1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
| import json
import dash
import dash_core_components as dcc
import dash_html_components as html
import plotly.express as px
from dash.dependencies import Input, Output, State
tips = px.data.tips()
app = dash.Dash(__name__)
app.layout = html.Div(
[
html.H1(id='title1'),
html.Div(
[
dcc.Dropdown(
id='dropdown1',
options=[
{'value':'bar', 'label':'棒グラフ'},
{'value':'scatter', 'label':'散布図'}
],
value='bar'
),
html.Div(
[
html.P(id='title2'),
dcc.RadioItems(id='radio1')
]
)
],
style={'width':'35%', 'float':'left'}
),
html.Div(
[dcc.Graph(id='graph1')],
style={'width':'65%', 'height':800, 'display':'inline-block'}
)
]
)
@app.callback(
Output('radio1', 'options'),
Output('radio1', 'value'),
Output('title1', 'children'),
Output('title2', 'children'),
Input('dropdown1', 'value')
)
def update_selecter(dropdown1):
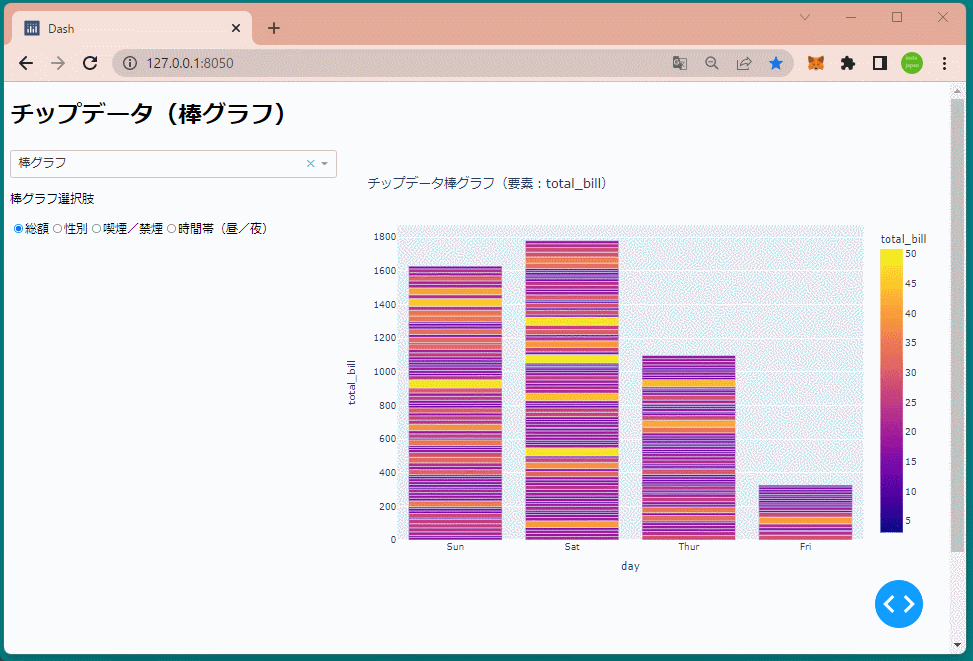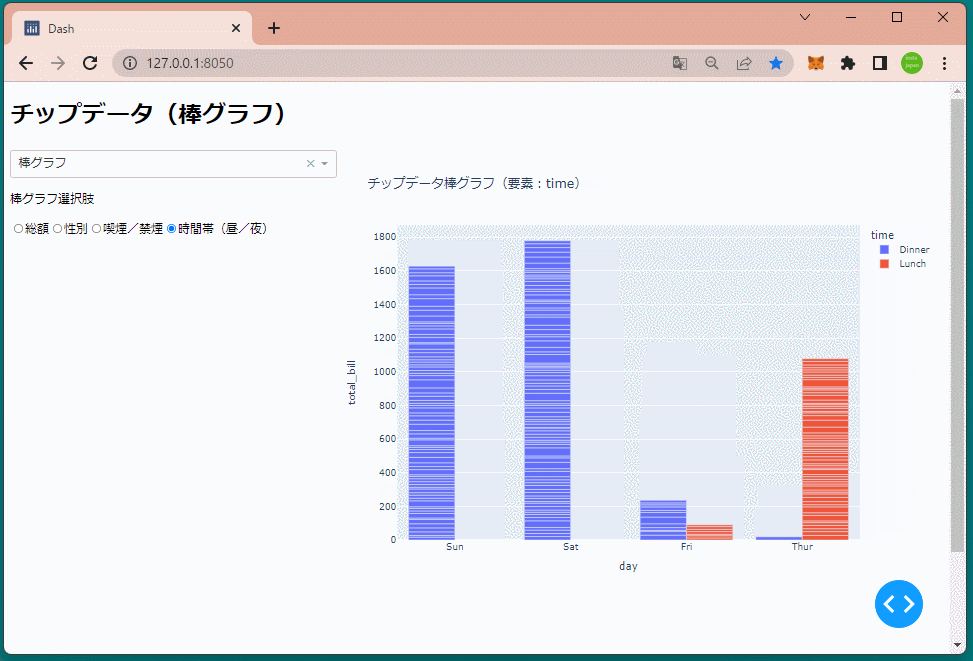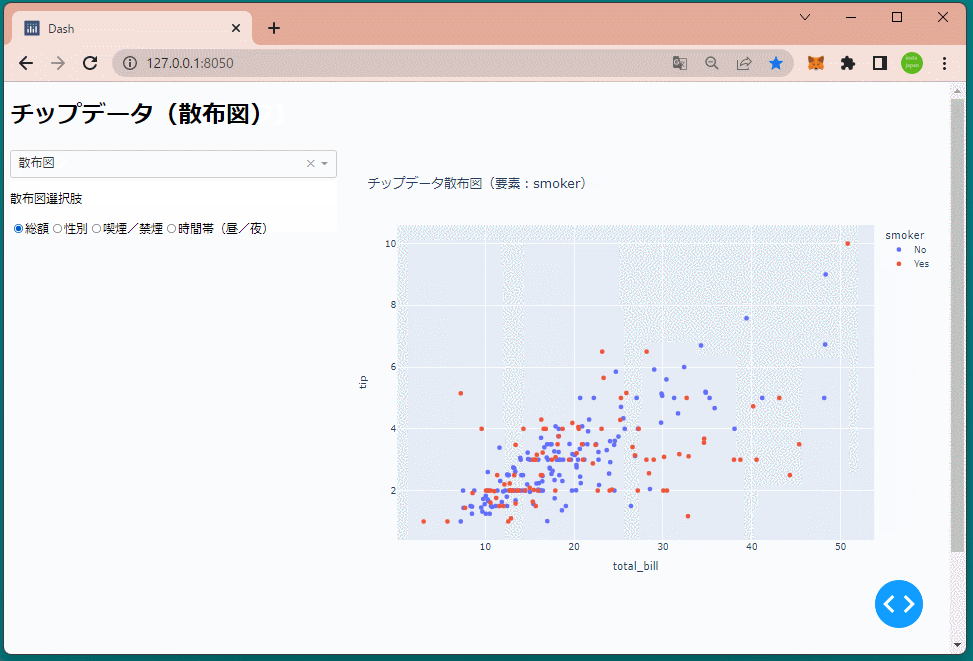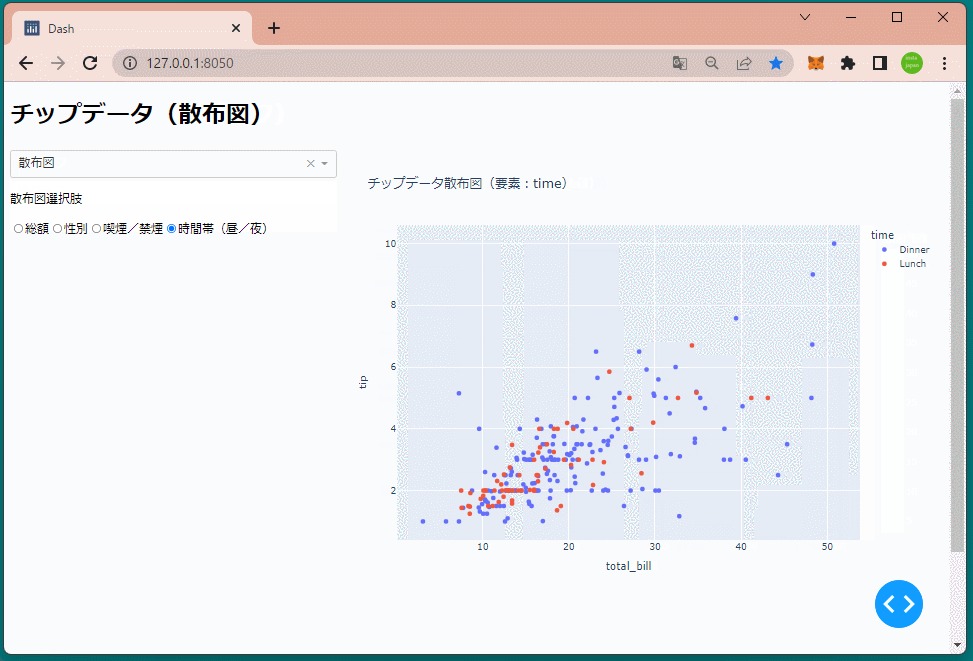
if dropdown1 == 'bar':
return (
[
{'value':'total_bill', 'label':'総額'},
{'value':'sex', 'label':'性別'},
{'value':'smoker', 'label':'喫煙/禁煙'},
{'value':'time', 'label':'時間帯(昼/夜)'}
],
'total_bill',
'チップデータ(棒グラフ)',
'棒グラフ選択肢'
)
else:
return (
[
{'value':'total_bill', 'label':'総額'},
{'value':'sex', 'label':'性別'},
{'value':'smoker', 'label':'喫煙/禁煙'},
{'value':'time', 'label':'時間帯(昼/夜)'}
],
'smoker',
'チップデータ(散布図)',
'散布図選択肢'
)
@app.callback(
Output('graph1', 'figure'),
Input('radio1', 'value'),
State('dropdown1', 'value')
)
def update_graph(radio1, dropdown1):
if dropdown1 == 'bar':
return px.bar(
tips,
x='day',
y='total_bill',
color=radio1,
barmode='group',
height=600,
title='チップデータ棒グラフ(要素:{})'.format(radio1)
)
else:
return px.scatter(
tips,
x='total_bill',
y='tip',
color=radio1,
height=600,
title='チップデータ散布図(要素:{})'.format(radio1)
)
if __name__ == '__main__':
app.run_server(debug=True)
|