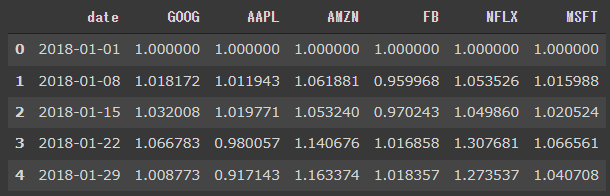
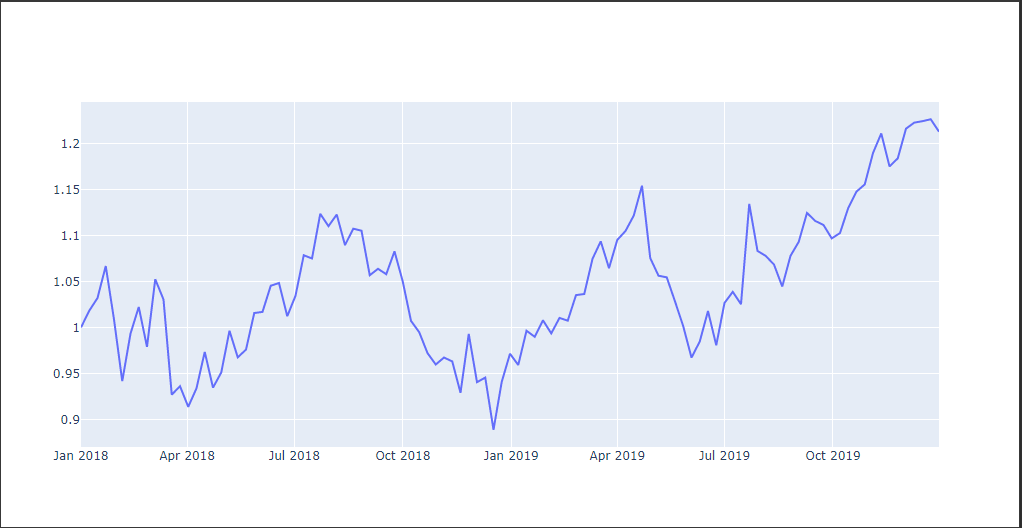
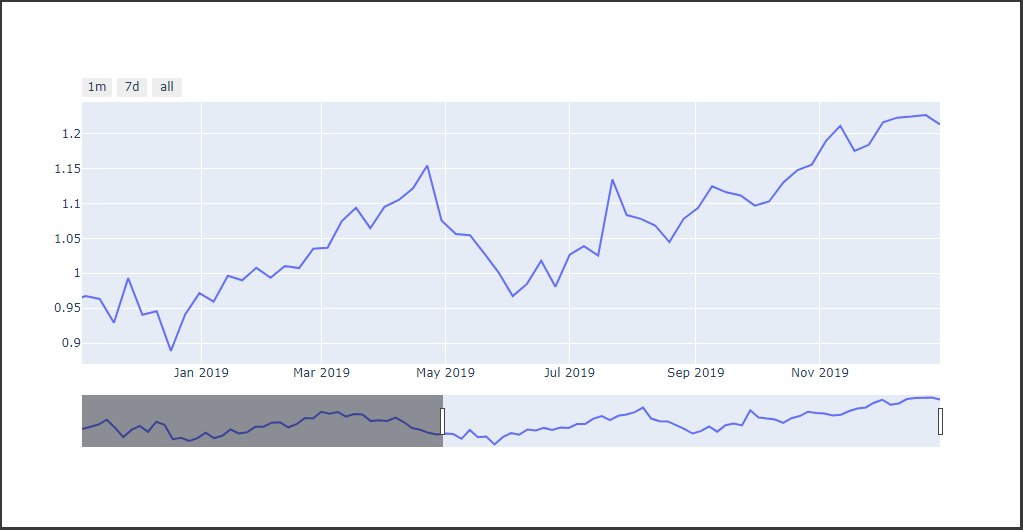
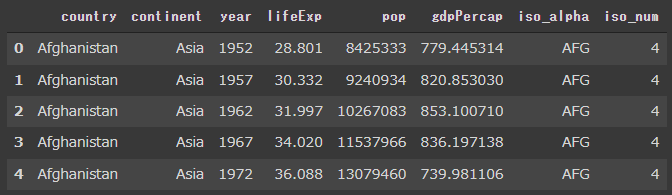
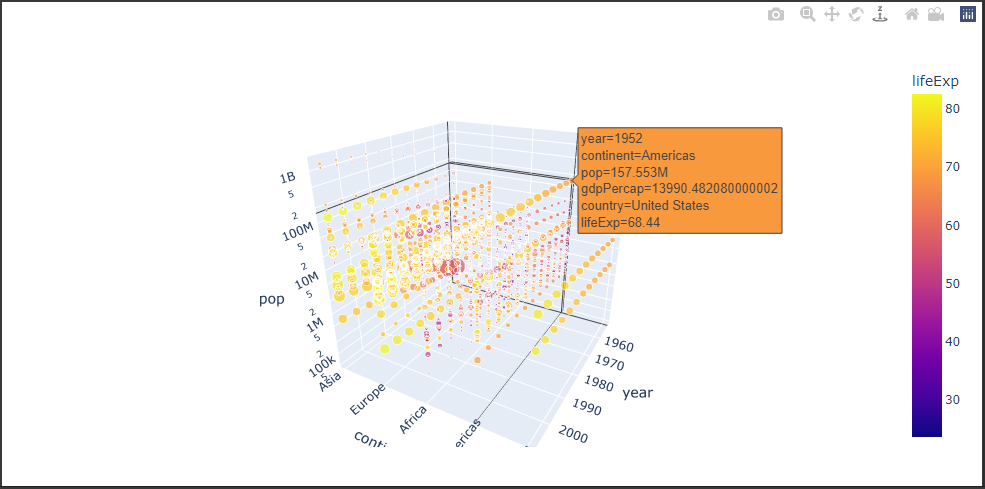
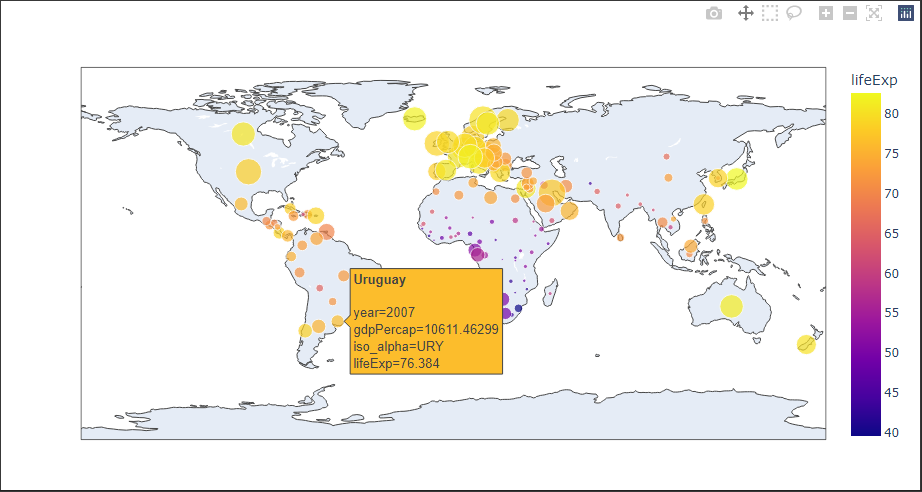
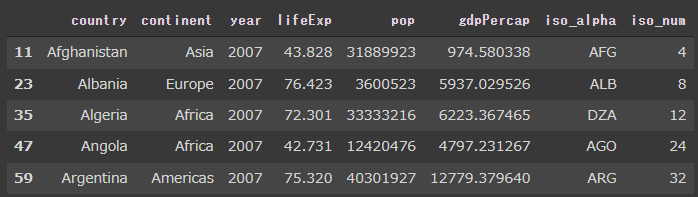
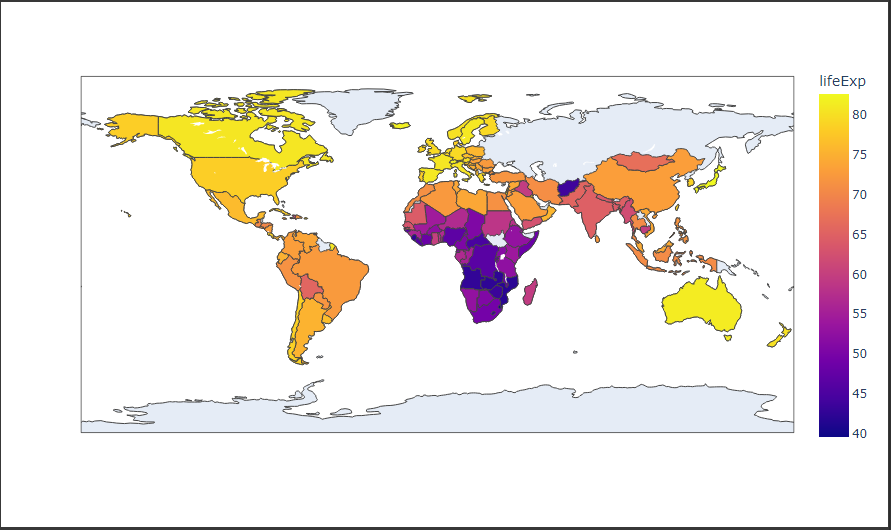
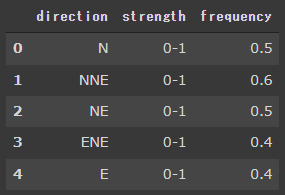
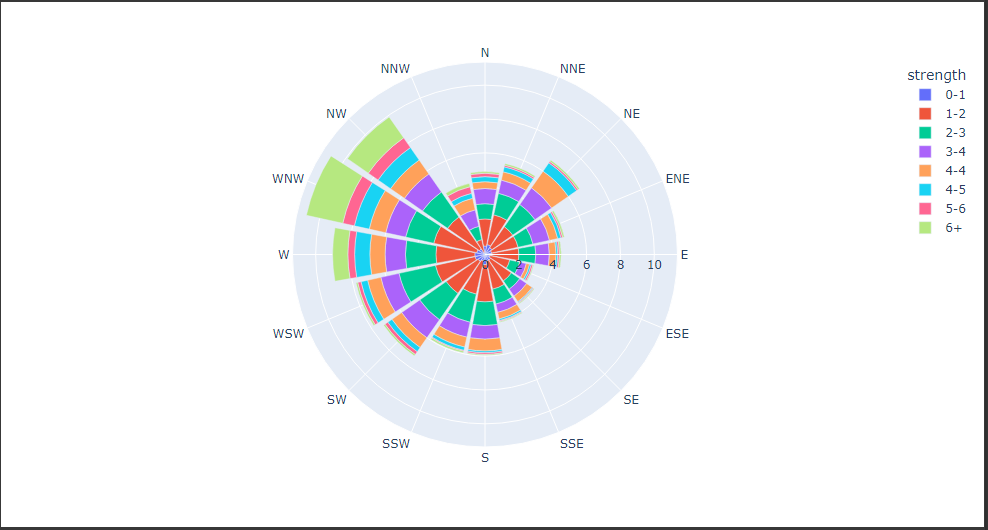
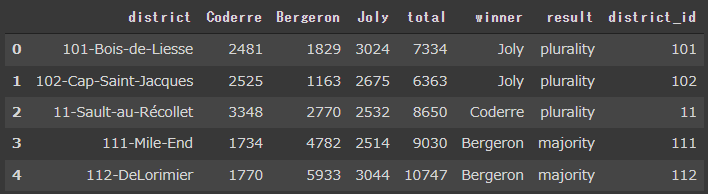
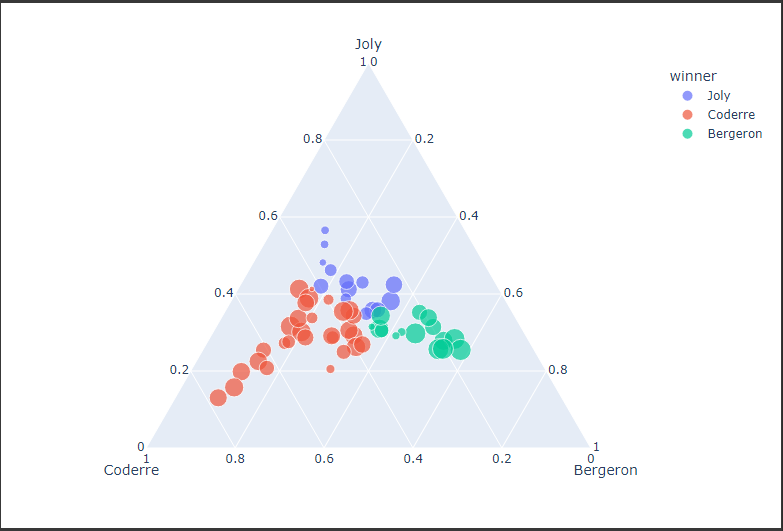
棒グラフ
棒グラフを表示するにはBarクラスを使用します。
引数 orientationに“h”を渡すと横向きの棒グラフになります。(14行目)
[Google Colaboratory]
1 | import plotly.graph_objects as go |
[実行結果]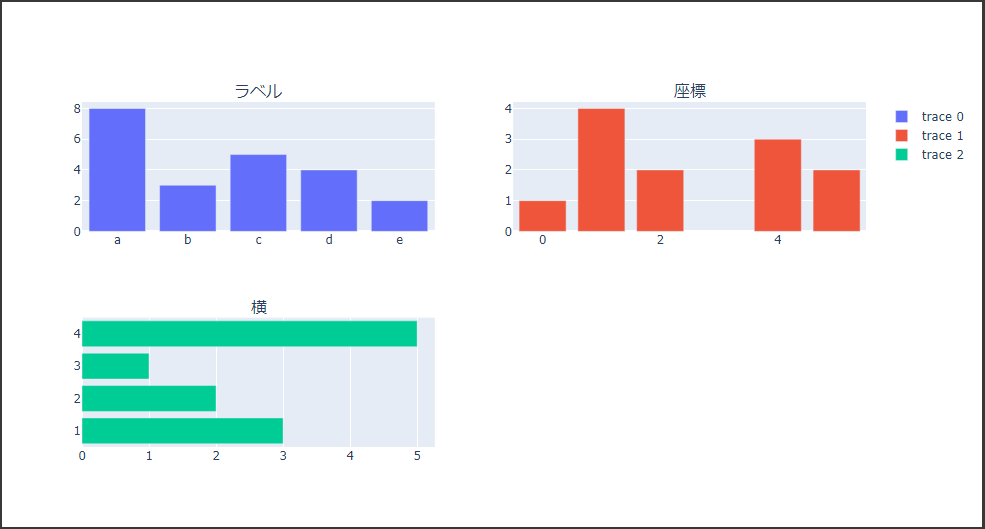
棒グラフ(グループ化)
Figure関数に複数のBar traceを渡すと、グループ化した棒グラフを描画することができます。
[Google Colaboratory]
1 | bar_trace1 = go.Bar(x=["a", "b", "c", "d", "e"], y=[3, 5, 2, 1, 6], name="group1") |
[実行結果]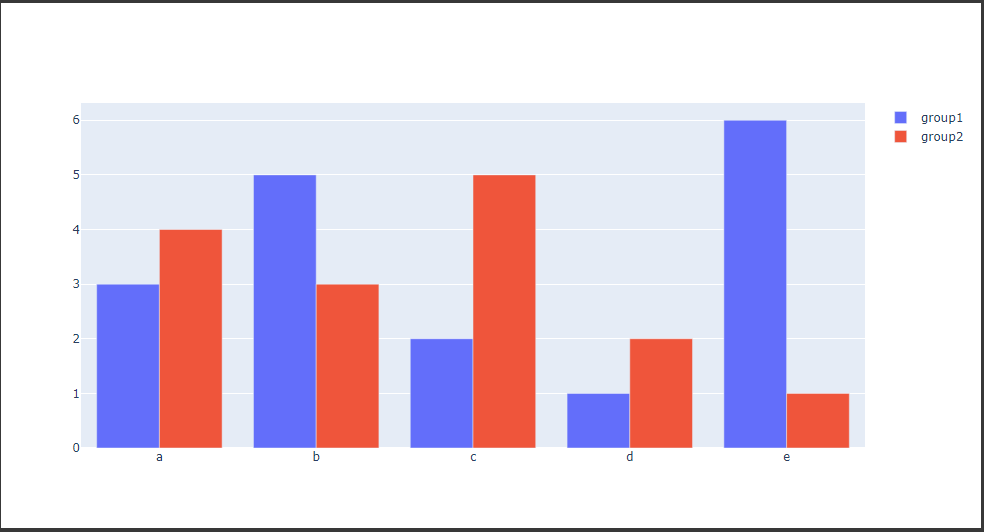
棒グラフ(積み上げ)
Layoutクラスの引数 barmodeに“stack”を渡すと、積み上げ棒グラフを描画することができます。(3行目)
[Google Colaboratory]
1 | stacked_fig = go.Figure( |
[実行結果]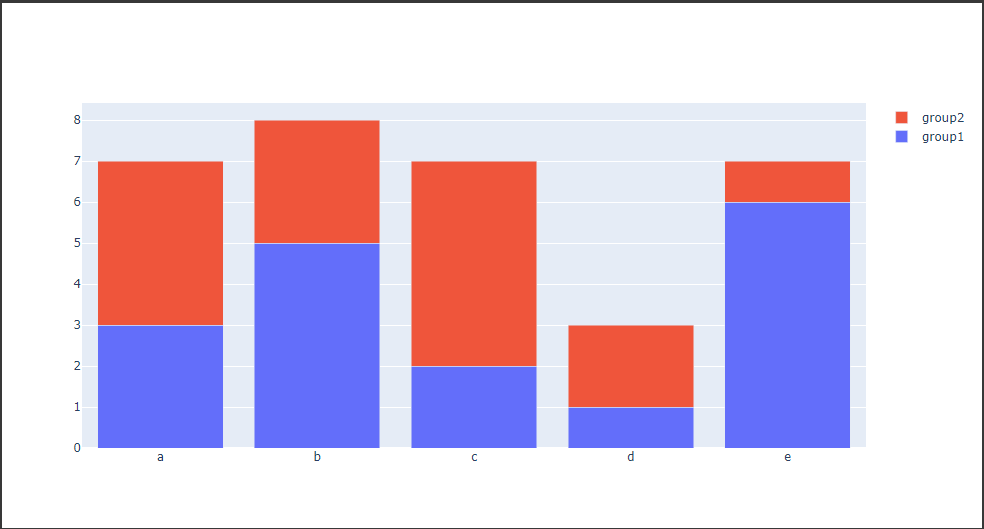
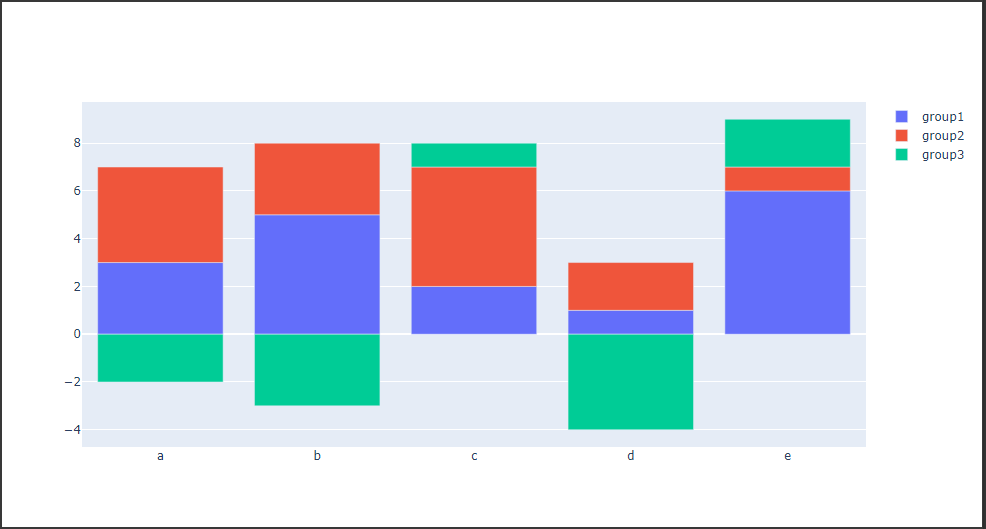
棒グラフ(マイナス方向に積み上げ)
Layoutクラスの引数 barmodeに“relative”を渡すと、値が0未満の要素を下方向に積み上げて表示することができます。(4行目)
[Google Colaboratory]
1 | bar_trace3 = go.Bar(x=["a", "b", "c", "d", "e"], y=[-2, -3, 1, -4, 2], name="group3") |
[実行結果]