グリッドサーチ
XgBoostには、10種類を超えるハイパーパラメータがあります。
最適なパラメータの探索を効率的に行う手法として、グリッドサーチがあります。
グリッドサーチとは、あらかじめパラメータの候補値を定義しておき、それら候補値の組み合わせを全通り検証し、最も良い評価結果を出した組み合わせがどれだったのかを調べる手法です。
グリッドサーチ用のモデル構築
グリッドサーチを行うには、scikit-learnのGridSearchCVクラスを使用します。
GridSearchCVクラスは、ハイパーパラメータのそれぞれの組み合わせを交差検証法で評価し、最も評価の高かった組み合わせでモデルを学習してくれるクラスです。
[Google Colaboratory]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| xgb_reg_grid = xgb.XGBRegressor()
from sklearn.model_selection import GridSearchCV
params = {"booster": ["gbtree"],
"n_estimators":[10,30,50,100],
"max_depth":[2, 3, 4, 5, 6],
"learning_rate":[0.1,0.25,0.5,0.75,1.0],
"colsample_bytree":[0.1,0.25, 0,5, 0.75, 1.0],
"random_state":[0]}
k_fold = KFold(n_splits=5, shuffle=True, random_state=0)
grid = GridSearchCV(estimator=xgb_reg_grid,param_grid=params,cv=k_fold,scoring="r2")
grid.fit(X_train,y_train)
|
指定したXgBoostのパラメータの意味は以下の通りです。(4~9行目)
- booster
決定木系モデルか線形モデルのどちらかを指定する。
- n_estimators
生成する決定木の数。
ランダムフォレストでは決定木の数を増やして平均をとるので精度面に影響はなかったが、XgBoostの場合は決定木の数を増やすほどモデルが複雑になり過学習のリスクが高まるので注意。
- max_depth
決定木の層の最大の深さ。
- learning_rate
学習率。
以前の決定木の誤りをどれだけ強く補正するかを指定する。
補正を強くしすぎるとモデルが複雑になり、過学習のリスクが高まる。
- colsample_bytree
各決定木で使用する説明変数の割合。
1未満に指定すると、その割合だけランダムに選択された説明変数を使用する。
指定したGridSearchCVのパラメータの意味は以下の通りです。(12行目)
- estimator
検証で使用するモデル。
- param_grid
パラメータ名と値の一覧。
- cv
交差検証でのデータセットの分割方法
- scoring
評価手法。
定義したgridにデータをfitすることで、グリッドサーチが開始されます。(13行目)
[実行結果(一部)]
ハイパーパラメータの全組み合わせ × 交差検証の分割数だけ学習・評価が行われるため、計算に時間がかかります。
グリッドサーチの結果
どの組み合わせが最適だったのか、結果を確認します。
最も評価が高かった組み合わせとそのスコアを出力します。
[Google Colaboratory]
1
2
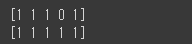
| print(grid.best_params_)
print(grid.best_score_)
|
[実行結果]

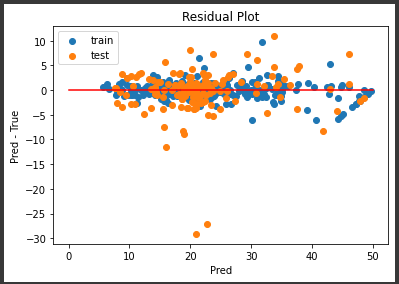
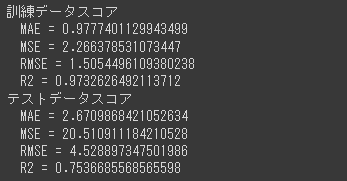
交差検証でのスコアが0.89ととても良い評価となりました。
テストデータでの評価
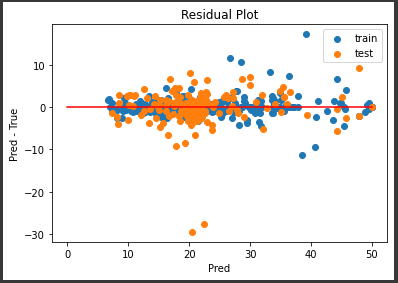
最後に、テストデータを使った評価を行います。
[Google Colaboratory]
1
2
3
4
5
| y_test_pred = grid.predict(X_test)
y_test_pred = np.expand_dims(y_test_pred, 1)
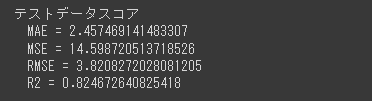
print("テストデータスコア")
get_eval_score(y_test,y_test_pred)
|
[実行結果]
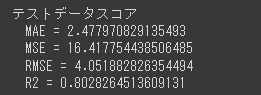
R2スコアが0.8以上となっており、こちらもかなりよい結果です。
今回は実質4種類のパラメータの最適な組み合わせを調べましたが、XgBoostにはこの他にも多くのハイパーパラメータがあります。
それぞれのパラメータの意味を確認し、グリッドサーチを試してみることでよりよい結果にすることができるかもしれません。