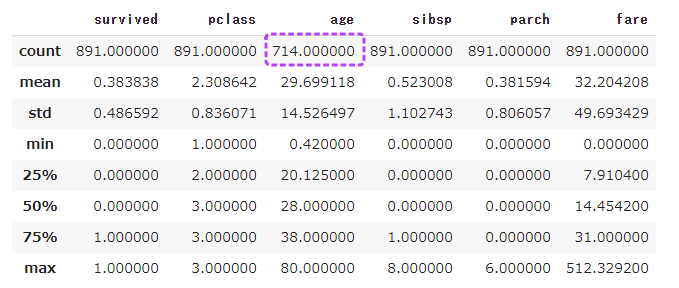
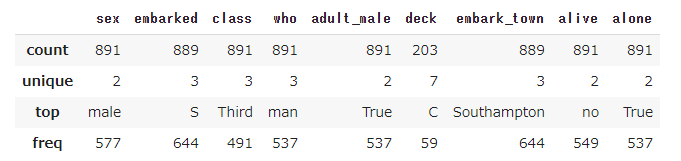
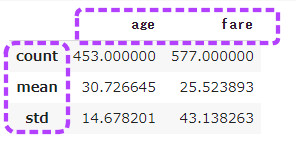
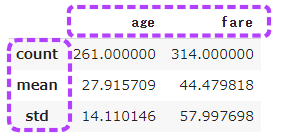
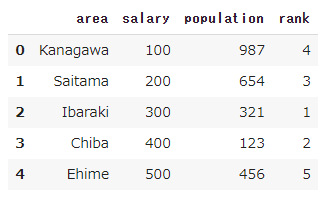
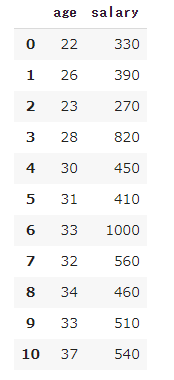
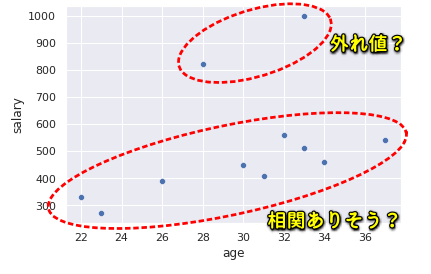
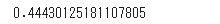import seaborn as sns from matplotlib import pyplot as pyplot sns.set(style='darkgrid') tips = sns.load_dataset('tips') tips
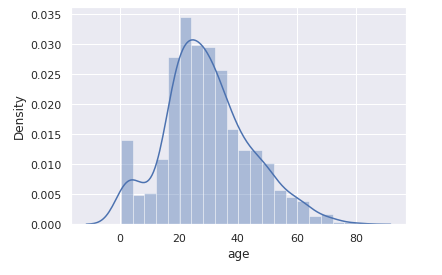
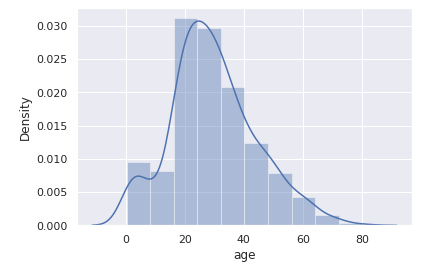
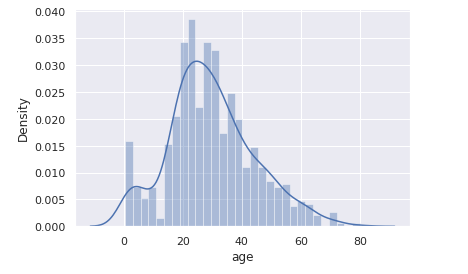
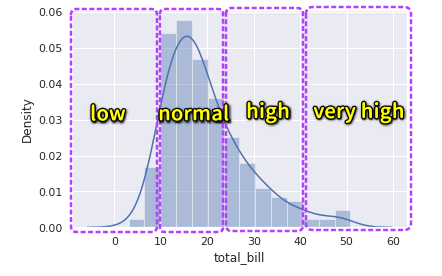
支払い総額(total_bill)をヒストグラムで表示します。
1
sns.distplot(tips.total_bill)
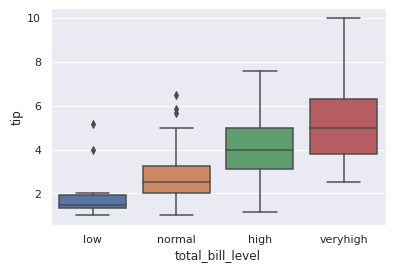
支払い総額(total_bill)を4段階の尺度に分割し、箱ひげ図で表示します。
low (10未満)
normal (10以上25未満)
high (25以上40未満)
very high (40以上)
1 2 3 4 5 6 7 8 9 10 11 12 13
def convert(x): res = 0 if x < 10: res = 'low' elif x < 25: res = 'normal' elif x < 40: res = 'high' else: res = 'veryhigh' return res tips['total_bill_level'] = tips.total_bill.apply(convert) sns.boxplot(data=tips.sort_values('tip'), x='total_bill_level', y='tip')