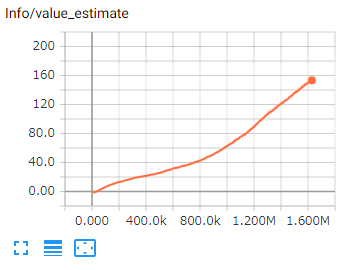
予測する将来の報酬です。
学習成功時には増加し、継続して増加することが期待されます。
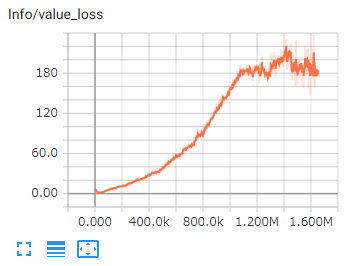
予測する将来の報酬と実際の報酬がどれだけ離れているかを示す値です。
報酬が安定したら、減少することが期待されます。
TesnorBoardはTesorFlowのデータを可視化するツールです。
学習状況をより詳細に観察することができるようになります。
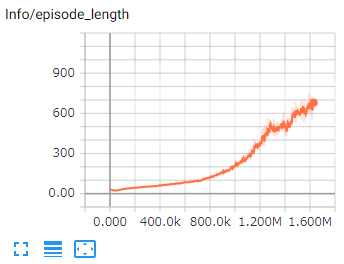
エピソードの平均の長さです。評価する環境によって望まれる結果は異なります。
ボールを落ちないようにする環境では、増加することが期待されます。
迷路を解くようなゲームでは、減少することが期待されます。
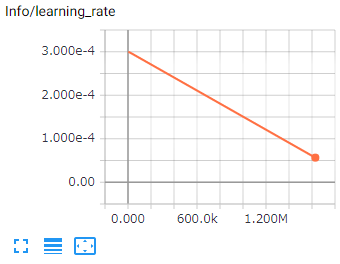
学習率です。今回の行動評価を過去の行動評価と比べてどの程度信じるかという割合になります。
時間とともに継続して減少します。
Brainが行動を決定する「方策がどれだけ変化しているか」を示す値となります。
学習成功時には減少し、継続的に減少することが期待されます。
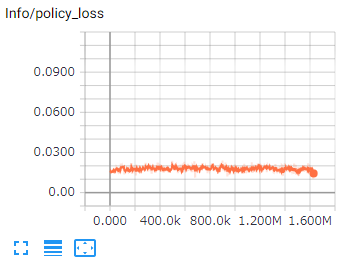
TesnorBoardはTesorFlowのデータを可視化するツールです。
学習状況をより詳細に観察することができるようになります。
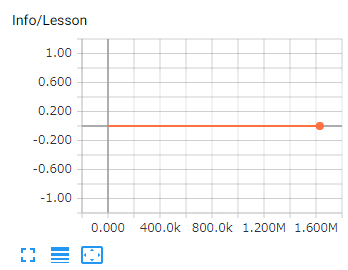
カリキュラム学習のレッスンの進捗です。カリキュラム学習でない場合は、Lesson 0のままとなります。
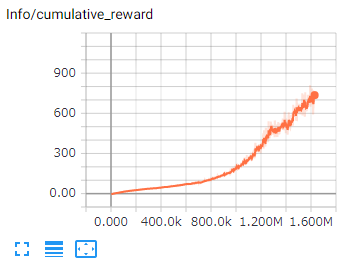
エージェントの平均累積報酬です。継続して増加し、上下の振れ幅が小さいことが期待されます。
タスクの複雑さによってはなかなか増加しないこともあります。
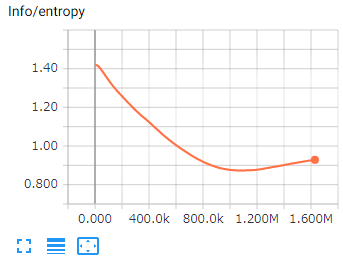
Brainが決定する「Actionがどれだけランダムであるか」を示す値です。
継続的に減少することが期待されます。
Actionのデータ型が離散(Discrete)の場合、次のような対応が有効となります。
Agentが観測した状態に応じて、行動を決定するオブジェクトとなります。
1つのBrainで複数のAgentsの行動を決定することもできます。
Brainには下記の4種類があります。
外部の自作MLライブラリ(Tensorflowなど)を使用します。
学習時に設定されます。
プロジェクトに埋め込まれた推論モデルを使用します。
推論時に設定されます。
プレイヤー(人間)の入力に従って行動します。
学習環境の動作確認時などに利用します。
ルールベース(プログラム)に従って行動します。
Unity ML-Agentsは、Unityで機械学習の学習環境を構築するためのフレームワークです。
Unity ML-Agentsでの2プロセスに関して説明します。
学習用Pythonスクリプトが学習環境となるUnityで強化学習を行います。
学習結果は推論モデルとして保存されます。
学習結果となる推論モデルをつかってUnityで動作します。
推論モデルは与えられたデータから推論結果を導き出すものです。
まだ見たことのない場面に対する好奇心を報酬として学習させる手法です。
ICMでは次の2つのモデルを同時に学習します。
これらによってエージェントにとって未知である行動を取るほど報酬を多く受け取ることになります。
迷路を探索してさまざまな行動をとる必要があるゲーム等に最適な学習方法です。
時系列を扱えるニューラルネットワークです。
強化学習では通常「現在の環境」に応じて行動を決定しますが、RNNを利用することで「過去の環境」の状態も踏まえて行動を決定することができるようになります。
エージェントが記憶を持つようなイメージです。
ただRNNでは長期記憶の学習がうまくできないという問題があるため、次で説明するLSTMで長期記憶ができるように改善します。
長期的な依存関係を学習することのできるRNNの特別な一種で、1つ前の入力データをうまく扱うことに特化した「LSTMブロック」を組み込みます。
多種多様な問題にとてもよく動作し、現在では広く使用されています。
カリキュラム学習はタスクの難易度を徐々に上げていくことにより、効率的な学習を可能にする手法です。
例としましては「足し算・引き算」を学んだあと、「掛け算・引き算」を学び、そのあとで「面積の計算」を学習します。
学んだ知識をその後の学習に生かすことで、より難しい問題を解くことが可能になります。
この手法は機械学習にも適用可能で、簡単なタスクを訓練することでより困難なタスクを達成することを目指します。