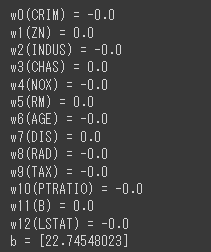
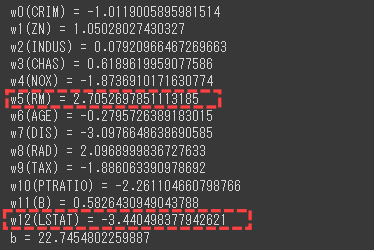
前回構築した決定木モデルの評価を行います。
予測値算出
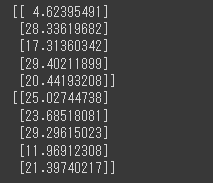
まずは予測値を算出します。
[Google Colaboratory]
1 | y_train_pred = tree_reg.predict(X_train) |
[実行結果]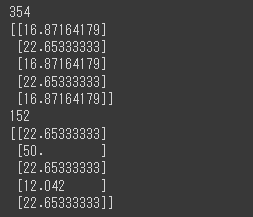
可視化
散布図で予測値を可視化します。
[Google Colaboratory]
1 | plt.scatter(y_train_pred, y_train, label="train") |
[実行結果]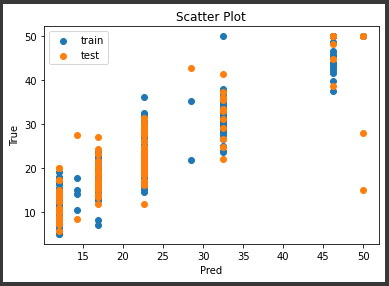
線形回帰とは異なる分布になっています。
グラフからは、何種類かの特定の値が予測値として出力されているようです。
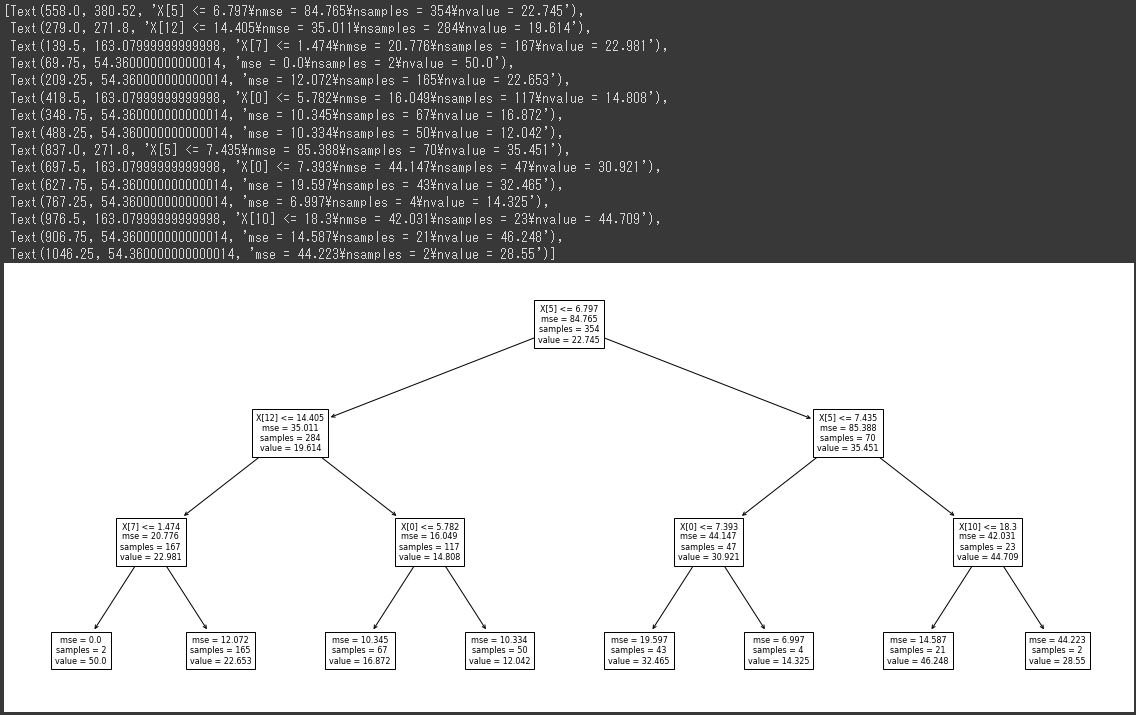
予測値として出力される値のパターンはリーフノードの数に依存します。
前回出力した樹形図のリーフノード数は8個だったので、予測値のパターンも8種類ということになります。
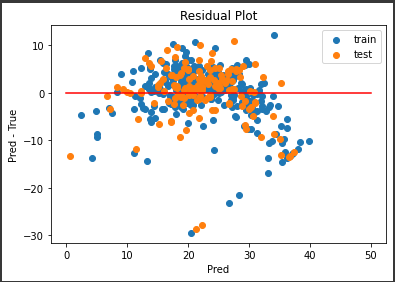
残差プロット
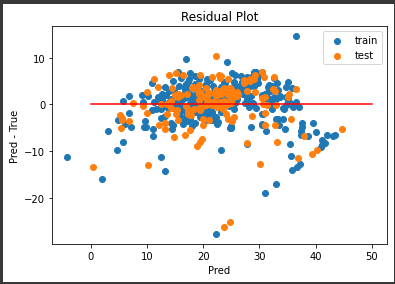
次に実測値と予測値の誤差をプロットしてみます。
[Google Colaboratory]
1 | def residual_plot(y_train_pred, y_train, y_test_pred, y_test): |
[実行結果]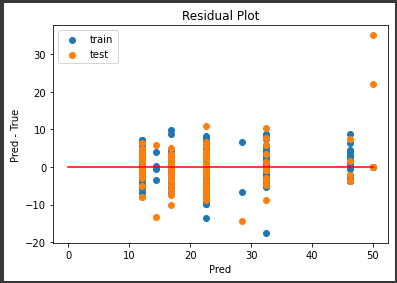
右側に外れ値がいくつかありますが、誤差の範囲が±10程度と、まずまずの結果となっていると思います。
精度評価スコア
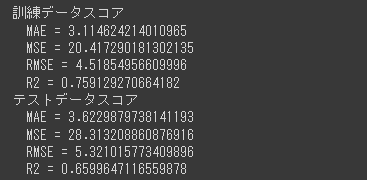
精度評価スコアを算出します。
[Google Colaboratory]
1 | from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score |
[実行結果]
R2スコアが0.66であり、十分な精度となっていません。
次回は、ハイパーパラメータの設定で決定木の深さを変更し、スコアの向上を図ります。