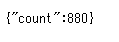GASを使って、GoogleSpreadSheetのデータ参照を行ってみます。
スプレッドシートのデータ構造
GoogleSpreadSheetは、3つのデータ構造に分けることができます。
- SpreadSheet
1つのスプレッドシート・ファイルのこと。
複数のシートを持ちます。 - Sheet
SpreadSheet内にあるシートのこと。 - Range
Sheet内にあるマス目の集合のこと。
一般的な表形式と同じ概念なので理解しやすいかと思います。
データ参照
データ参照を行うソースは以下の通りです。
[Google Apps Script]
1 | function main() { |
- 2行目
操作するスプレッドシートのIDを設定します。
スプレッドシートIDは、ブラウザでスプレッドシートを開いたときのURLの“spreadsheets/d/“の後ろから“/edit”の前の文字列です。 - 7行目
1つのセルのデータを取得します。
getRange関数でセル位置を指定し、getValue()関数をデータを取得しています。 - 10行目
複数のセルデータを取得します。
1行目から3行目、1列目から3列目のデータをgetValues()関数を使ってまとめて取得し、配列に格納しています。
複数のデータを参照したい場合は、まとめて取得したほうが処理が高速になります。