回帰でも分類でも教師あり学習には正解データがあるため、定量的な評価を行うことができます。
基本的な評価指標を確認し、それぞれの指標の特徴や違いを確認していきます。
評価対象のモデルの準備
データセットと評価対象となるモデルを準備します。
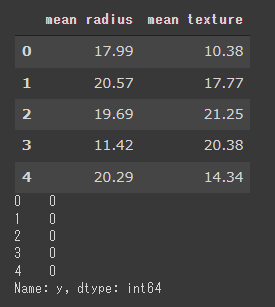
まず、乳がんの診断データを読み込みデータフレームに格納します。
[Google Colaboratory]
1 | from sklearn.datasets import load_breast_cancer |
説明変数と目的変数に分け、さらに訓練データとテストデータ(7:3の割合)に分割します。
[Google Colaboratory]
1 | from sklearn.model_selection import train_test_split |
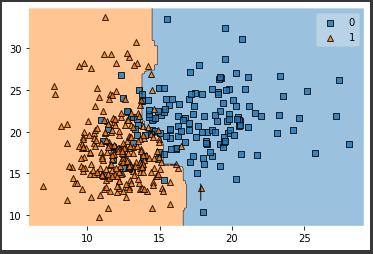
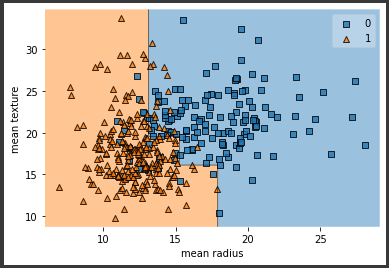
評価対象となるランダムフォレストモデルを作成し、学習を行います。(2行目)
また予測値の算出も行います。(4~5行目)
[Google Colaboratory]
1 | from sklearn.ensemble import RandomForestClassifier |
以上でモデルの構築は完了です。
正解率
正解率は、サンプルの総数に対して何件予測を的中させたかを示すシンプルな指標です。
scikit-learnのaccuracy_scoreに実測値と予測値を渡すと、正解率を算出することができます。
[Google Colaboratory]
1 | from sklearn.metrics import accuracy_score |
[実行結果]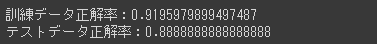
訓練データにだけ過度に適合しているということもなく、両データとも比較的高いスコアを出しており、過学習や学習不足の心配はなさそうです。
ただ正解率では、カテゴリごとの予測精度をみることができないため、より深い精度評価が必要になります。
混同行列
混同行列は、真陽性・偽陽性・真陰性・偽陽性のそれぞれのサンプル件数を可視化したマトリックス表です。
- 真陽性(TP:True Positive)
実際に陽性で正しく陽性と予測されたサンプル - 偽陽性(FP:False Posotove)
実際には陽性だが陰性と予測されたサンプル - 真陰性(TN:True Negative)
実際に陰性で正しく陰性と予測されたサンプル - 偽陽性(FN:False Negative)
実際には陰性だが陽性と予測されたサンプル
混同行列を算出するためにはscikit-learnのconfusion_matrixを使用します。(5行目)
視覚的に把握しやすくするためヒートマップで結果を表示します。(7~10行目)
[Google Colaboratory]
1 | from sklearn.metrics import confusion_matrix |
混同行列を可視化することで、個別のカテゴリごとの予測精度を俯瞰してみることができ、どの部分での予測が弱いのかなども含めて直感的に把握することができます。
混同行列は多値分類でも使用することができ、カテゴリ数が多くなればなるほど視覚に訴える混同行列のメリットを享受することができます。
[実行結果]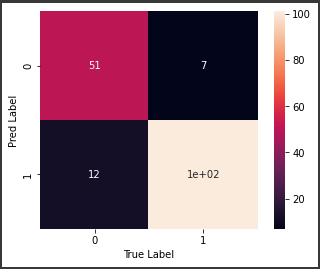
ヒートマップから、おおむね正しく予測できているようです。
ただ陽性サンプル数63件に対して、偽陽性が12と少し多いのが気になります。
このように混同行列はモデル精度の概観を確認するのに役立ちますが、モデルの改善やモデルの構築目的にあった評価を行うには、混同行列で算出した結果を別の方法で解釈する必要があります。