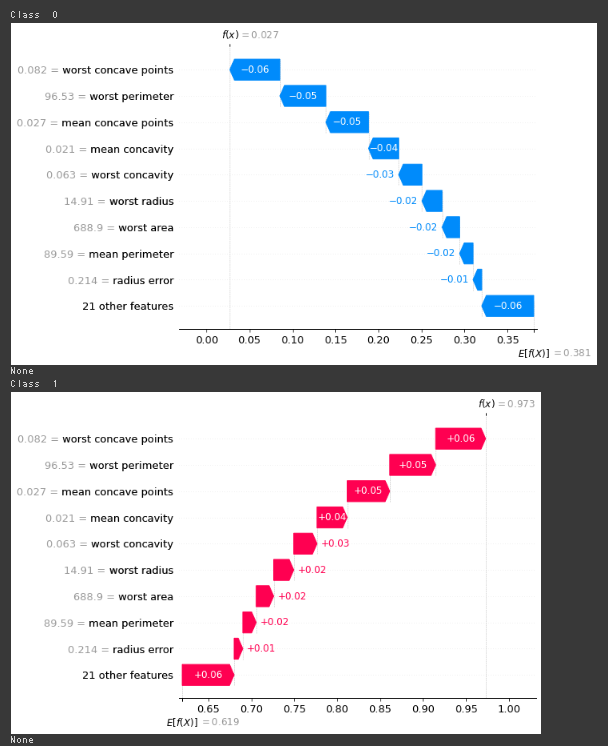
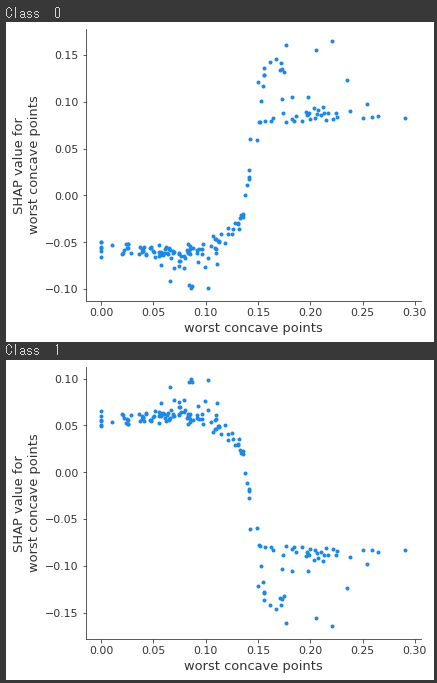
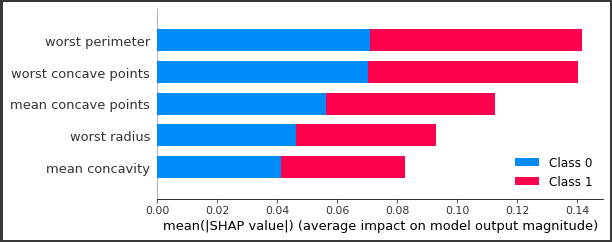
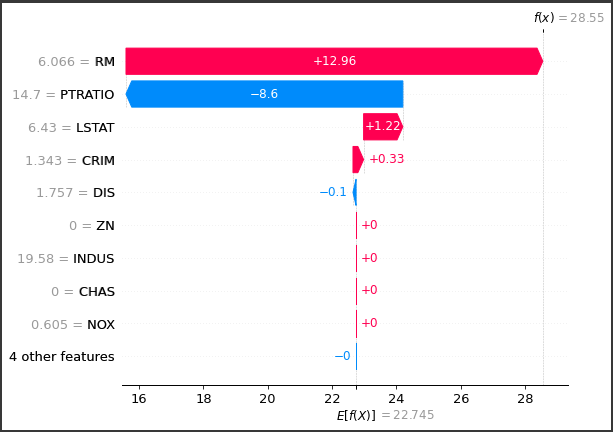
PyCaretで前処理
PyCaret で前処理を行います。
setup関数 を使うと、データを分析し、必要な前処理を自動的に行ってくれます。(2~5行目)
引数の意味は下記の通りです。
第1引数
第2引数(target)
第3引数(normalize)
第4引数(session_id)
[Google Colaboratory]
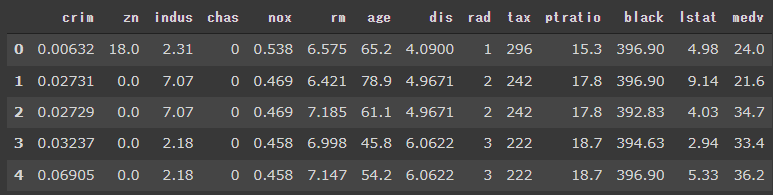
1 2 3 4 5 from pycaret.regression import *ret = setup(boston_data, target = "medv" , normalize = False , session_id=0 )
[実行結果]
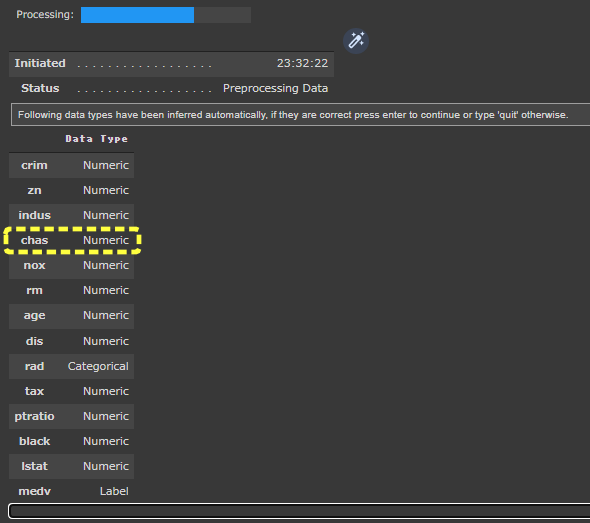
setup関数 を実行すると、PyCaretは各変数の型 を推定して、ダイアログを表示してユーザに推定結果の確認と処理の続行を促します。
型の推定結果が正しければ、ダイアログのエディットボックスでEnterキーを押下すうことで処理が続行されます。
指定された型がおかしな場合は、quit と入力することで処理を中断できます。
型の変更
chas列 は、Categorical と認識されていますがNumberic として扱うように変更してみます。
[Google Colaboratory]
1 2 3 4 5 6 from pycaret.regression import *ret = setup(boston_data, target = "medv" , session_id=0 , normalize = False , numeric_features = ["chas" ])
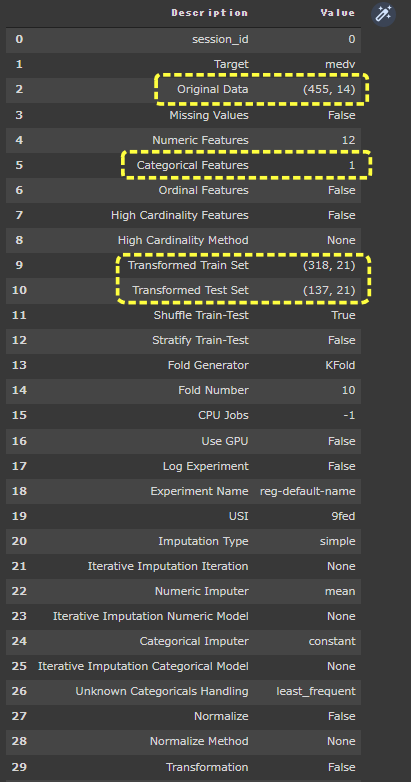
numeric_features に“chas” を指定して実行しています。(6行目)
[実行結果]
“chas” の型がNumeric に変更されているのが確認できます。
setupダイアログの前処理結果を確認
ダイアログのエディットボックス上でEnterキーを押下して処理を完了すると、setupダイアログに前処理の結果が表示されます。
[実行結果]
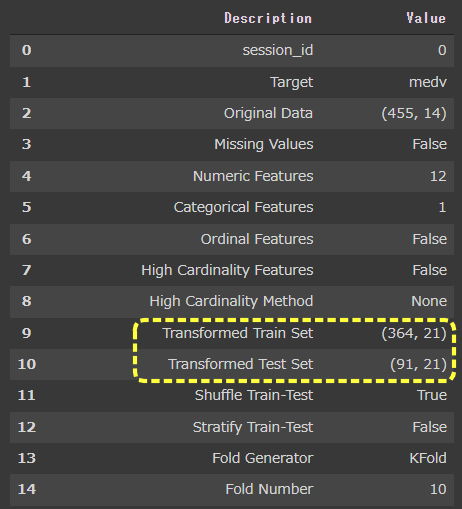
setup では欠損値処理、データの分割(train_test_split)などを実施しており、完了すると結果が表示されます。
この表から、データサイズや説明変数の数や、各種前処理の指定有無などを確認することができます。
Missing Values 欠損値 がある場合、Trueが表示されます。Transformed Train Set / Transformed Test Set Oriinal Data )の説明変数は14ですが、21に増えています。Categoria Features が1となっており、1つの説明変数がカテゴリ変数に変換されたことが分かります。
このようにPyCaretは加工を含む前処理を自動で実施してくれるのです。