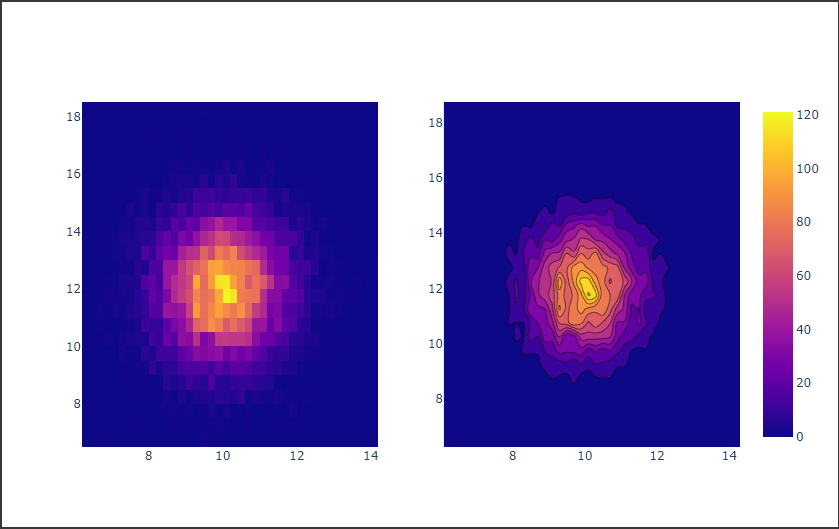
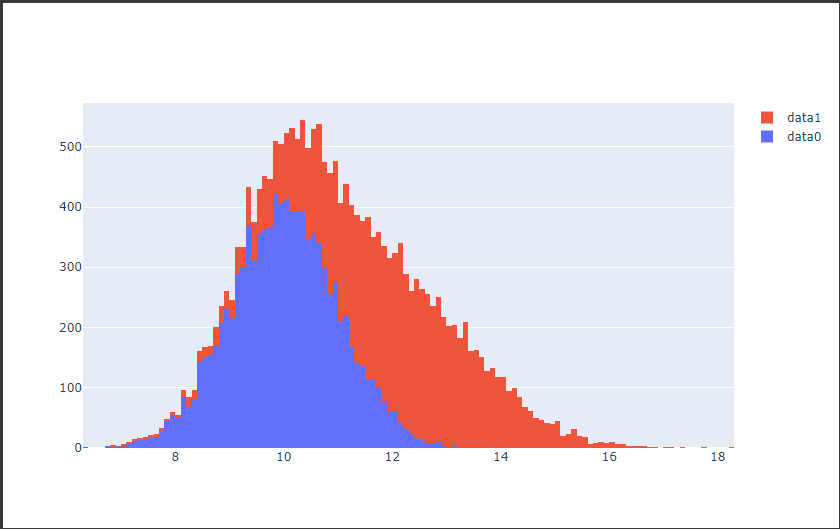
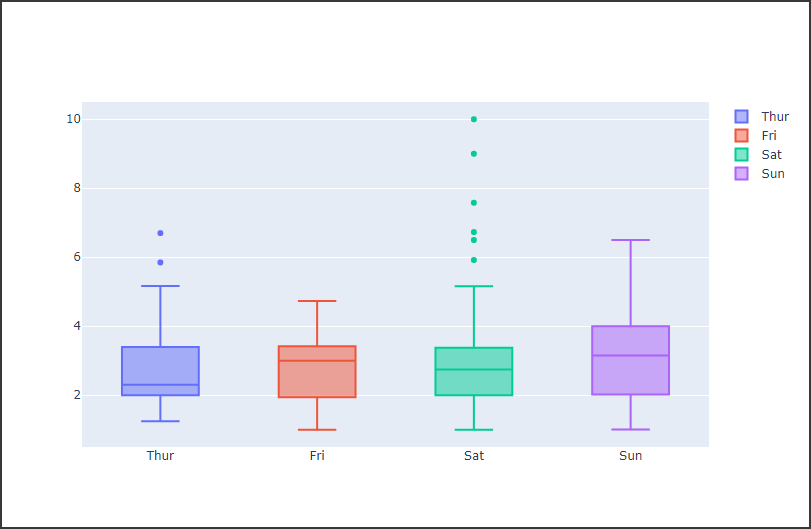
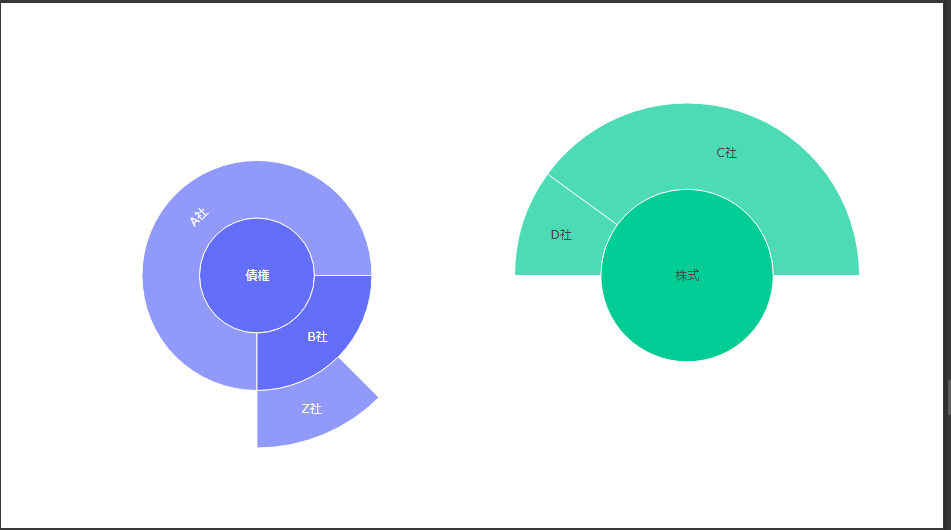
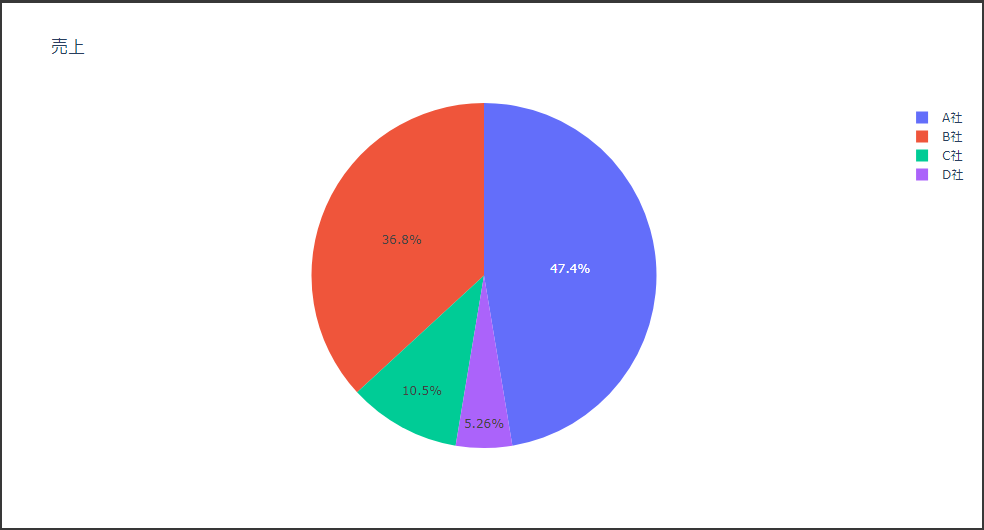
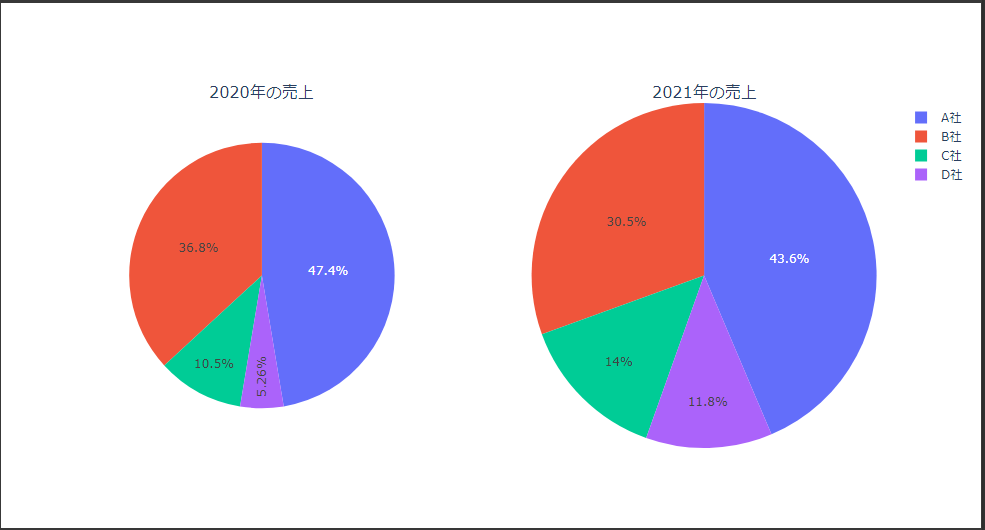
2次元ヒストグラムは2変数を2次元の座標にとり、2変数の値の組み合わせの頻度をカラースケールで表現します。
2次元ヒストグラム
Plotlyで2次元ヒストグラムを描画するにはHistogram2dクラスを使用します。
Histogram2dクラスの引数 x, yにはリストなどのデータを設定します。
2次元ヒストグラムの同じ度数を等高線で描画するにはHistogram2dContour traceを使用します。
Histogram2dContourクラスはHistogram2dクラスと同様の引数を使います。
以下のコードでは2つの正規分布に従う乱数を作成し、左図のサブプロットには2次元ヒストグラムを描画し、右図のサブプロットには等高線の2次元ヒストグラムを描画しています。
[Google Colaboratory]
1 | import numpy as np |
[実行結果]